Kimi K2.7接入Hermes Agent实测:一句话生成完整应用
Kimi K2.7 + Hermes Agent:AI编程的新组合
月之暗面最新发布的 Kimi K2.7 编程模型,被迅速接入了 Hermes Agent 智能体操作系统。据B站UP主的实测演示,这套组合能够实现"一句话描述需求,自动生成完整应用并修复BUG"的工作流程。整个过程无需手动干预,AI团队协作完成从代码编写到自我评估的全流程。
Kimi K2.7 的核心参数令人瞩目:3亿参数的混合专家模型(MoE),256K Token 上下文窗口,专为长文本编程任务打造。混合专家模型(Mixture of Experts)是一种稀疏激活的神经网络架构——与传统密集模型每次推理都激活所有参数不同,MoE模型包含多个"专家"子网络和一个路由机制,每次推理只选择部分专家处理输入,其余保持休眠。这意味着虽然总参数量巨大,但实际激活的参数远少于此,在保持强大能力的同时大幅降低计算成本。Google的Switch Transformer和Mistral的Mixtral都采用了类似架构。
而256K Token的上下文窗口,意味着模型单次对话可以处理约相当于一本中等篇幅小说的文本量。对于编程场景,这意味着模型可以同时"看到"一个大型项目的数十个代码文件、理解它们之间的依赖关系,而不需要将项目拆分成碎片逐一处理。相比之下,早期GPT-3.5仅支持4K Token,Claude 3.5支持200K Token。
更关键的是,K2.7比前代 K2.6 少用 30% 的思考 Token,但在编码基准测试中得分更高——用更少的资源干更多的活。在具备"思维链"能力的模型中,"思考Token"指模型在给出最终答案前用于内部推理的Token消耗。这些Token虽然用户不一定看到,但会消耗计算资源和时间,并计入API调用费用。少用30%的思考Token意味着模型学会了更高效地"思考",减少了冗余推理步骤,直接转化为更低的使用成本和更快的响应速度。
实测效果:从3D游戏到网页操作系统
一句话生成3D RPG游戏
在演示中,UP主展示了用 Kimi K2.7 创建的多个项目。其中最令人印象深刻的是一款类似上古卷轴风格的3D RPG游戏,玩家可以在其中自由探索。这并非一次性指令生成,而是模型在长程任务中持续迭代、自我修正的结果。
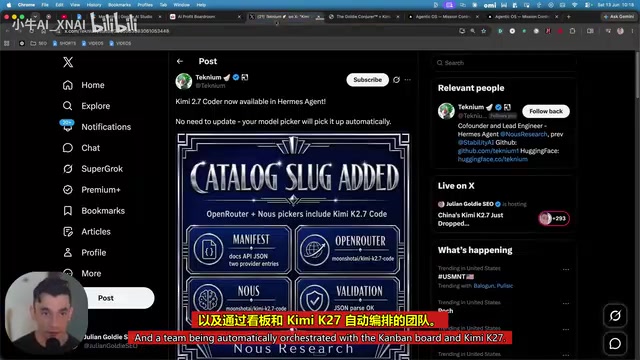
完整网页操作系统的构建
更惊人的案例是一个完整的网页操作系统。Kimi K2.7 在系统内创建了多种应用:笔记应用(关闭后重新打开数据仍在)、计算器、画图工具、时钟(时间还挺准),而且支持多应用同时运行。这展示了模型处理复杂、多模块项目的能力。
19分钟完成一条完整视频
整个演示视频本身就是用 Kimi K2.7 + Hermes Agent 团队制作的。AI数字人由 Hermes 和黑战生成,剪辑设计由 Kimi K2.7 完成,音乐配音通过 Kimi K2.7 配合 API 搞定。整个团队只花了约19分钟就完成了一条完整剪辑的视频。
智能体团队协作机制解析
看板驱动的任务自动分配
这套系统的核心架构是:Kimi K2.7 作为"大脑",Hermes Agent 作为"手脚"来执行操作。这里需要理解智能体(Agent)与传统AI助手的根本区别:传统AI助手采用"一问一答"模式,用户提问,模型回答,交互结束。而智能体具备自主规划、工具调用和持续执行的能力——它可以将复杂目标分解为子任务、调用外部工具(如浏览器、代码执行器、文件系统)、观察执行结果、根据反馈调整策略,并循环这一过程直到目标完成。Hermes Agent作为"智能体操作系统",提供了任务调度、多智能体协作、工具注册等基础设施,让Kimi K2.7能够真正"动手做事"而非仅仅"动嘴说话"。
任务被放入看板后,系统自动分类并分配给不同智能体——制片人负责生成数字人视频,编辑器负责剪辑,还有一位"评委"智能体负责审视成果。看板(Kanban)最初源自丰田生产系统,后被软件开发领域广泛采用(如Trello、Jira等工具),其核心思想是将工作可视化为卡片,在"待办-进行中-已完成"等列之间流转。在Hermes Agent系统中,看板被用作多智能体协作的任务调度中心:各子任务以卡片形式进入看板,系统根据每个智能体的能力自动分配,解决了多智能体系统中"谁该做什么"以及"任务依赖关系如何处理"的关键问题。
评委机制尤其有趣:它用 Kimi K2.7 观看生成的视频并打分,从最初的6分迭代到7分、9分,不断修复问题直到达标。这种自我评估和迭代循环,是传统AI工具所不具备的。
长程任务中的自纠错能力
在执行长程任务时,Kimi K2.7 会评估自己的工作,根据观察到的结果回头改进。它不是简单地按指令执行,而是具备"反思-修正"的循环能力。这对于复杂项目开发来说至关重要——在软件工程中,很少有项目能一次性写对所有代码,真正的开发过程本身就是不断调试、修复、优化的循环。Kimi K2.7的这种能力本质上模拟了人类程序员"写代码-运行-看报错-修改-再运行"的工作模式。
基准测试数据:Kimi K2.7 vs Claude 3.5
编程基准测试大幅提升
相比前代 Kimi K1.6,K2.7 在多项基准测试中实现了显著提升:
- Kimi CodeBench 编程测试:50.9 → 62.0
- 记者分:48.3 → 53.6
- 基准测试:26.7 → 35.1
MCP工具调用能力领先
在 MCP Mark Agent 工具调用基准测试中,K2.7 代码得分 81.1%,领先 Claude 3.5 的 76.4%。MCP Atlas 工具调用能力从 69.4 提升到 76,MCP Mark 验证从 72.8 涨到 81.1。
MCP(Model Context Protocol,模型上下文协议)是Anthropic于2024年底推出的开放标准协议,旨在为AI模型提供统一的外部工具调用接口。在MCP出现之前,每个AI应用需要为每个外部工具单独编写集成代码,导致生态碎片化。MCP类似于AI世界的"USB接口"——它定义了模型如何发现、调用和接收外部工具返回结果的标准流程。K2.7在MCP基准测试中领先Claude 3.5,意味着它在智能体场景下能更准确地理解何时该调用什么工具、如何传递参数,这对于构建可靠的自动化工作流至关重要。
实际使用体验:优势与不足
优势
- 性价比高:相比 Claude API 的高昂成本,Kimi K2.7 提供了接近 Claude 水准的编程能力,价格更友好
- 接入方式灵活:支持订阅制接入 Hermes Agent,不用按 Token 计费
- 长上下文处理能力强:256K Token 窗口适合大型项目的完整开发
- 自主迭代:能在后台自主运行、自我评估、自我修正
不足
- 响应速度偏慢:简单问题也需要约7秒响应,在浏览器操作等实时任务中体验不佳
- 缺乏第三方独立测评:目前主要是官方基准数据,尚未看到独立第三方验证
对非技术人员意味着什么
UP主特别强调,他本人并非程序员,但通过 Hermes Agent + Kimi K2.7 的组合,非技术人员也能完成复杂的开发任务。智能体操作系统降低了使用门槛——你不需要懂代码,只需要会描述需求。
这或许代表了AI编程工具的一个重要方向:从"辅助程序员写代码"转向"让任何人都能通过自然语言构建应用"。当模型足够强大、智能体框架足够成熟时,编程的门槛可能真的会消失。这一趋势与"无代码/低代码"运动一脉相承,但本质上更为激进——无代码平台仍然需要用户理解逻辑流程和界面操作,而AI智能体编程则试图将"意图"直接转化为"实现",中间的所有技术细节都由AI自主处理。
核心要点
相关推荐
Gemini 3.5实时翻译发布:支持70+语言的语音对语音翻译模型详解
Gemini 3.5实时翻译发布:支持70+语言的语音对语音翻译模型详解
Google发布Gemini 3.5 Live Translate语音对语音翻译模型,支持70+语言实时翻译。本文详解其端到端技术原理、与Grab合作落地场景,以及通过Google Translate和Live API的开放接入方式。
Gemma 4 12B:Google开源模型笔记本即可本地运行
Google发布Gemma 4 12B开放权重模型,12B参数量级可在笔记本电脑本地运行。本文解析其性能优势、本地部署价值及开源生态竞争格局,助开发者快速上手评估。

非技术小白用AI工具做出月入35万的SaaS产品
两个不懂代码的营销人,用AI工具半年打造月入5万美金SaaS产品Shipper的完整方法论:反向工程竞品、零免费用户策略、极简技术栈与零广告费病毒式增长,可复制的独立开发者创业路径。