Gemini 3.5实时翻译发布:支持70+语言的语音对语音翻译模型详解
Gemini 3.5实时翻译发布:支持70+语言的语音对语音翻译模型详解
语音翻译的里程碑时刻
Google近日正式发布了Gemini 3.5 Live Translate,这是其最新的语音对语音(speech-to-speech)翻译模型,支持超过70种语言。作为Google在机器学习领域持续时间最长的研究方向之一,语音翻译技术终于迎来了一次质的飞跃。
这一模型的核心亮点在于它实现了真正意义上的"实时语音翻译"——不再是传统的"语音转文字→文字翻译→文字转语音"的串联流程,而是端到端的语音对语音直接转换。这意味着翻译过程中能够更好地保留语调、情感和对话的自然节奏。
传统的语音翻译系统采用级联架构(cascade architecture),将任务分解为三个独立模块:自动语音识别(ASR)负责将语音转为文本,机器翻译(MT)将源语言文本转为目标语言文本,文本转语音(TTS)再将翻译后的文本合成为语音。这种串联方式的核心问题在于每个环节都会引入误差并累积延迟,更关键的是,语音中携带的副语言信息(paralinguistic information)——如语调、语速、情感色彩、停顿节奏——在文本中间表示阶段会大量丢失。端到端模型则用单一神经网络直接完成从源语言语音到目标语言语音的映射,跳过文本中间表示,从而能更好地保留这些非文本信息,同时显著降低整体延迟。
Gemini 3.5 Live Translate的产品落地
与Grab合作:出行场景的实时翻译
Google展示了一个极具说服力的实际应用案例——与东南亚出行巨头Grab的合作。在这个场景中,旅行者和司机可以通过Gemini 3.5 Live Translate进行跨语言的实时对话。一位只会说中文的游客在曼谷打车,能够与只会说泰语的司机自然流畅地沟通,这在过去几乎是不可能的。
Grab是东南亚最大的超级应用平台,总部位于新加坡,业务覆盖出行、外卖、金融服务等领域,在新加坡、马来西亚、印度尼西亚、泰国、越南、菲律宾、缅甸和柬埔寨等8个国家运营。东南亚是全球语言多样性最高的地区之一,仅印度尼西亚就有超过700种地方语言,泰国、越南、柬埔寨等国的官方语言各不相同。Grab平台上每天发生的跨语言交互场景极为频繁,尤其是在旅游热门城市,司机与乘客之间的语言障碍是影响服务体验的核心痛点之一。
这个案例之所以重要,是因为它代表了AI翻译技术从"能用"到"好用"的转变。出行场景对翻译的要求极高:需要低延迟、高准确率,还要处理各种口音和噪音环境。Grab选择接入这一技术,本身就是对其成熟度的有力验证。
开放接入方式:Google Translate与Live API
Gemini 3.5 Live Translate目前通过两个渠道向用户和开发者开放:
- Google Translate:直接集成到Google翻译应用中,普通用户可以即刻体验语音对语音的实时翻译
- Live API(Google AI Studio):面向开发者提供API接口,第三方应用可以像Grab一样将实时翻译能力嵌入自己的产品
Google AI Studio是Google面向开发者提供的AI模型实验和部署平台,开发者可以在其中测试Gemini系列模型的各项能力并获取API密钥。Live API是专门为实时交互场景设计的接口,支持流式音频输入和输出,这意味着开发者不需要等待用户说完整句话再进行翻译,而是可以在用户说话的同时就开始处理和输出翻译结果。这种流式处理(streaming)能力对于实现低延迟的对话体验至关重要,是区别于传统批处理翻译API的关键技术特征。
这种双轨发布策略既满足了C端用户的即时需求,又为B端生态的扩展铺平了道路。
端到端语音翻译的技术深度解析
70+语言覆盖背后的技术挑战
支持70多种语言看似只是一个数字,但背后的技术挑战不容小觑。不同语言之间的语法结构、语序差异、文化表达习惯千差万别。尤其是在语音对语音模式下,模型需要同时理解源语言的语义和韵律,并在目标语言中重新生成自然的语音输出。
从技术路线来看,Gemini 3.5 Live Translate很可能受益于Gemini系列模型的多模态能力。Gemini本身就是一个原生多模态模型,能够同时处理文本、音频、图像等多种输入,这为语音翻译提供了天然的架构优势。Gemini系列模型由Google DeepMind开发,其核心设计理念是从训练阶段就原生支持多种模态,而非像早期多模态模型那样将不同模态的编码器拼接在一起。这种原生多模态训练意味着模型内部对不同模态信息的表征是统一的,能够在共享的潜在空间(latent space)中进行跨模态推理。对于语音翻译任务而言,这意味着模型可以同时理解语音的声学特征和语义内容,并直接在目标语言的语音空间中生成输出,而不需要经过显式的文本解码步骤。
与竞品对比:行业格局的变化
实时语音翻译一直是科技巨头的必争之地。Meta此前推出了SeamlessM4T模型,微软在Teams中也集成了实时翻译功能。Google此次发布的差异化优势在于:
- 语言覆盖广度:70+语言的支持在业界处于领先水平
- 产品化程度高:直接集成到Google Translate这一全球用户量最大的翻译工具中
- 生态开放性:通过Live API让第三方开发者可以快速接入
Meta在2023年发布的SeamlessM4T(Massively Multilingual & Multimodal Machine Translation)是业界首个支持语音和文本多任务翻译的统一模型,覆盖约100种语言的语音识别和近100种语言的文本翻译。随后Meta又推出了Seamless系列的升级版本,包括SeamlessStreaming(支持流式翻译以降低延迟)和SeamlessExpressive(保留语音表达特征如情感和语调)。微软则主要通过Azure AI Speech服务和Teams会议中的实时字幕翻译来布局这一领域,其优势在于企业级场景的深度集成。相比之下,Google此次发布的Gemini 3.5 Live Translate在产品化落地速度和面向第三方开发者的生态开放性上形成了明显的差异化竞争力。
开发者如何接入Gemini实时翻译API
对于开发者而言,通过Google AI Studio的Live API,任何涉及跨语言沟通的应用——无论是客服系统、教育平台还是社交产品——都可以快速获得专业级的实时翻译能力。
语音翻译技术的成熟,正在让"巴别塔"的愿景逐步成为现实。当翻译的延迟足够低、准确率足够高、支持的语言足够多时,语言将不再是人与人之间沟通的障碍。这种能力的民主化,或许会催生出一批全新的跨语言应用场景——从跨国远程医疗咨询、国际教育直播课堂,到多语言社区的实时互动,语音翻译正在从一项实验室技术转变为基础设施级别的通用能力。
核心要点
相关推荐
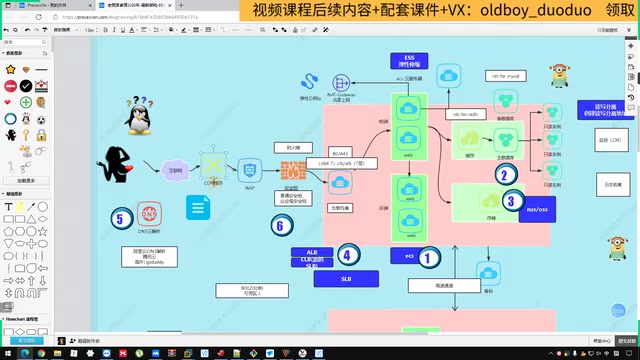
阿里云网站架构全解析:从DNS到弹性伸缩的完整链路
系统梳理阿里云网站架构核心组件,按用户请求流向详解DNS云解析、CDN、WAF防火墙、CLB/ALB负载均衡、ECS云服务器、Redis缓存、NAS/OSS存储及弹性伸缩等服务的作用与协作关系,帮助初学者建立完整的云架构认知体系。
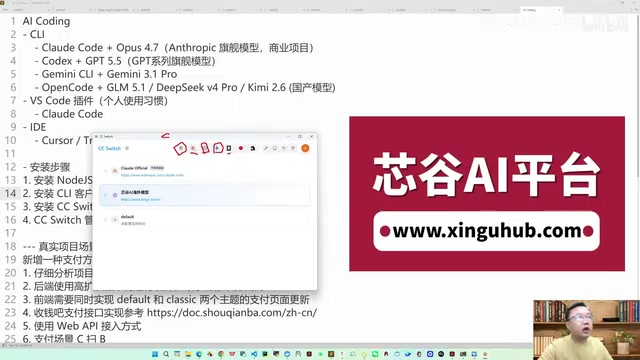
Claude Code实战:60美元4小时完成复杂支付系统二开
通过真实商业案例详解Claude Code + Opus 4.7如何在4小时内完成复杂支付系统二开,涵盖CC Switch配置、Prompt工程技巧、模型选择策略及AI Coding工程化落地方法论。

Vibe Coding入门指南:零基础用AI写代码的完整攻略
Vibe Coding(氛围编程)让零基础用户通过自然语言指令实现软件开发。本文详解Vibe Coding的核心概念、适用场景、推荐工具及实践步骤,帮你快速上手AI编程。