GPT-5.3 Codex深度解析:从编程工具到数字同事的质变
OpenAI发布GPT-5.3 Codex,标志AI从工具向自主执行的"数字同事"转变。
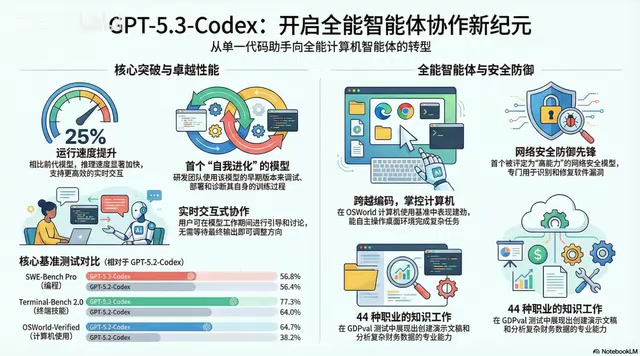
2026年2月,OpenAI发布GPT-5.3 Codex,定位为"代理式编程模型"。它突破了传统问答模式,能自主规划、执行复杂多步骤任务,融合了顶尖编程能力与推理知识能力。在多项基准测试中表现亮眼:SWE-Bench Pro达56.8分,OS World达64.7%(接近人类72%),标志着AI从编程工具向能操作电脑、懂业务的全能型数字同事转变。
文章正文
2026年2月5日,OpenAI发布了GPT-5.3 Codex——一个被官方定义为"代理式编程模型"(Agentic Coding Model)的全新系统。但仔细审视其能力边界和应用场景后会发现,"编程"二字远不足以概括它的野心。这不是一次常规的性能迭代,而可能是AI从"聪明工具"向"数字同事"转变的关键节点。
从"你问我答"到"自主执行":代理式的本质变革
理解GPT-5.3 Codex,核心在于一个词——代理式(Agentic)。它彻底颠覆了过去"你给指令,我给代码"的交互模式。
代理式AI的技术根基:代理式AI的概念源于人工智能领域的「智能体」(Agent)理论,最早可追溯至1990年代的多智能体系统研究。与传统的「请求-响应」模式不同,智能体具备感知环境、制定计划、执行行动、评估结果并循环迭代的完整闭环能力。现代大语言模型实现Agentic能力的核心技术支柱包括:工具调用(Tool Use/Function Calling)、思维链推理(Chain-of-Thought),以及长上下文窗口支持的多步骤记忆。OpenAI在GPT-4时代已通过「Code Interpreter」和「Plugins」初步试水,但彼时仍受限于单次会话的短暂性。GPT-5.3 Codex的突破在于将这些能力整合为一个可持续运行、自我纠错的执行引擎,使其从「单次任务完成者」进化为「项目级目标追踪者」。
一个代理式AI意味着什么?它能够理解一个宏观且模糊的目标——比如"帮我开发一个简单的电商网站"——然后自主规划步骤,调用所需工具(无论是打开命令行终端安装软件,还是自己打开浏览器查阅最新API文档),去执行一个可能持续数小时甚至数天的复杂任务。
这更像是你把一个项目目标交给团队里的一位初级项目经理,他自己去想办法推进,中间可能会来找你确认方向。这正是从被动工具到主动合作者的根本性转变。
在能力构成上,GPT-5.3 Codex实现了三大突破:
- 能力融合:将GPT-5.2 Codex的顶尖编程能力与GPT-5.2的推理和专业知识能力合二为一,相当于把最厉害的程序员和最博学的研究员合并成一个人
- 速度提升25%:直观的效率增益
- 实时互动的合作者:不再是提交任务后干等结果的黑箱模式
基准测试背后的故事:不只是数字
SWE-Bench Pro:56.8分的含金量
SWE-Bench(Software Engineering Benchmark)由普林斯顿大学于2023年提出,其设计初衷是填补现有代码基准测试的核心空白——大多数传统测试(如HumanEval、MBPP)考察的是「从零生成代码」的能力,而真实软件工程中80%以上的工作是理解、维护和修复已有代码库。SWE-Bench从GitHub上真实的开源项目Issue中抽取问题,要求模型在完整代码仓库的上下文中定位Bug并生成可通过测试套件的补丁。SWE-Bench Pro是其升级版本,进一步提升了问题难度并扩展了语言覆盖范围。
SWE-Bench Pro模拟的是真实世界的软件工程难题,比如修复GitHub上的真实Bug,涵盖四种主流编程语言,问题刁钻程度远超普通测试。拿到接近57分,意味着在近57%的真实工程问题上,模型能独立完成从问题理解到代码修复的全流程——GPT-5.3 Codex在很多场景下已经是一个相当可靠的软件问题诊断和修复专家,不再是只能做玩具项目的练习生。这一数字在2023年初几乎为零,技术进步速度令人震惊。
Terminal Bench 2.0:77.3%的操作技能
这项测试衡量的是命令行操作能力。对于一个AI编程代理来说,这是绝对的基本功——就像大厨必须会用刀。77.3%代表极其熟练的水平,意味着它可以自动化完成安装软件、管理文件、配置服务器这些"脏活累活"。
OS World Verified:最令人震惊的64.7%
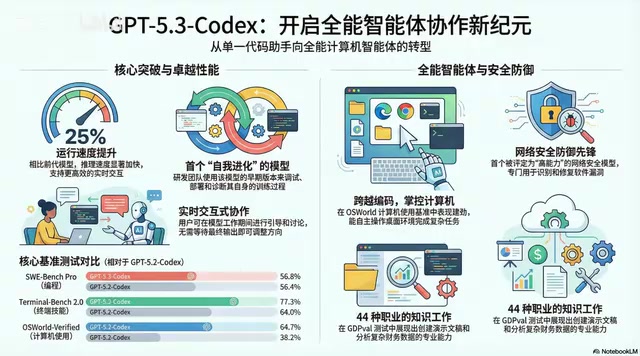
OS World是卡内基梅隆大学于2024年发布的基准测试,专门评估AI在真实操作系统图形界面(GUI)中完成任务的能力,覆盖Windows、macOS、Ubuntu三大平台,任务类型涵盖文件管理、办公软件操作、网页浏览、代码编辑等日常场景。这项测试的技术难点在于:AI需要通过截图「看懂」当前屏幕状态,规划下一步操作,并通过模拟鼠标点击和键盘输入来执行——这与纯文本推理有本质区别,要求视觉理解、空间推理和操作规划的深度融合。此前业界普遍认为GUI操作是AI的薄弱环节,Anthropic的Claude Computer Use和Google的Project Mariner也在探索这一方向。
这个数据可能是最值得关注的。OS World测试的是在图形化桌面环境中完成任务的能力——打开文件夹、找到Excel、复制数据、粘贴到PPT并设置标题——这就是我们每天在办公室做的事。
GPT-5.3 Codex得分64.7%,而人类平均得分约72%。 差距已经非常小了。这标志着「计算机使用」能力从实验室演示走向实用化临界点——AI的能力已经溢出代码和文本的世界,它能像我们一样通过"看屏幕、移动鼠标、敲击键盘"来操作普通电脑。它不再只为程序员服务,通用性被瞬间拉满。
GPQA-Val:70.9%的"文科成绩单"
这项测试衡量44种不同职业的知识工作任务表现——写商业计划书、分析市场报告、做数据可视化等。其得分与专门为知识工作优化的GPT-4.2持平,说明GPT-5.3 Codex在成为理工科高手的同时,并没有丢掉全能文科生的看家本领。
第一部分结论:我们得到的不是一个编码速度更快的程序员,而是一个能编程、会推理、懂业务、还能直接操作电脑的全能型数字同事。
从基准测试到真实产出:学霸能否适应现实
从零开发完整游戏
模型仅根据模糊指令(如"做个赛车游戏,要有不同角色和地图
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。