GPT 5.5 vs Claude Code vs DeepSeek V4: Hands-On Comparison of Three Top Coding Models
GPT 5.5 vs Claude Code vs DeepSeek V4:…
GPT 5.5, Opus 4.7, and DeepSeek V4 go head-to-head in two tough real-world coding challenges.
A YouTuber tested GPT 5.5+Codex, Opus 4.7+Claude Code, and DeepSeek V4 Pro+OpenCode on two demanding tasks: a 3D flight simulator and a WebGPU shader landing page. GPT 5.5 proved the strongest overall with the best token efficiency; Opus 4.7 showed superior design taste but at 3x the cost; DeepSeek V4, while 8x cheaper, struggled on complex tasks and is better suited for simpler work. No vendor lock-in exists — developers can freely switch between all three.
In the past 24 hours, the AI coding space has seen two major updates: OpenAI released GPT 5.5, and Anthropic's competitor DeepSeek launched its V4 version. Facing three top-tier coding model combinations — GPT 5.5 (with Codex), Opus 4.7 (with Claude Code), and DeepSeek V4 Pro (with OpenCode) — how should developers choose? YouTuber Chase put them through two challenging real-world tests and delivered a detailed comparison.
Technical Architecture Background: These three combinations represent the mainstream architecture pattern for current AI coding tools: Large Language Model (LLM) + dedicated coding execution environment. Codex is OpenAI's execution layer optimized for code generation, capable of running code in a sandbox environment and iteratively fixing issues; Claude Code is Anthropic's terminal-native coding agent that can directly manipulate the file system and execute commands; OpenCode is an open-source coding agent framework designed for DeepSeek models. This "model + agent" architecture means AI is no longer just generating code snippets — it can complete the full software development task loop.
Pricing & Benchmarks: DeepSeek Is 8x Cheaper, But How Does It Perform?
Before diving into the tests, let's look at the hard numbers for all three models.
Pricing differences are significant: per million output tokens, GPT 5.5 charges $30, Opus 4.7 charges $25, while DeepSeek V4 Pro costs just $3.48. For input tokens, both GPT 5.5 and Opus 4.7 are $5 per million, while DeepSeek is about $1.70. DeepSeek's price advantage is nearly 8x — a factor that can't be ignored.
Token Economics: A token is the basic unit that large language models use to process text, roughly corresponding to 3/4 of an English word or 1-2 Chinese characters. In AI coding scenarios, token consumption comes from multiple dimensions: on the input side, there are user prompts, code context, and error feedback; on the output side, there's generated code, explanations, and planning text. In this test, Opus 4.7 consumed about 200,000 tokens on the flight simulator task — at $25/million output tokens, that's roughly $5; while GPT 5.5 completed the same task with only 66,000 tokens — at $30/million, that's about $2, actually costing less. For development teams that heavily use AI coding tools, this token efficiency difference can significantly impact monthly bills.
However, OpenAI claims that although 5.5's unit price is twice that of 5.4, because the model is more powerful and uses fewer tokens, the actual cost to complete the same task only increases by about 20%.
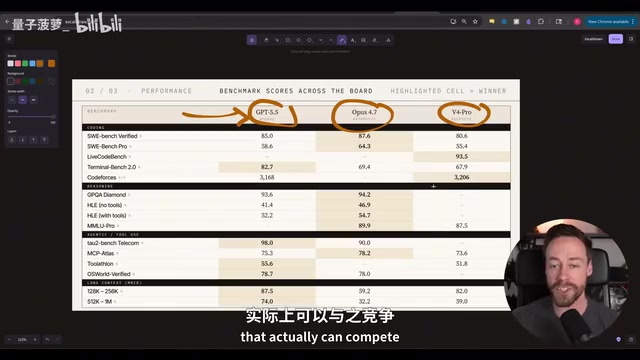
On benchmarks, all three models have reported scores across three coding benchmarks — SweetBench Verified, SweetBench Pro, and TerminalBench 2.0:
- SweetBench Verified and SweetBench Pro: Opus 4.7 wins
- TerminalBench 2.0: GPT 5.5 leads significantly with 87%, even surpassing Anthropic's yet-to-be-released Mythos model
Understanding the Benchmarks: SweetBench (formerly SWE-bench) is one of the most authoritative evaluation benchmarks in AI coding, developed by a Princeton University team. It extracts tasks from real GitHub issues, requiring models to locate and fix bugs in actual code repositories. The Verified version is human-verified to ensure tasks are solvable, while the Pro version is significantly harder. TerminalBench 2.0 specifically evaluates a model's ability to complete complex multi-step tasks in terminal environments, closely mirroring real-world command-line development workflows. It's worth noting that benchmark scores and actual development experience often diverge — benchmarks typically target standardized tasks, while creativity, visual aesthetics, and complex system integration in real projects are hard to quantify. This is precisely where hands-on testing adds value.
You might not have noticed, but although DeepSeek V4 Pro always ranks third, the gap with second place isn't that large — only about 5 percentage points behind on SweetBench Verified. Considering the 8x price difference, that's quite impressive value for money.
Another interesting finding: Opus 4.7 shows noticeable regression in long-context retrieval (500K–1M tokens), performing significantly worse than both DeepSeek and GPT 5.5.
Test 1: 3D Flight Simulator — GPT 5.5 Dominates
The first test asked all three models to create a browser-based flight simulator using Three.js, with requirements for good flight feel, a sense of weight, and strong visual effects.
Why a Flight Simulator Is a High-Difficulty Test: Three.js is a WebGL-based JavaScript 3D graphics library widely used for browser-based 3D visualization. A flight simulator is extremely challenging because it requires the AI to simultaneously handle multiple complex subsystems: physics engine (lift, drag, gravity, stall model), 3D scene rendering (terrain, clouds, lighting), HUD instruments (altimeter, airspeed indicator, heading indicator, vertical speed indicator), and user input response. These systems are tightly coupled mathematically — for example, AGL (Above Ground Level) requires real-time calculation of the aircraft's position relative to terrain, and AOA (Angle of Attack) directly affects lift calculations. A logic error in any single subsystem can cause the entire experience to collapse, which is exactly why DeepSeek and Claude both had serious issues on their first attempts.
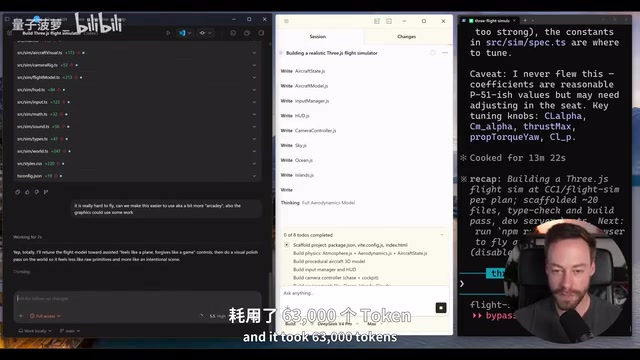
GPT 5.5 + Codex Performance
GPT 5.5 completed its first build in about 7 minutes, using 63,000 tokens. The first version had clouds, an AOA indicator, airspeed display, and other elements, but the plane simply couldn't take off. After two rounds of prompt refinement (totaling about 66,000 tokens, 15 minutes), a flyable version was finally achieved: complete with a runway, clouds, and a full instrument panel (vertical speed, altitude, heading, AGL, etc.). While the controls were somewhat stiff, the overall completeness was quite impressive.
DeepSeek V4 Pro + OpenCode Performance
It took about 10 minutes and 63,000 tokens (only $0.44), but the results were disappointing. The first version was completely unrecognizable, and the second version — while you could see an aircraft — had completely broken graphics rendering. The tester admitted that even with more prompts, it would need to be rewritten from scratch with very specific instructions, which goes beyond the scope of "iterative refinement."
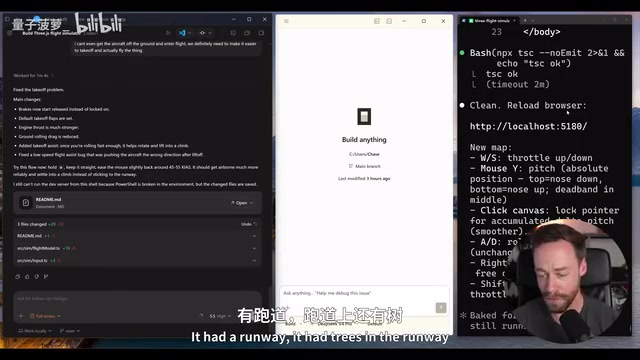
Opus 4.7 + Claude Code Performance
The planning phase alone took 5 minutes (the most detailed plan of all three, covering flight model, stall buzzer, and other details), followed by 13 minutes of execution, totaling about 200,000 tokens. But the result was also disappointing — upon loading, the plane was immediately catapulted into the air and stall-crashed. After two rounds of fixes, control issues and strange fog effects persisted. However, at least there was a plane and a runway (albeit with trees growing on it), and all the basic elements were present.
Flight Simulator Test Conclusion: GPT 5.5 wins decisively, producing the best results with the fewest tokens (66K vs 200K) in the shortest time. Claude Code comes in second — showing potential but needing more iteration. DeepSeek falls flat.
Test 2: WebGPU Shader Landing Page — A Battle of Aesthetics
The second test required creating a landing page showcasing WebGPU shader effects, with requirements for a modern feel, strong visual impact, and a style similar to Awwwards-winning websites. All three models were provided with the same skill files.
WebGPU Technical Background: WebGPU is the next-generation Web graphics API standard being advanced by the W3C, which officially landed in Chrome in 2023. Compared to the long-standing WebGL (based on OpenGL ES), WebGPU directly interfaces with modern GPU architectures (such as Vulkan, Metal, DirectX 12), offering lower CPU overhead, stronger compute shader capabilities, and better multi-threading support. In particle system scenarios, WebGPU's Compute Shaders can offload the physics simulation of hundreds of thousands of particles entirely to parallel GPU computation, something WebGL has limited ability to do. This also explains why all three models chose particle systems as their core visual element — particle systems are the most intuitive demo for showcasing WebGPU's compute capabilities, but they also place high demands on the model's understanding of GPU programming paradigms. Awwwards is a globally premier web design awards platform, and winning works typically represent the most cutting-edge web visual technology of the year.
Interestingly, all three models independently chose particle systems as the core visual element during their planning phases.
Individual Model Performance
GPT 5.5 (107K tokens, ~6 minutes): Created a page with an interactive particle field supporting mouse attract/repel interactions. However, the particles were too bright and obscured the text. After modifications it improved somewhat, but the overall design was described as "kind of ugly."
Opus 4.7 (175K tokens, slightly longer than GPT 5.5): A more restrained and elegant style, with subtle film grain effects and a bottom-to-top blur transition, using 250,000 particles. While not as "flashy," the overall taste was better.
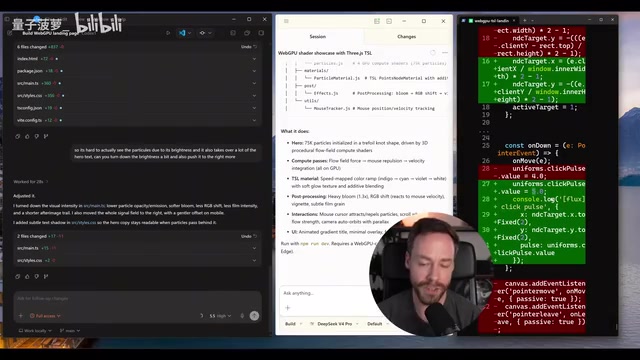
DeepSeek V4 (130K tokens, ~$1.43, longest completion time): Produced a particle field that could potentially "trigger seizures." The second version added some parallax effects and UFO-like elements, but the overall result remained rough.
Landing Page Test Conclusion: Opus 4.7 wins on aesthetics and design taste, GPT 5.5 completed the task but lacked visual polish, and DeepSeek once again came in last.
Overall Verdict: How Should Developers Choose?
Looking at both tests together:
GPT 5.5 + Codex is currently the most well-rounded choice. It led by a wide margin in the flight simulator test, and while its aesthetics were slightly weaker in the landing page test, the functionality was complete. It has the highest token efficiency and fastest speed.
Opus 4.7 + Claude Code has advantages in design taste and depth of code planning, but costs more (roughly 3-4x token consumption) and is slower. It's better suited for scenarios with higher design quality requirements.
DeepSeek V4 Pro performed poorly in both high-difficulty tests, but its price advantage is enormous. It's likely better suited for simpler tasks — when you don't need Opus or GPT 5.5-level capabilities, the 8x price difference is genuinely worth considering. As the tester put it: "DeepSeek's landing page really doesn't look good, but is it really 8 times worse? That's hard to quantify."
The most important takeaway: There's no real vendor lock-in between these three tools. Whether you learn Claude Code or Codex, the core skills are AI fundamentals and building mindset — these are transferable across any platform. More competition only benefits developers.
Key Takeaways
- GPT 5.5 dominated the flight simulator test, producing the best results with the fewest tokens (66K) in the shortest time; Opus 4.7 came second, DeepSeek V4 fell flat
- DeepSeek V4 is priced at just 1/8 of competitors ($3.48 vs $25-30 per million output tokens), but performed worst in both high-difficulty coding tests — better suited for simpler tasks
- Opus 4.7 demonstrated superior design taste in the WebGPU landing page test, but consumed roughly 3x more tokens than GPT 5.5 and was slower
- The three models are close on benchmarks (about 5 points apart on SweetBench), but show significant performance differences on actual complex tasks
- There's no vendor lock-in between the three coding tools — the core skill is AI programming fundamentals, and you can freely switch between them
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.