#GPT 5.5
23 related articles
·2 分钟
AI Aggregator Platforms Tested: A Complete Guide to Using GPT 5.5 and Other Top Models for Free
A hands-on guide to using GPT 5.5, Gemini 3.1 Pro, and Grok 4.2 for free via AI aggregator platforms, covering cross-model context memory, account pool mechanisms, and key security risks.
阅读全文 →
·2 分钟
AI Coding Dependency: As Tools Get Stronger, Are Developers Getting Weaker?
Exploring the capability anxiety behind AI coding tool dependency. Analyzing the paradox of short-term efficiency vs. long-term skills, with strategies for developers to stay competitive in the AI era.
阅读全文 →
·2 分钟
AI Super App Showdown: A Comprehensive Comparison of Cursor, Codex, Claude, and Anti-Gravity
In-depth comparison of four AI Super Apps — Cursor, Codex, Claude Desktop, and Anti-Gravity — across 11 dimensions to help you find the best AI dev tool.
阅读全文 →
Is Claude Opus 4.8 Real? Risk Analysis…
·2 分钟
Is Claude Opus 4.8 Real? Risk Analysis of No-VPN AI Platforms
In-depth analysis of viral Claude Opus 4.8 no-VPN tutorials on Bilibili, exposing fake model versions, third-party platform security risks, and legitimate ways to access international AI models.
阅读全文 →
From Claude Oceanus to GPT-5.6: A Comp…
·3 分钟
From Claude Oceanus to GPT-5.6: A Complete Breakdown of This Week's Major AI Model Updates
Deep analysis of this week's major AI model updates: Anthropic Oceanus red team leak, OpenAI GPT-5.6 Dual Alpha exposed, NVIDIA Nemotron Ultra 550B release, and AI recursive self-improvement research breakthrough.
阅读全文 →
·2 分钟
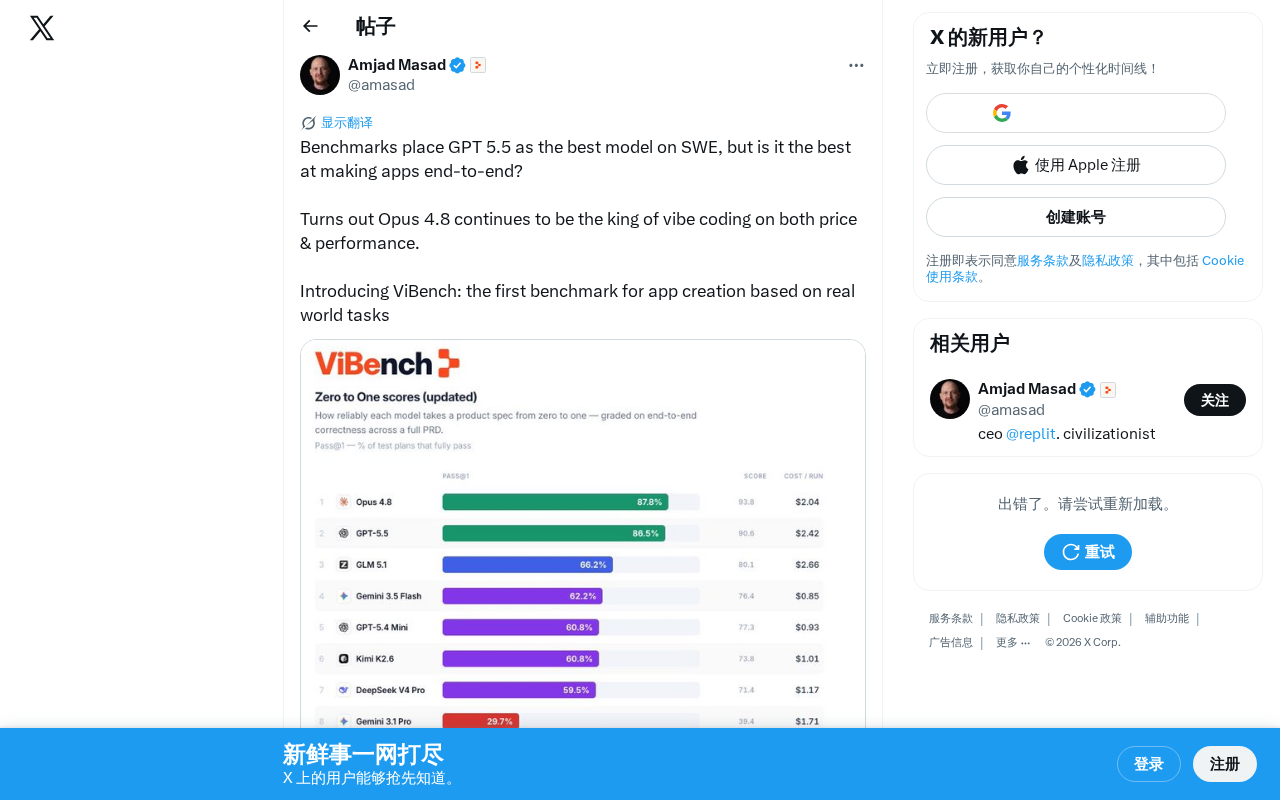
ViBench Benchmark: End-to-End App Creation Evaluation Reveals the True Level of AI Programming
ViBench is the first end-to-end app creation benchmark based on real-world tasks. Results show Claude Opus 4.8 leads in performance and cost-effectiveness, revealing gaps between SWE-bench scores and actual development capability.
阅读全文 →
 教程攻略
教程攻略·1 分钟
Codex Setup Guide for China: Complete Tutorial from Registration to Running
Complete guide to installing OpenAI Codex in China, covering API key setup via relay platforms, CC Switch bridge configuration, client installation, and troubleshooting.
阅读全文 →
 科技前沿
科技前沿·3 分钟
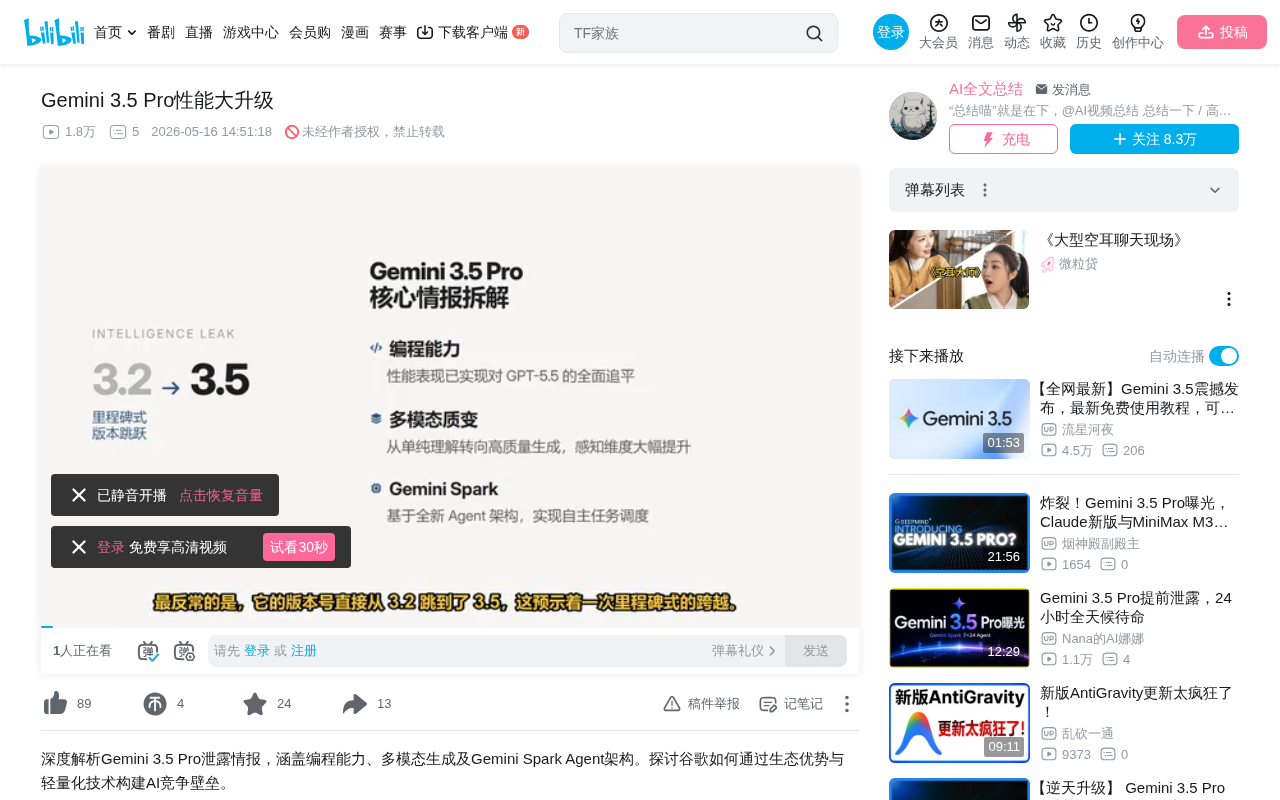
Gemini 3.5 Pro Leak Analysis: Coding Matches GPT 5.5, Spark Agent Sparks Privacy Controversy
Gemini 3.5 Pro leak analysis: coding matches GPT 5.5, lightweight Flash achieves 92% performance at 20x lower cost. Gemini Spark as a 24/7 AI Agent raises privacy concerns amid Google's ecosystem flywheel strategy.
阅读全文 →
 教程攻略
教程攻略·4 分钟
Claude Code to Codex Migration Guide: Setup, Pricing, and Combined Usage in Practice
A detailed guide for Claude Code users to quickly get started with OpenAI Codex, covering desktop and CLI setup, pricing comparison, seamless project migration, plugin configuration, and context management differences.
阅读全文 →
 教程攻略
教程攻略·3 分钟
From Claude Code to Codex: A Practical Guide to Diversifying Your AI Coding Tools
Learn how to integrate OpenAI Codex into your dev workflow alongside Claude Code. Covers pricing comparison, desktop setup, one-click migration, context management differences, and unique visualization features.
阅读全文 →
 行业洞察
行业洞察·3 分钟
GPT 5.5 Dubbed 'Autistic Genius': Codex Downloads Surge 1397%, The Truth Behind the Developer Exodus
OpenAI CEO Altman calls GPT 5.5 an 'Autistic Genius.' Codex downloads surge 1397% to 90M while Claude Code drops 38%. Deep analysis of the developer migration driven by cost, performance, and UX.
阅读全文 →
 产品体验
产品体验·2 分钟
GPT 5.5 Image 2.0 for Academic Illustrations: Technical Roadmaps & Defense PPTs Compared with Gemini
Hands-on testing of GPT 5.5 Image 2.0 for research technical roadmaps and thesis defense PPTs, compared with Gemini Pro on quality, stability, and academic adaptability.
阅读全文 →
 科技前沿
科技前沿·3 分钟
Gemini 3.2 Pro Leaked Tests Disappoint, GPT-5.6 Already in Internal Testing
Gemini 3.2 Pro leaked tests show mediocre results with minor SVG improvements but weak UI. GPT-5.6 enters internal testing while Claude's new preview achieves breakthrough cybersecurity performance.
阅读全文 →
 行业洞察
行业洞察·2 分钟
A Week of Seismic Shifts in AI: The Compute Race, Model Price Wars, and Robotics Breakthroughs
This week's AI highlights: Anthropic partners with SpaceX for compute, OpenAI launches GPT 5.5 Instant with fewer hallucinations, DeepSeek V4 challenges closed-source giants at 1/50th the cost, and Chinese humanoid robots stun.
阅读全文 →
 科技前沿
科技前沿·2 分钟
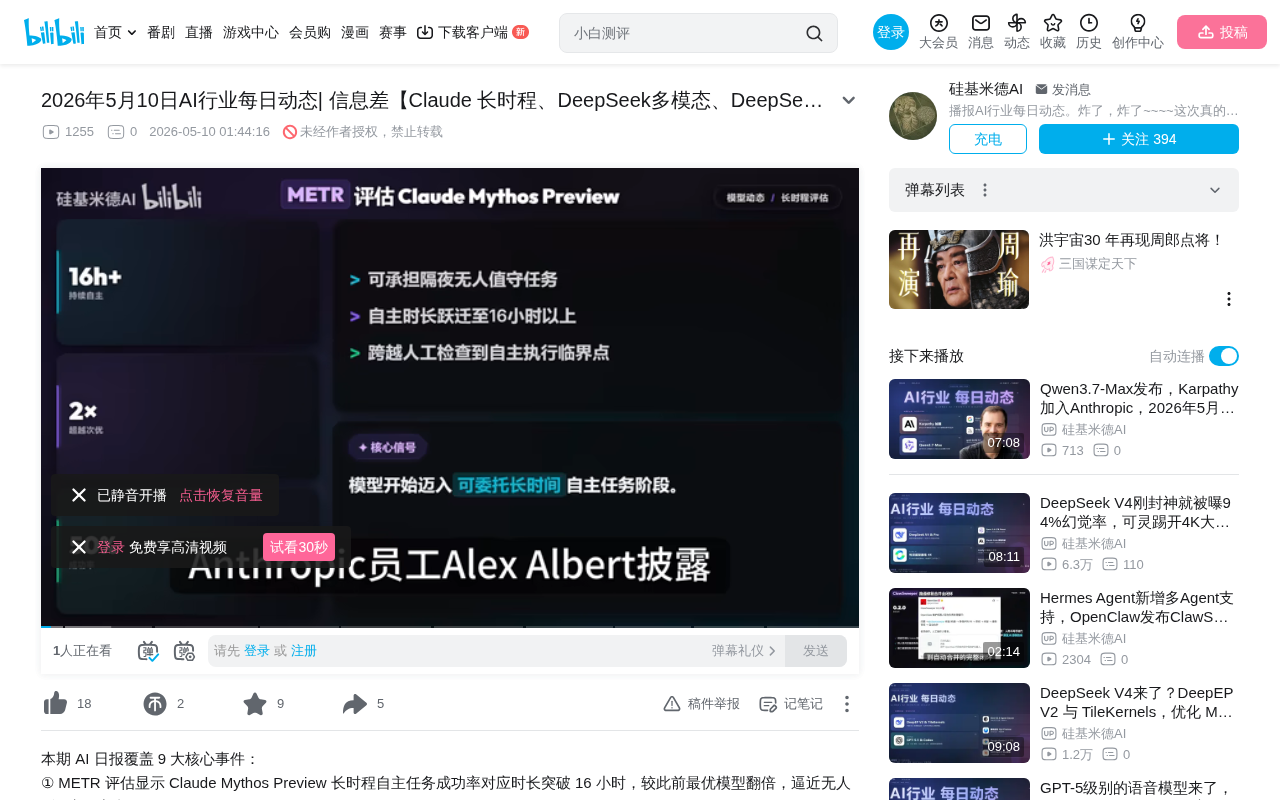
AI Daily: Claude Autonomous Tasks Exceed 16 Hours, GPT 5.5 Proves Mathematical Theorems
May 10, 2025 AI roundup: Claude autonomous tasks exceed 16 hours, GPT 5.5 Pro aids Fields Medalist in math proof, Cloudflare cuts 20% of staff due to AI.
阅读全文 →
 科技前沿
科技前沿·3 分钟
GPT 5.5 Instant Deep Dive: How It Tackles AI Hallucinations for Trustworthy Real-World Deployment
Deep dive into GPT 5.5 Instant's core breakthrough: dramatically reducing AI hallucination rates while achieving low latency and high accuracy. Explore real-world applications in legal, medical, and financial sectors.
阅读全文 →
 教程攻略
教程攻略·3 分钟
AI Penetration Testing in Practice: Comparing Three Agent Tools with DeepSeek for Vulnerability Discovery
Hands-on comparison of Claude Code, Codex, and DeepSeek TUI for AI-assisted penetration testing with DeepSeek V4 Pro, covering vulnerability discovery, WebShell upload, and intranet penetration.
阅读全文 →
产品体验
Cursor Composer 2.5 Hands-On: An AI Co…
·2 分钟
Cursor Composer 2.5 Hands-On: An AI Coding Model That's Faster and 10x Cheaper
Hands-on review of Cursor Composer 2.5's Agent view, Plan mode, and right panel features. Coding ability matches Claude and GPT top models at up to 10x lower cost with significantly faster speed.
阅读全文 →
教程攻略
Complete Tutorial: Using GPT to Automa…
·2 分钟
Complete Tutorial: Using GPT to Automatically Configure Claude Opus 4
Learn how to use GPT's high-intensity thinking mode to automatically configure Claude Opus 4.6/4.7 Max thinking mode in OpenCode, including proxy channel setup, API Key creation, and environment configuration.
阅读全文 →
产品体验
Grok Build vs GPT 5.5 vs Composer 2.5:…
·2 分钟
Grok Build vs GPT 5.5 vs Composer 2.5: Hands-On Comparison Across 17 Frontend Tasks
Hands-on comparison of Grok Build 0.1, GPT 5.5, and Composer 2.5 across 17 complex frontend tasks, evaluating code depth, visual quality, requirement coverage, and cost-effectiveness.
阅读全文 →