ViBench Benchmark: End-to-End App Creation Evaluation Reveals the True Level of AI Programming
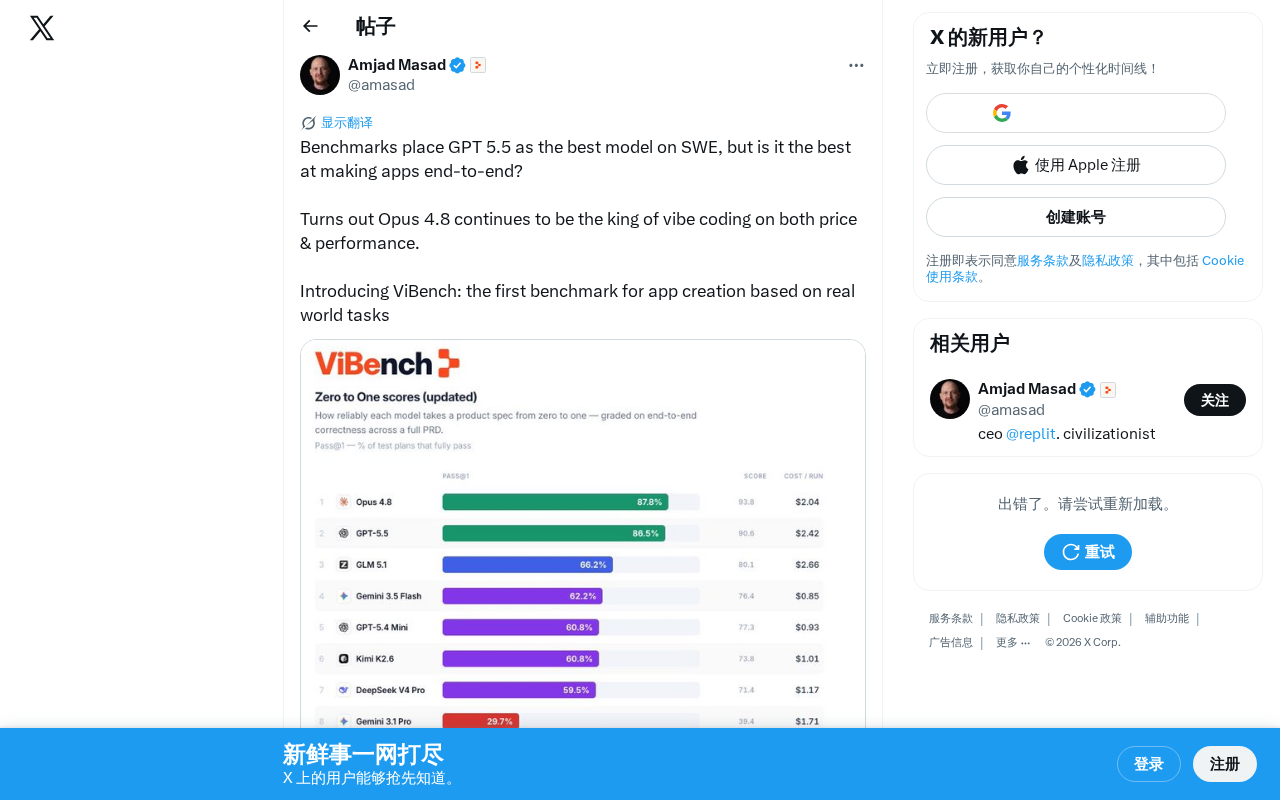
ViBench benchmark shows Claude Opus 4.8 leads in real-world end-to-end app creation over GPT 5.5.
ViBench is the first benchmark evaluating AI's ability to build complete applications from scratch, unlike SWE-bench which focuses on local code fixes. Test results reveal Claude Opus 4.8 outperforms competitors in both quality and cost-effectiveness for end-to-end app creation, challenging GPT 5.5's dominance on traditional benchmarks and highlighting the importance of scenario-based model selection.
Introduction: SWE Benchmarks Don't Equal Real-World Development Ability
When OpenAI's GPT 5.5 topped software engineering benchmarks like SWE-bench, many naturally assumed it was the most powerful coding AI. However, the newly released benchmark ViBench poses a fundamentally different question: In real-world end-to-end application development scenarios, who is the true champion?
The answer is surprising — Claude Opus 4.8 consistently leads in both price and performance, making it the champion of "Vibe Coding."
What Is ViBench?
The Evaluation Leap from Code Snippets to Complete Applications
ViBench is the first application creation benchmark based on real-world tasks. Unlike traditional tests such as SWE-bench, it doesn't merely evaluate a model's ability to fix bugs or complete code snippets — it examines AI's end-to-end capability to build complete applications from scratch.
To understand ViBench's significance, we first need to understand the existing standards it challenges. SWE-bench is a software engineering benchmark released by a Princeton University research team in 2023. It collected 2,294 real issue-pull request pairs from 12 popular Python open-source projects on GitHub (such as Django, Flask, scikit-learn, etc.), requiring AI models to automatically generate code patches to resolve issues based on their descriptions. The subsequently released SWE-bench Verified version, manually validated and filtered down to a subset of 500 confirmed solvable problems, became the industry standard for measuring AI code repair capabilities. The core feature of this test is that it's based on real historical issues from open-source projects rather than artificially constructed programming problems — but it is still essentially a "local repair" task.
ViBench's evaluation leap lies in requiring models to complete full application construction from zero to one. This distinction is crucial. In actual development, creating a complete application involves:
- Understanding requirements and performing architectural design
- Handling frontend-backend coordination and integration
- Managing state, routing, data flow, and other complex interactions
- Generating complete, runnable, deployable code
End-to-end application creation requires AI models to possess comprehensive abilities far beyond code completion. First is architectural decision-making — choosing appropriate tech stacks, designing database schemas, and planning API interfaces. Second is cross-file coordination — ensuring type consistency and interface compatibility between frontend components, backend routes, and data models. Third is state management — handling cross-cutting concerns like user authentication, session management, and caching strategies. These tasks require models to maintain extremely long context consistency and logical coherence across thousands of lines of code, placing extremely high demands on the model's long-context understanding and planning capabilities.
Why Traditional Benchmarks Fail to Reflect Real Programming Ability
Tests like SWE-bench primarily focus on local tasks such as code completion and bug fixing. While these capabilities are certainly important, they cannot reflect a model's comprehensive performance when creating applications "from zero to one." A model might excel at fixing logical errors in a single function yet lose its way when building a complete project — lacking global architectural awareness and module coordination ability.
This difference can be analogized as follows: a person might excel at English cloze tests but may not necessarily write a structurally complete, logically coherent long-form essay. There is a qualitative gap between local ability and global ability, not merely a quantitative accumulation.
Why Does Claude Opus 4.8 Win in ViBench?
Leading in Both Performance and Cost-Effectiveness
According to ViBench test results, Claude Opus 4.8 excels in two key dimensions:
- Performance dimension: In end-to-end application creation tasks, Opus 4.8 generates higher-quality applications with better feature completeness
- Cost dimension: Considering API call costs, Opus 4.8 provides superior cost-effectiveness
In actual production environments, the cost structure of AI programming tools directly impacts their viability. API call costs vary significantly across models: input token and output token prices, context window size, and total token consumption required to complete complex tasks collectively determine the actual cost per task. For end-to-end application creation tasks that require substantial output, output token pricing carries more weight. Additionally, a model's "first-attempt success rate" is a hidden cost factor — if a model requires multiple iterations to generate runnable code, actual costs multiply. ViBench's inclusion of cost as an evaluation dimension reflects the industry's shift from "capability-first" to "efficiency ratio" thinking.
This means that for actual application development scenarios — especially the currently popular "Vibe Coding" workflow — Opus 4.8 is the more pragmatic choice.
Vibe Coding Workflow Explained
"Vibe Coding" is a popular concept in the AI programming community, referring to developers describing requirements in natural language and letting AI generate complete application code, with developers primarily playing the role of guide and reviewer. In this workflow, a model's global understanding ability, code organization capability, and consistency maintenance are more critical than pure code completion ability.
This concept was first proposed by Andrej Karpathy (former Tesla AI Director, OpenAI co-founder) in February 2025. He described an entirely new programming paradigm: developers fully immerse themselves in the "vibe," building software through natural language conversations with AI, directly pasting error messages to AI for handling when encountering bugs, rather than reading and understanding code line by line. This approach blurs the boundary between "programmers" and "non-programmers," enabling people without deep programming expertise to build fully functional applications. Karpathy himself built multiple projects this way, sparking widespread discussion about the future form of software engineering.
Under the Vibe Coding paradigm, the core capabilities a model needs include: understanding ambiguous natural language requirements and translating them into concrete technical solutions, generating large amounts of runnable code in single or few interactions, and maintaining consistency with existing code in subsequent iterations. These capabilities are precisely what ViBench evaluates, and the areas where Opus 4.8 excels.
Implications for Developers Choosing AI Programming Tools
Choose the Right Model Based on Your Use Case
This result reminds us: the choice of benchmark determines the conclusion. If your work primarily involves maintaining existing codebases and fixing bugs, GPT 5.5 may indeed be the best choice. But if you're more engaged in new project creation, prototype development, or full-stack application building, Opus 4.8 may better fit your workflow.
Specifically, the following scenarios are better suited to models that perform well in ViBench-type tests:
- Rapid Prototyping: Need to go from concept to demonstrable product within hours
- Hackathons and creative projects: Time-pressured situations requiring one-shot generation of substantial functional code
- Full-stack projects for indie developers: One person handling both frontend and backend, needing AI as an all-around assistant
- MVP (Minimum Viable Product) development: Startup teams quickly validating business hypotheses
The Diversification Trend in AI Evaluation Benchmarks
The emergence of ViBench reflects an important trend in AI evaluation: a single benchmark cannot comprehensively measure model capabilities. As AI programming tool use cases become increasingly diverse, we need more evaluation standards targeting specific workflows to make more informed tool choices.
This trend echoes the broader "benchmark saturation" phenomenon in the AI field. When mainstream models' scores on existing benchmarks converge, the community needs to design new evaluation methods that more closely mirror actual use cases to differentiate model capabilities. ViBench represents a paradigm shift in evaluation from "what can the model do" to "what can the model help users accomplish" — the former focuses on isolated technical capabilities, while the latter focuses on actual productivity gains.
Conclusion
GPT 5.5's leading position on traditional software engineering benchmarks is well-established, but ViBench reveals a more nuanced picture: in the increasingly important scenario of end-to-end application creation, Claude Opus 4.8 holds the advantage with its excellent performance-to-cost ratio. For developers, what matters most is not chasing the title of "strongest model," but finding the AI programming tool that best fits their workflow.
As AI programming tools mature, we are witnessing an industry shift from "universal leaderboards" to "scenario-based selection." Future developers may choose AI models much like they choose programming languages — there is no absolute optimal solution, only the tool best suited to a specific problem domain.
Key Takeaways
Related articles

Claude Code for Test Development in Practice: An AI Programming Workflow That Doubles Your Efficiency
A practical guide to Claude Code for test development: auto-generating test scripts, Plan Mode workflows, MCP + Playwright integration, and Subagent parallel tasks to build systematic AI-assisted workflows.

Hermes Agent Hands-On Review: An AI Efficiency Revolution for Indie Game Developers
Indie game developer reviews Hermes Agent vs OpenClaude: intelligent context compression, real-time Memory, remote control via Telegram, and practical use cases in game dev, social media, and email.

Vibe Coding Beginner's Guide: Tool Selection Across Three Categories with Practical Examples
A comprehensive guide to Vibe Coding's three tool categories: Agent frameworks, CLI Coding, and IDE tools, with practical examples including Snake game and data analysis workbench.