From Claude Oceanus to GPT-5.6: A Complete Breakdown of This Week's Major AI Model Updates
From Claude Oceanus to GPT-5.6: A Comp…
Breaking down Anthropic Oceanus, OpenAI GPT-5.6, NVIDIA Nemotron Ultra, and AI self-improvement breakthroughs.
This week saw major AI developments including Anthropic's leaked Oceanus model entering red team testing as Mythos's successor, OpenAI's GPT-5.6 Dual Alpha checkpoint surfacing with impressive base model capabilities, NVIDIA releasing the 550B-parameter MoE Nemotron Ultra at 10x lower cost than GPT-5.5, and Anthropic publishing landmark research on AI recursive self-improvement showing 80% of their code is now written by Claude.
This week brought a flurry of model updates and leaks in the AI space—from Anthropic's mysterious new model Oceanus, to OpenAI's GPT 5.6 Checkpoint, to NVIDIA's 550-billion-parameter behemoth Nemotron Ultra. Competition among major players has reached a fever pitch. This article covers the most important AI model developments of the week to help you stay on top of the industry pulse.
Anthropic Oceanus: The Successor to Mythos Is Coming
Reports indicate that Anthropic is internally red-teaming a new model codenamed "Oceanus." Red teaming is a core practice in AI safety, originating from adversarial testing concepts in military exercises—specialized testers systematically probe models for vulnerabilities, biases, and potentially harmful outputs. Anthropic's red teaming typically occurs in two phases: internal and external. The external phase invites independent researchers and professional organizations to participate, and its launch usually signals that the model has passed internal safety reviews and is in the final verification stage before public release.
This model is believed to be the successor to the current Mythos Preview, and sources familiar with the project have revealed that Anthropic typically launches external red teaming about one week before public release—meaning an official launch could come sooner than expected.
However, complications have arisen. The red team testing project has reportedly been paused because someone may have been reselling model access through Chinese API proxies. If true, this would explain why Anthropic quickly shut down the testing phase. These claims remain unconfirmed by official sources.
Oceanus Pricing Leak
Leaked information shows Oceanus/Mythos pricing at $16 per million input tokens and $80 per million output tokens. Tokens are the basic units that large language models use to process text—in English, each word corresponds to roughly 1–1.5 tokens, while in Chinese, each character is approximately 1.5–2 tokens. Model API pricing is typically charged separately for input and output tokens, with output prices being higher because text generation requires more computational resources.
This pricing is quite steep—roughly 5x higher than Claude Sonnet 4 ($3 input/$15 output), reflecting its positioning as a flagship reasoning model. However, given its capability performance, it may still be attractive for enterprise applications.
Mythos Preview's Stunning Code Generation Capabilities
Leaked outputs from Mythos Preview have demonstrated extremely powerful capabilities. One of the most impressive examples is a complete fantasy world scene generated entirely by the model—reportedly accomplished under zero-shot conditions using only low-intensity reasoning. Zero-shot refers to a model's ability to complete tasks based solely on instruction descriptions without any reference examples, in contrast to few-shot (providing a small number of examples). The stronger a model's zero-shot capability, the higher its generalized understanding.
The entire project uses Three.js and HTML. Three.js is a WebGL-based JavaScript 3D graphics library widely used for browser-based 3D visualization and game development. The model wrote its own custom mesh generation engine, meaning it not only understands the Three.js API but also possesses the architectural ability to design complex 3D rendering pipelines from scratch—something nearly impossible for models just a year ago. The final output includes castles, villages, rivers, forests, and farmland, complete with a full day/night cycle control system.
Another impressive example is a macOS clone: Claude Opus generated a complete macOS clone from a single prompt, including SVG icons for all applications. The output was approximately 50,000 tokens with over 3,000 lines of code, even including functional modules like a Google Maps clone, music player, messaging app, and photos app.
Anthropic's Landmark Paper: AI Recursive Self-Improvement
Anthropic has published what may become one of the most important AI research papers of the year. Recursive self-improvement is a key concept in AI safety research, referring to AI systems that can improve their own code, training processes, or architecture, thereby producing more powerful next-generation versions in a positive feedback loop. This concept is closely related to the "intelligence explosion" hypothesis—once AI can effectively improve itself, the rate of improvement could grow exponentially.
Key findings include:
- Claude has advanced Anthropic's internal AI development to a new stage, forming a potential pathway toward AI recursive self-improvement
- Claude Mythos Preview can work autonomously on complex tasks for at least 16 hours, pushing evaluation systems like METR to their measurement limits. METR (Model Evaluation and Threat Research) is an independent AI safety evaluation organization that designs long-duration, multi-step complex tasks to test the boundaries of AI model autonomy. Their evaluation tasks typically require models to work continuously for hours. When models begin to break through the upper limits of these evaluations, it means existing frameworks may no longer adequately differentiate capability differences among top models
- Engineers are delivering approximately 8x more code per quarter than before, with about 80% of merged code written by Claude
- Mythos improved Claude Code's success rate on open-ended engineering tasks from 40% to nearly 70%
Anthropic's boldest claim is that AI-generated code quality is beginning to approach human levels, and they believe it will comprehensively surpass humans within a year. The paper's mention of "80% of code written by Claude" and "8x engineer output improvement" suggests AI is already substantively accelerating AI development itself—though human oversight and decision-making are still required, the degree of autonomy is rapidly increasing. If this trend continues, we may be witnessing the early stages of AI systems actively accelerating their own development.
OpenAI GPT-5.6 Checkpoint: Dual Alpha Surfaces
Someone spotted a new GPT 5.6 Checkpoint, codenamed "Dual Alpha," in a YouTuber's Codex app demo video. In the large model training process, a checkpoint refers to a model snapshot saved at a particular training stage. GPT-5.6 Checkpoint means this is likely an intermediate version from the GPT-5 series training process rather than a final release. Large model training typically runs for weeks to months, producing multiple checkpoints for evaluation and debugging. Codenames like "Dual Alpha" are typically used to internally track different training configurations or data mixing strategies. Although the footage was quickly taken down, screenshots have already leaked.
GPT-5.6 Key Highlights
Early outputs show impressive performance on SVG generation and front-end development tasks. What's particularly interesting is that many examples were generated using the base model without reasoning enabled. A base model refers to the raw pre-trained model that hasn't undergone RLHF (Reinforcement Learning from Human Feedback) alignment—improvements in its raw capabilities indicate fundamental improvements in underlying training data and architecture. If confirmed, this suggests a significant leap in the model's raw capabilities.
Some early testers believe GPT 5.6 and Anthropic's Mythos have surpassed Gemini's long-held lead in SVG generation and creative web development tasks. However, this claim still requires more verification.
ChatGPT Memory System Upgrade
OpenAI simultaneously announced a major upgrade to ChatGPT's memory system, currently rolling out to US Plus and Pro users. The new architecture builds on the previous "Dreaming" feature, enabling ChatGPT to better integrate information through continued use. The "Dreaming" feature refers to a background processing mechanism where the model organizes, summarizes, and connects existing conversation memories during non-interactive periods—similar to how the human brain consolidates memories during sleep. Users can intuitively view what ChatGPT remembers through a new memory system page.
Additionally, OpenAI has optimized the workflow for building iOS apps in Codex, with a new Build iOS App plugin that allows viewing and testing Swift UI previews directly in the built-in browser.
NVIDIA Nemotron Ultra: A 550-Billion-Parameter Agent-Focused Model
NVIDIA has released Nemotron 3 Ultra, a 550-billion-parameter MoE frontier model specifically designed for long-running AI agent tasks and complex autonomous workflows.
MoE (Mixture of Experts) is a model architecture design that divides model parameters into multiple "expert" sub-networks, activating only a small portion (typically 10–20% of total parameters) during each inference pass. This is the key to how Nemotron Ultra can dramatically reduce inference costs while maintaining high performance—although total parameters reach 550 billion, actual computation is far less than a dense model of equivalent scale. Compared to traditional dense models (like early GPT series) that activate all parameters during every inference, MoE architecture allows models to be "large but affordable," making them particularly suitable for agent application scenarios that require broad knowledge but are latency-sensitive.
Nemotron Ultra Core Advantages
- Inference speed up to 5x faster
- Up to 30% cost reduction on advanced agent tasks compared to other frontier open models
- Currently accessible for free via OpenRouter
Nemotron Ultra vs GPT-5.5 in Practice
Atomic Chat compared Nemotron Ultra and GPT-5.5 using a series of physics-effect HTML5 Canvas simulations. Results showed GPT-5.5 output was slightly stronger, but Nemotron Ultra followed very closely. The real gap is in cost: Nemotron Ultra completed tasks for just 5 cents, while GPT-5.5 cost about 57 cents—roughly 10x cheaper. For scenarios requiring large-scale agent deployment, this cost advantage is extremely attractive. This cost difference primarily stems from the computational efficiency advantages of MoE architecture and NVIDIA's unique optimization capabilities in inference infrastructure as a GPU manufacturer.
Other Notable AI Developments
Google DreamBeans
Google launched the DreamBeans experimental project through Google Labs, available to Google AI Ultra users in the US. It's a personal intelligence system that generates personalized story content daily based on user data and context. While not a groundbreaking product, it demonstrates a new direction for AI personalized content generation—a paradigm shift from general-purpose conversational assistants toward deeply personalized, proactively pushed content.
Agent Arena Benchmark
Arena launched a new Agent Arena benchmark containing over 300,000 tasks, 2 million tool calls, and 40 million lines of AI-generated code. The scale of this benchmark far exceeds previous evaluation systems, reflecting the industry's shift in AI agent capability assessment from simple Q&A accuracy toward complex multi-step task completion ability. In the rankings, GPT 5.5 High takes first place, with Opus 4.7 with Thinking enabled close behind.
Google Gemma 4 12B
Google released Gemma 4 12B under the Apache 2.0 license, designed as a powerful multimodal AI model that can run locally on most devices. Apache 2.0 is one of the most permissive open-source licenses, allowing commercial use, modification, and distribution—meaning developers and enterprises can freely integrate Gemma 4 into commercial products without paying licensing fees. The 12B (12 billion) parameter scale enables it to run on consumer GPUs or even high-end laptops, filling the capability gap between cloud-based large models and on-device small models.
Summary and Outlook
This week's dense updates clearly illustrate the new competitive landscape in AI: Anthropic continues to push breakthroughs in model capabilities, OpenAI keeps iterating on product experience, and NVIDIA targets cost-performance advantages for agent scenarios. With the official releases of Oceanus and GPT-5.6 approaching, the next round of model wars could ignite within weeks. For developers and enterprise users, choosing the right model will increasingly depend on specific use cases—whether pursuing peak performance or optimizing cost efficiency, different vendors are providing different answers.
Related articles
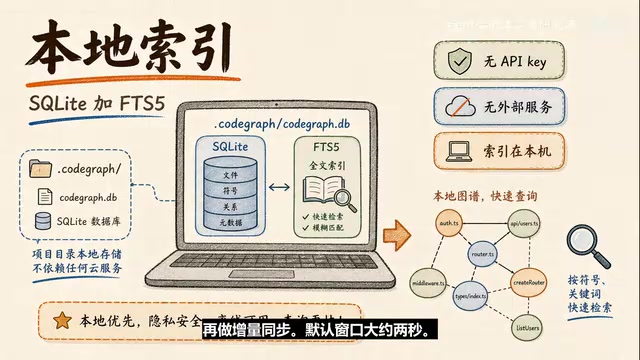
CodeGraph: Give Your Coding Agent a Code Map, Save 47% Tokens
CodeGraph is an open-source project with ~40K GitHub stars that uses Tree-sitter to build a local queryable code map, helping Claude Code and Cursor reduce 47% token usage and 58% tool calls.
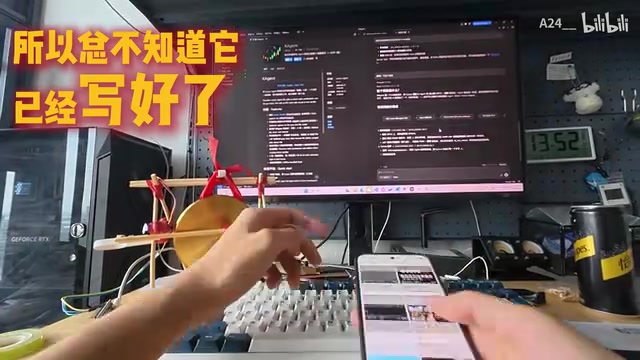
AI Finishes Writing Code, Automatically Strikes a Gong to Alert You: Open-Source Physical Feedback Tool DAgent
A developer built a physical feedback device with chopsticks and a small gong that auto-strikes when AI finishes coding. Now open-sourced as DAgent, it also simulates IPO bell-ringing when creating new files.

Level Up Claude Code: Building an Enhanced Plan Mode with Grill Me
Learn how to install and use the Grill Me Skill for Claude Code, replacing AI guesswork with structured questioning to clarify requirements before generating execution plans.