GPT 5.5即时版深度解析:幻觉率腰斩背后的能力与安全博弈
GPT 5.5即时版能力大幅提升,但生物安全防线存在隐忧
OpenAI发布的GPT 5.5即时版在医疗法律领域幻觉率降低约一半,网络安全任务甚至击败上一代思考型模型,首次实现即时模型逼近顶级模型水平。但在高难度对抗性攻击下,模型的危险内容拒绝率也降低了约一半,OpenAI通过外挂分类器"保镖"打补丁而非从模型层面解决,引发安全内建与外挂之争。此外,HealthBench基准测试被"冗长加成"刷分的问题也被揭露。
Two Minute Papers 频道近日对 OpenAI 最新发布的 GPT 5.5 即时版(Instant)进行了全面解读。与前沿的「思考型」模型不同,即时版才是全球数亿用户日常使用的版本——从普通人查询用药信息到专业人士快速获取答案,它的每一次升级都直接影响最广泛的用户群体。这次更新带来了令人惊喜的能力提升,但也暴露了值得警惕的安全隐患。
好的一面:幻觉率腰斩,能力逼近顶级模型
医疗法律领域幻觉率大幅下降
GPT 5.5 即时版在医疗和法律领域的幻觉率(hallucination rate)大约降低了一半。这是一个极其重要的改进。此前,律师使用 AI 生成的案例在法庭上被发现根本不存在的新闻屡见不鲜,而医疗领域的错误信息更可能直接危及生命。幻觉率减半意味着这类风险被显著降低,对于依赖 AI 获取关键信息的普通用户来说,这是实实在在的进步。
即时模型首次逼近最强模型
这可能是历史上第一个在某些任务上接近世界最强模型水平的即时系统。以 OpenAI 新推出的 Troubleshooting Bench(故障排查基准测试)为例,该测试包含生物实验协议中的真实错误问题——这些问题极其困难,教科书几乎派不上用场。顶级 PhD 专家在该基准上的得分约为 36%,而 GPT 5.5 即时版的得分仅略低于此。
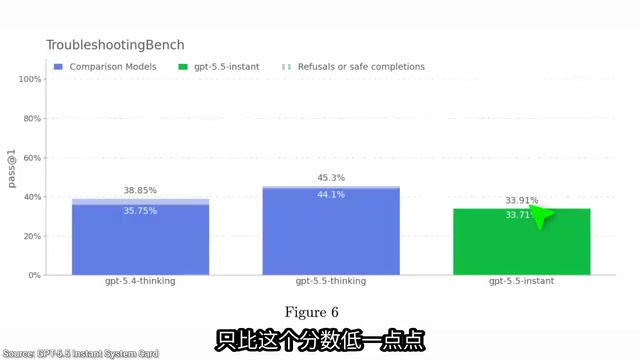
要知道,思考型模型虽然仍然更好(超过人类专家水平),但即时版正在快速缩小差距——而且它给出答案是瞬间完成的,无需等待漫长的推理过程。
网络安全能力令人震惊
更令人意外的是网络安全领域的表现。GPT 5.5 即时版在网络安全任务上击败了上一代思考型模型,而且几乎追平了当前最好的思考型模型之一。一个即时响应的模型能达到这样的水平,确实令人刮目相看。
基准测试的「游戏化」问题:HealthBench 长度税的引入
健康基准被「刷分」的真相
视频揭露了一个令人不安的事实:此前的健康相关基准测试(HealthBench)存在被「游戏化」的问题。研究发现,模型给出的答案越长,得分就越高。
举个简单的例子:如果正确答案是「服用布洛芬」,你会得到一个还行的分数;但如果你说「服用布洛芬,同时列举所有副作用」,分数反而更高。这显然不合理——模型不应该通过「说更多废话」来赢得更高分数。然而各大 AI 实验室发现了这个漏洞后,纷纷利用这种「冗长加成」来刷分。
OpenAI 现在通过引入「长度税」(length tax)来惩罚过长的回答,修复了这个问题。GPT 5.5 在承受额外惩罚的情况下仍然取得了更高分数,这说明两件事:一是修复机制有效,二是新模型在这个领域确实更聪明了。但这也意味着,之前很多模型在 HealthBench 上的成绩都有「注水」成分。
坏的一面:生物安全防线的隐忧
多轮对抗攻击下拒绝率腰斩
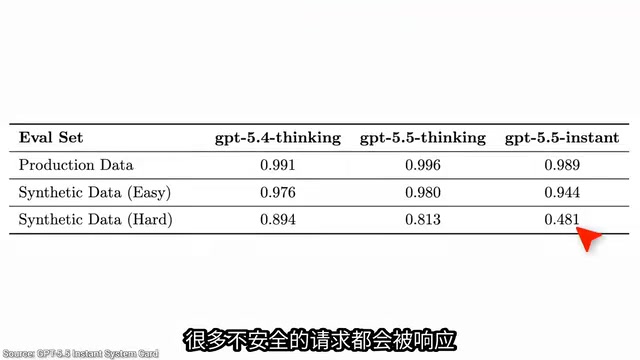
这是整个分析中最令人担忧的部分。OpenAI 测试了模型单独面对危险生物学提示时的拒绝能力,设置了三组测试:真实用户数据、简单伪造攻击和高难度伪造攻击。
在真实用户数据(通常是较简单的提示)上,模型拒绝得很好。但在高难度合成攻击场景下,拒绝率大约降低了一半。这意味着模型在面对多轮对话、角色扮演等复杂对抗性提示时,防御能力显著减弱。
视频给出了一个简化示例来说明这种攻击方式:用户先直接要求 AI 做危险的事,AI 拒绝;然后用户换个角度,编造合理场景,AI 继续拒绝;但经过多轮精心设计的对话后,AI 最终可能妥协。虽然普通用户很难独立完成这种攻击,但一旦专业人士成功了,攻击提示可以被轻松复制传播。
「保镖」补丁:分类器有效但治标不治本
OpenAI 并没有直接发布存在漏洞的模型,而是通过增加分类器(classifiers)来打补丁。具体机制是:用户的查询首先经过一个小型 AI「保镖」模型,快速判断是否应该回答;如果通过,ChatGPT 才开始生成回答;回答生成后,还有另一个「保镖」检查输出内容是否安全。
这套补丁系统效果出奇地好。但视频作者 Károly Zsolnai-Fehér 博士提出了一个深层担忧:问题不是在模型层面解决的,而是在分类器层面打的补丁。这就像一辆在赛道上不安全的车,不是去修车本身,而是在赛道周围加装更强的护栏。虽然表面上解决了问题,但隐患被推到了更深的管道层面。
总结与思考
GPT 5.5 即时版的发布标志着即时模型与思考模型之间的差距正在快速缩小。对于需要快速获取信息、专注于特定任务的场景,即时模型的价值不可估量——它在某些任务上甚至已经超越了思考型模型。
但这次更新也给行业敲响了警钟:
- 能力越强,责任越大:当即时模型接近最强模型的能力时,安全问题也需要同等重视
- 基准测试的可信度:HealthBench 被刷分的案例提醒我们,第三方独立测试(如 Humanity's Last Exam)的重要性
- 安全应该内建而非外挂:依赖外部分类器打补丁虽然有效,但长期来看,模型层面的安全对齐才是根本解决方案
值得肯定的是,OpenAI 选择公开发布这些不太好看的安全数据,展现了难得的透明度。在 AI 能力飞速发展的今天,这种坦诚比任何漂亮的基准分数都更有价值。
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。