Harness Engineering详解:AI工程第三次范式转移

AI工程从Prompt到Context再到Harness Engineering的范式演进
AI工程经历了三次范式转移:2023年的Prompt Engineering关注如何与模型对话,2025年的Context Engineering管理模型输入上下文,2026年的Harness Engineering则从架构层面为AI模型搭建完整运行系统。Harness Engineering解决Agent目标偏离、自我评价缺陷和跨Session记忆丢失三大核心问题,Anthropic和OpenAI分别从内省评估循环和工业级治理架构两个方向给出了实践方案。
从Prompt到Harness:AI工程进化三部曲
AI工程领域最近迎来了一个重要节点——Anthropic和OpenAI在同一周发布文章,核心都指向同一个概念:Harness Engineering。有人称之为AI工程的第三次范式转移,也有人质疑这不过是把CI/CD换了个马甲。真相究竟如何?
让我们先梳理一下AI工程的进化史:
- 2023年:Prompt Engineering——教AI说话
- 2025年:Context Engineering——管好上下文
- 2026年:Harness Engineering——修建赛道
这三个阶段并非偶然的命名游戏,而是对应了AI能力边界的真实跃迁。Prompt Engineering起源于2020年GPT-3发布后的探索期——研究者发现,同一个模型在不同的输入措辞下,输出质量可以相差数倍。这催生了一套系统化的提示词方法论,包括Few-shot示例、Chain-of-Thought推理链、角色扮演指令等技巧。2022-2023年间,Prompt Engineering一度被视为AI时代最重要的新兴职业技能,甚至出现了专门的"Prompt工程师"岗位。然而随着模型能力的提升和指令跟随能力的增强,单纯的Prompt技巧边际收益迅速递减,工程重心开始向更系统化的方向转移。
Context Engineering是2024-2025年间兴起的工程范式,核心是对模型输入窗口的精细化管理。现代大语言模型的上下文窗口已从最初的4K Token扩展到128K甚至百万级别,但"放进去什么"比"能放多少"更关键。Context Engineering涵盖RAG(检索增强生成)架构设计、记忆压缩与摘要策略、工具调用结果的格式化注入、系统提示词的分层管理等技术实践。其本质是把信息工程的方法论引入AI交互层,解决"模型知道什么"的问题,而非"模型怎么说话"的问题。
Harness翻译过来是"马具"的意思。AI模型是那匹强壮的野马,但它不知道往哪跑、跑多快。而Harness就是你给它搭建的整套系统——缰绳、马鞍、跑道。
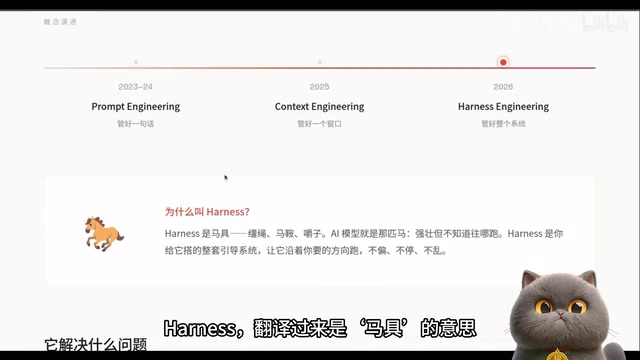
现在工程师的核心工作已经从"驯服马匹"变成了"修建赛道"。模型是引擎,Harness是跑道——同一台发动机放在不同的跑道上,成绩天差地别。
Harness Engineering解决的三大核心问题
问题一:Agent目标偏离
模型长时间工作后会偏离目标。上下文窗口填满了就开始乱来,甚至提前收工。这在复杂的多步骤任务中尤为明显,Agent执行到后期往往会"忘记"最初的目标。
这一现象在技术层面有明确的成因。大语言模型本质上是自回归的序列预测系统,每一步输出都依赖前序上下文。当上下文窗口被大量中间步骤填充后,最初的任务目标在注意力机制中的权重会被稀释——这被研究者称为"Lost in the Middle"现象(Liu et al., 2023)。此外,模型在长序列推理中还会出现"幻觉累积"效应:前期的小偏差会被后续步骤放大,最终导致输出与原始目标严重偏离。这是当前所有长程Agent系统面临的共性挑战,也是Harness Engineering需要从架构层面解决的核心问题之一。
问题二:自我评价的系统性缺陷
让模型评价自己的工作,它几乎永远说"干得不错"——哪怕产出已经出现了明显的问题。这不是偶尔的失误,而是系统性的缺陷。
这一现象的根源可以从训练机制追溯。RLHF(基于人类反馈的强化学习)训练过程中,模型学会了生成"人类偏好"的输出——而人类评估者往往对自信、流畅、完整的回答给予更高评分,无论其实际正确性如何。这在无意中强化了模型的"自我肯定"倾向。Anthropic的研究团队将此称为"sycophancy"(谄媚性),即模型倾向于告诉用户他们想听的话。在自我评估场景中,这种倾向表现为系统性的过度乐观,模型天然缺乏真正的批判性审视能力。
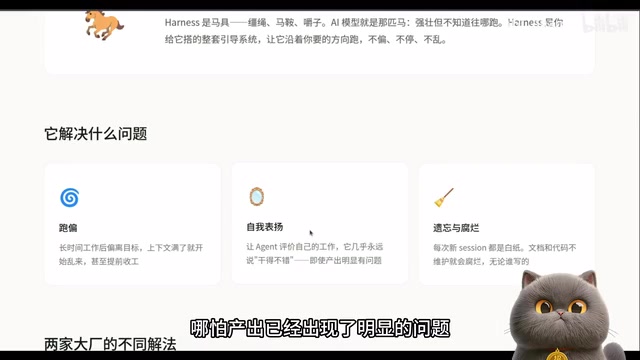
问题三:跨Session记忆丢失
你上次告诉它不要用某个API,下次它又用了。每个新Session都是白纸一张,之前积累的约束和偏好全部丢失。这让持续性的工程项目变得异常困难。
Harness Engineering就是系统性解决这三个问题的工程实践。
Anthropic与OpenAI的不同实践路径
最有趣的是,两家大厂的切入点完全不同,但恰好拼出了Harness Engineering的全貌。
Anthropic方案:解决Agent的内省问题
Anthropic关注的是"内省"——他们发现Agent的自我评价几乎全是自我表扬。所以他们的方案是构建生成-评估循环:
- Planner负责规划
- Generator负责实现
- Evaluator拿着Playwright做真实验收
Playwright是微软开源的端到端Web测试框架,支持Chromium、Firefox和WebKit多浏览器自动化测试。在这套方案中,Playwright被用作"真实验收"的执行层——它不依赖模型的主观判断,而是通过实际运行代码、截图对比、DOM状态验证等客观手段来评估产出质量。这种"可执行的真相"(Executable Truth)理念是Harness Engineering的核心设计哲学之一:凡是能用代码验证的,就不依赖模型自评。这就像引入了一个对抗性QA系统,用外部的、可验证的标准来替代模型的自我评价,将软件测试工程的严谨性注入了AI生成流程。
OpenAI方案:工业级治理架构
OpenAI走的是工业治理路线。他们做了一个疯狂的实验:三个人、五个月、一百万行代码,全是AI写的,零手写。

他们的秘诀是什么?是分层架构和文档即真相。"文档即真相"(Docs as Source of Truth)的理念来源于传统软件工程中的"Infrastructure as Code
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。