Hugging Face开源Agent生态全解:从本地部署到AI自动训练

Hugging Face构建开源Agent生态,让AI自动完成模型训练与部署
Hugging Face在AI Engineer大会上展示了其开源Agent生态系统的最新进展。演讲指出开源模型性能已追平闭源模型,并具备透明度和可控性优势。Hugging Face推出了Skills系统,让Agent能通过对话自动完成模型训练、部署和数据处理;同时提供多种本地部署方案和MCP协议集成,配合Agent Traces形成数据飞轮,正在根本性地改变AI工程师的工作方式。
在最近的AI Engineer大会上,Hugging Face开源团队成员Merve带来了一场关于开源Agent生态系统的精彩演讲。她展示了一个令人振奋的愿景:通过Hugging Face Hub的一系列新功能和Skills技能,开发者可以让AI Agent自动完成模型训练、部署和数据处理等复杂任务——这在几年前还是科幻级别的操作。
开源模型已追平闭源:不再是二等公民
演讲开篇,Merve首先澄清了一个长期存在的误解:开源模型不如闭源模型。她引用了人工智能指数(Artificial Intelligence Index)的数据,指出开源模型(绿色标记)已经追上了闭源模型(黑色标记)的表现。人工智能指数是由斯坦福大学人类中心人工智能研究所(HAI)每年发布的综合性报告,追踪AI领域的技术进展、经济影响和政策动态,是业界公认的权威参考。以最新的GLM 5.1为例,该模型由智谱AI(Zhipu AI)开发,采用了混合专家(MoE)架构,在保持高性能的同时显著降低了推理成本,在多个基准测试中表现优异,甚至在SWE Bench等编程基准中位列榜首。SWE Bench由普林斯顿大学研究团队推出,从真实的GitHub开源项目中提取软件工程任务,要求模型理解代码库上下文并生成正确的补丁修复——这被认为是衡量AI编程实力最具说服力的测试之一。

开源模型的优势不仅在于性能,更在于透明度和可控性。Merve特别提到,近期有闭源模型被发现性能悄然下降——如果一切都是开源的,这种情况根本不会在用户不知情的情况下发生。此外,开源模型还支持量化压缩、微调定制,以及部署到边缘设备和浏览器,从根本上保障了用户数据隐私。量化压缩是将模型参数从高精度浮点数(如FP16的16位)转换为低精度表示(如INT4的4位)的技术,可以将模型体积缩小到原来的四分之一甚至更小,同时大幅降低显存需求和推理延迟,代价仅是微小的精度损失。而边缘部署则意味着模型直接运行在终端设备上,数据无需上传云端,从架构层面保障了隐私安全。
一个值得关注的趋势是:越来越多的模型在发布首日就具备视觉能力。Gemma 4、Qwen 2.5、Kimi K2.5等模型都是视觉语言模型(VLM),Merve预测未来所有主流模型都将在发布时自带视觉能力。视觉语言模型的核心架构通常由视觉编码器(如ViT)、语言模型和连接两者的投影层组成,早期的VLM如CLIP只能做图文匹配,而新一代VLM已能进行复杂的视觉推理、文档理解和GUI操作。这对Agent应用意义重大——视觉LM可以充当计算机操作Agent,理解截图内容并知道在哪里点击。具体来说,计算机操作Agent需要"看懂"屏幕截图,识别按钮、输入框等UI元素的位置,然后生成精确的鼠标点击和键盘输入指令,本质上是将视觉理解能力转化为可执行的操作序列。
本地Agent部署:多种方案任你选
对于想要在本地运行AI Agent的开发者,Hugging Face生态提供了丰富的部署选择。

Plandex(Pi)与LLama Agents
Merve推荐的方案之一是Pi,因为它设置极其简单。开发者可以通过Hugging Face Inference Providers远程调用,也可以用LLama CPP在本地提供服务,Pi会直接消费该服务。Hugging Face Inference Providers是Hub提供的统一推理API,开发者可以通过同一接口调用不同后端(如AWS、Google Cloud、Together AI等)托管的模型,无需关心底层基础设施差异。而llama.cpp是由Georgi Gerganov开发的开源项目,用纯C/C++实现了LLM推理,无需依赖Python或GPU驱动框架,可在CPU、Apple Silicon、NVIDIA GPU甚至Android设备上高效运行,催生了包括LM Studio、Ollama在内的庞大本地推理生态。另一个亮眼的选择是LLama Agents——它作为LLama CPP的内置二进制文件,只需给出Hugging Face Hub的模型ID就能直接启动Agent。
Hermes Agents:功能最全面的开源方案
Merve在演讲中毫不掩饰对Hermes Agents的偏爱。相比开源版Claude,Hermes在记忆管理等方面更进一步。它的设置向导会引导你完成所有配置——输入密钥、集成到Slack或WhatsApp,即可开始使用。
一个有趣的实战案例:Merve在集成Slack时遇到了问题,她让GLM 5.1通过Hermes Agent自行修复,结果模型成功解决了问题。这充分说明了开源模型在Agent场景下的实用性。
模型选择与硬件适配
Hugging Face Hub提供了强大的模型筛选功能。在"Other"标签下的Apps分类中,你可以找到LM Studio、Ollama、LLama CPP等所有本地部署工具支持的模型。
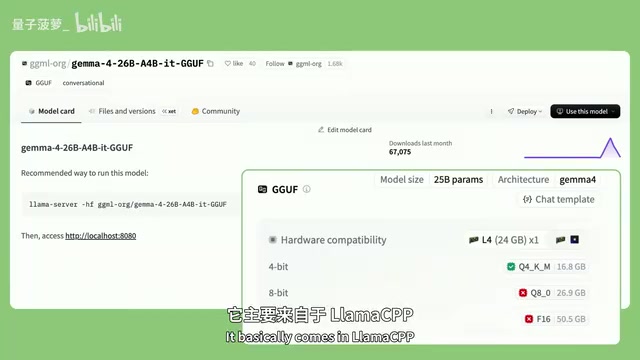
模型仓库页面现在会显示GGUF格式的硬件兼容性信息。GGUF(GPT-Generated Unified Format)是由llama.cpp项目创建的模型格式,专为CPU和消费级GPU推理优化,支持多种量化级别(从Q2_K到Q8_0),已成为本地部署的事实标准格式。例如,Gemma 4的大模型量化到4-bit后,可以装进24GB显存的L4 GPU中。页面右上角的"Use this model"按钮会直接给出对应本地工具的安装和启动命令,几行代码就能跑起来。
Skills系统:让Agent自动训练模型
这是整场演讲最令人兴奋的部分。Hugging Face推出了一套Skills系统,让编程Agent能够直接管理Hub仓库、启动训练任务、构建Demo等。
LLM Trainer Skill:对话式模型训练
LLM Trainer Skill不仅支持大语言模型,还支持视觉语言模型的训练。Merve演示了一个完整流程:她在Claude Code中输入"帮我用LLaVA Instruct Mix数据集训练Qwen2-VL",Agent随即开始工作:
- 自动计算资源需求:Agent在后台计算训练所需的显存、批次大小等参数
- 交互式确认:询问用户选择哪种GPU实例、验证集划分等关键问题
- 远程启动训练:在Hugging Face基础设施上启动训练任务
- 模型自动上传:训练完成后模型直接出现在Hub上
对于一个从业六年的模型训练老手来说,Merve坦言这仍然像科幻一样不可思议。传统的模型训练流程需要手动编写训练脚本、配置分布式训练环境、调试超参数、处理数据格式兼容性等大量繁琐工作,而Skills系统将这些专业知识封装为Agent可调用的技能,极大降低了门槛。这套技能不限于LLM——她最近还发布了目标检测器和分割模型的训练技能,能自动处理不同的标注框格式(如COCO格式的[x, y, width, height]与Pascal VOC格式的[xmin, ymin, xmax, ymax]之间的转换)等细节。
基准测试与OCR技能
新推出的Benchmark数据集功能让模型选择更加科学。在数据集页面左侧底部点击Benchmark按钮,即可查看SWE Bench Pro、Humanities Last Exam、AIME等热门基准的排名。AIME(American Invitational Mathematics Examination)是美国数学邀请赛,近年来被广泛用于评估AI模型的数学推理能力,因为其题目需要多步推理和创造性思维,远超简单的算术计算。
更进一步,你可以直接问Agent"OCR任务最好的模型是什么?",它不仅会给出推荐,还会根据你的需求(如需要更小的模型)提供微调建议。
MCP集成与实战案例

Hugging Face Hub现在提供了MCP Server,可以将Hub直接接入你的LLM工作流。MCP(Model Context Protocol,模型上下文协议)是由Anthropic于2024年底开源的标准化协议,旨在解决LLM与外部工具和数据源之间的连接问题。在MCP出现之前,每个AI应用都需要为每个外部服务编写专门的集成代码,形成M×N的复杂度;MCP采用客户端-服务器架构,定义了统一的工具调用、资源访问和提示模板接口,将复杂度降为M+N。通过MCP协议,你可以搜索模型、数据集、Spaces(Merve称之为"AI的App Store"),还能直接查询Spaces中的应用。
Hugging Face Spaces是一个托管AI应用的平台,开发者可以用Gradio、Streamlit或Docker部署交互式Demo,目前已托管超过40万个应用,涵盖图像生成、语音合成、文档处理等各个领域。每个Space都可以通过API被其他应用或Agent调用,这正是Merve将其比作"AI的App Store"的原因。
一个生动的例子:Merve在Agent中输入"生成一张用毛线做的巴克拉瓦甜点图片",Agent自动调用了Hub上托管的Qwen Image生成模型,返回了生成结果。要使用更多Spaces功能,需要在MCP设置中开启"dynamic spaces"选项。
实战:用Agent OCR处理3万篇论文
Merve的同事Nils用这套生态完成了一个实际项目:为Hugging Face Papers上的3万篇论文进行OCR处理。OCR(Optical Character Recognition,光学字符识别)在学术论文场景下面临特殊挑战——论文中包含大量数学公式、表格、图表和多栏排版,传统OCR工具往往难以准确处理这些复杂版式。整个流程完全通过提示词驱动:
- 通过基准数据集选择最佳OCR模型(Chandra OCR)
- 让Agent编写处理脚本
- Agent自动计算所需实例规格和运行成本
- 在Hugging Face基础设施上启动批处理任务
- 结果存储到新推出的Bucket服务(类似S3但更便宜更快)
Bucket服务是Hugging Face新推出的对象存储方案,针对AI工作负载优化,支持更大的单文件上传、更快的跨区域传输,且价格低于主流云存储服务,对于存储大规模处理结果、训练数据集和模型检查点等场景尤为实用。
总结与展望
Hugging Face正在构建一个完整的开源Agent生态系统,从模型选择、本地部署、远程推理到自动化训练,每个环节都在降低使用门槛。Agent Traces功能让你可以记录和复用Agent的执行轨迹,甚至用这些轨迹数据训练新模型,形成正向循环。Agent Traces是记录Agent完整执行过程的结构化日志,包括每一步的推理过程、工具调用、中间结果和最终输出。这些轨迹数据的价值远超调试用途:它们可以作为高质量的训练数据,用于微调更小、更高效的专用Agent模型。这形成了一个"数据飞轮"——Agent执行任务产生轨迹数据,轨迹数据训练出更好的模型,更好的模型执行更复杂的任务,产生更高质量的轨迹数据。这种正向循环是开源生态相对闭源的独特优势,因为整个过程的每个环节都是透明和可复现的。
开源AI的黄金时代正在到来——不仅模型性能追平闭源,工具链的成熟度也在快速提升。当你可以用一句话让Agent帮你训练模型时,AI工程师的工作方式正在发生根本性的改变。
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。