Kimi K2.5全量开源:1T参数MoE架构+Agent集群能力深度解析

月之暗面全量开源1T参数Kimi K2.5,登顶开源榜首并挑战闭源巨头。
月之暗面于1月27日全量开源Kimi K2.5,该模型采用1T参数MoE架构,在AI编程和多模态理解上登顶开源榜首,部分测试超越GPT-4O和Claude 3.5 Sonnet。其核心亮点包括视觉编程能力(从截图、草图直接生成高保真代码)和Agent集群机制(最多100个Agent并行处理复杂任务),大幅降低开发门槛并革新工作模式,标志着开源模型打破闭源垄断格局。
月之暗面在1月27日放出了一个重磅炸弹——Kimi K2.5全量开源。这不是一次简单的模型开放,而是一个拥有1T参数MoE架构、具备Agent集群能力的顶级大模型,直接面向全球开发者免费开放。在AI编程和多模态理解等核心赛道上,K2.5登顶开源榜首,部分测试甚至超越了GPT-4O和Claude 3.5 Sonnet。这意味着什么?开源社区终于迎来了一个能与闭源巨头正面硬刚的满血版模型。
Kimi K2.5视觉编程:从截图到代码的降维打击
Kimi K2.5最令人瞩目的能力之一,是其视觉编程(Vision-to-Code)能力的突破性进展。传统的AI编程辅助工具需要用户用自然语言详细描述需求——页面布局、交互逻辑、样式细节,每一项都需要精确表达,沟通成本极高。
而K2.5彻底改变了这个范式。你可以直接丢给它一张网页截图、一段屏幕录制,甚至是在餐巾纸上随手画的草图,它就能从设计到代码进行1:1的高保真还原。这不仅仅是简单的图像识别加代码生成,而是融合了多模态理解、UI布局分析、前端工程化等多项能力的综合体现。
视觉编程能力的实现依赖于多模态大模型的深度融合。早期的多模态模型(如CLIP)主要专注于图文匹配,而现代多模态大模型则需要理解像素级的空间关系、UI组件层级、CSS布局逻辑等复杂信息。这一能力的突破离不开大规模UI数据集的训练,包括网页截图与对应HTML/CSS代码的配对数据,以及设计稿与前端实现的对齐数据。微软的Screenshot-to-Code项目和Anthropic的Claude在这一方向上均有探索,但K2.5将其提升到了可直接处理手绘草图的程度,意味着模型具备了更强的抽象理解与意图推断能力,而非简单的像素级模式匹配。

这项能力的意义在于,它将软件开发的门槛从"会写代码"降低到了"能画草图"。对于产品经理、设计师、创业者来说,从想法到原型的距离被压缩到了几分钟。对于专业开发者而言,前端页面的还原工作也可以大幅提效。可以说,这是AI编程从"辅助写代码"进化到"理解意图、自主实现"的关键一步。
Agent集群并行处理:AI开始"团伙作案"
如果说视觉编程是K2.5的"硬实力",那么Agent集群机制则是它真正的"杀手锏"。
传统的AI助手工作模式是单线程的——你给一个任务,它一步步执行,遇到复杂问题就容易卡壳或者质量下降。Kimi K2.5采用了一种全新的架构思路:面对复杂任务时,它会自动拆解任务,并召唤多达100个Agent分身进行并行处理。
多Agent并行协作系统(Multi-Agent System)是AI工程领域的前沿方向,其理论根基可追溯至分布式人工智能(DAI)研究。在大语言模型时代,AutoGPT、LangChain、CrewAI等框架率先探索了多Agent协作的工程实现,但早期方案普遍面临Agent间通信开销大、任务分解质量不稳定、错误传播难以控制等问题。K2.5的Agent集群机制在架构层面进行了深度优化:通过主控Agent(Orchestrator)负责任务拆解与结果聚合,子Agent(Worker)专注于原子化任务执行,并引入了并行调度机制以最大化资源利用率。支持最多100个Agent同时运行,意味着其底层需要解决大规模并发状态管理、上下文隔离与结果一致性等工程难题,这也是K2.5区别于同类产品的核心技术壁垒之一。
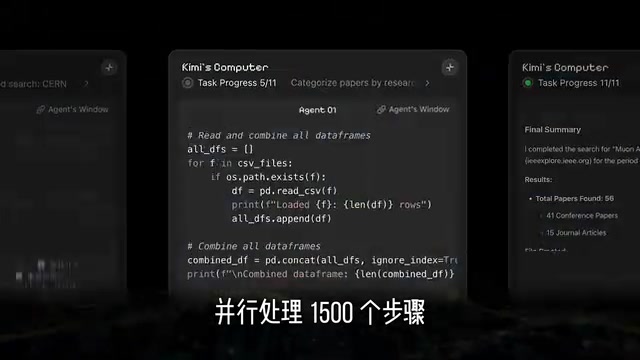
这种"摇人模式"的威力有多大?来看几个实际应用场景:
- 批量调研:同时调研100家上市公司的财务数据、业务动态,并行抓取、分析、汇总
- 论文综述:批量下载上百篇学术论文,提取关键信息,生成结构化的文献综述
- 数据处理:1500个步骤的复杂数据处理流程,多个Agent协同完成
以前一个研究团队需要一周才能完成的工作量,K2.5的Agent集群在十几二十分钟内就能搞定。这不是简单的效率提升,而是工作模式的根本性变革——从"人指挥AI干活"变成了"AI自主组队、协同作战"。
MoE架构与开源的战略意义:打破闭源垄断
Kimi K2.5选择全量开源,这个决策的战略意义远超技术本身。

长期以来,开源大模型与闭源商业模型之间存在着明显的能力鸿沟。开发者和企业面临一个尴尬的选择:要么付费使用GPT-4级别的闭源模型,要么退而求其次使用能力打折的开源替代品。K2.5的出现打破了这个格局——它证明了开源模型完全可以达到甚至超越顶级闭源模型的水平。
开源大模型生态的演进经历了几个关键节点:Meta于2023年发布LLaMA系列,首次将高质量基础模型带入开源社区;Mistral随后以小参数量高性能模型证明了开源路线的可行性;DeepSeek系列则在代码和数学推理上实现了对闭源模型的局部超越。然而,在综合能力(尤其是多模态与Agent能力)上,开源模型与GPT-4o、Claude 3.5 Sonnet之间始终存在可感知的差距。这一差距的根源在于:顶级闭源模型背后有数亿美元的RLHF(基于人类反馈的强化学习)数据标注投入,以及专有的后训练对齐技术。K2.5的开源不仅是参数权重的开放,更重要的是将这一能力级别的模型纳入了开源社区可研究、可改进的范畴,对学术界和工业界的影响将是深远的。
从技术架构来看,K2.5采用了1T参数的MoE(Mixture of Experts,混合专家)架构。MoE的核心思想源自1991年Jacobs等人提出的混合专家系统,但在大语言模型时代被Google、DeepMind等机构重新发扬光大。MoE的关键机制是"稀疏激活":模型由数十乃至数百个"专家"子网络组成,每次推理时由一个轻量级的"路由器"(Router)根据输入内容动态选择2-8个最相关的专家参与计算,其余专家保持休眠状态。这意味着虽然K2.5拥有1T总参数,但单次推理实际激活的参数量可能只有其中的1/8甚至更少,大幅降低了计算资源消耗。Google的Gemini 1.5、Mistral的Mixtral系列以及DeepSeek-V2都采用了类似架构,验证了MoE在兼顾模型能力与推理效率方面的巨大潜力。这使得K2.5在实际部署中具备了较好的性价比,为中小企业和个人开发者的本地化部署提供了可能性。
Kimi K2.5实际体验与未来展望
目前,用户可以通过Kimi官网和Kimi Code两个入口体验K2.5的能力。对于开发者来说,全量开源意味着可以基于K2.5进行二次开发、微调和定制化部署,这为各行各业的AI应用落地提供了坚实的基础设施。
从更宏观的视角来看,K2.5的开源标志着中国大模型生态进入了一个新阶段。它不再是简单的"追赶",而是在特定赛道上实现了"领跑"。Agent集群的并行处理能力,更是将"数字员工"从概念阶段推进到了人人可用的实践阶段。
当然,开源模型的真正价值需要时间来验证——社区的采用程度、实际生产环境中的稳定性、生态工具链的完善程度,这些都是决定K2.5能否真正成为开源标杆的关键因素。但无论如何,月之暗面这一步,走得既大胆又扎实。
核心要点
- Kimi K2.5全量开源,采用1T参数MoE架构,在AI编程和多模态理解赛道登顶开源榜首,部分测试超越GPT-4O和Claude 3.5
- 视觉编程能力实现突破,支持从截图、录屏甚至手绘草图直接生成高保真代码,大幅降低软件开发门槛
- Agent集群机制支持最多100个Agent并行处理复杂任务,将团队一周的工作量压缩至十几分钟完成
- 全量开源打破闭源模型垄断格局,为开发者和企业提供免费的顶级大模型基础设施
- 标志着中国大模型从追赶走向领跑,将数字员工从概念推进到人人可用的实践阶段
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。