扣子智能体实战:从零搭建AI测试用例生成工作流
引言:为什么测试工程师需要关注智能体
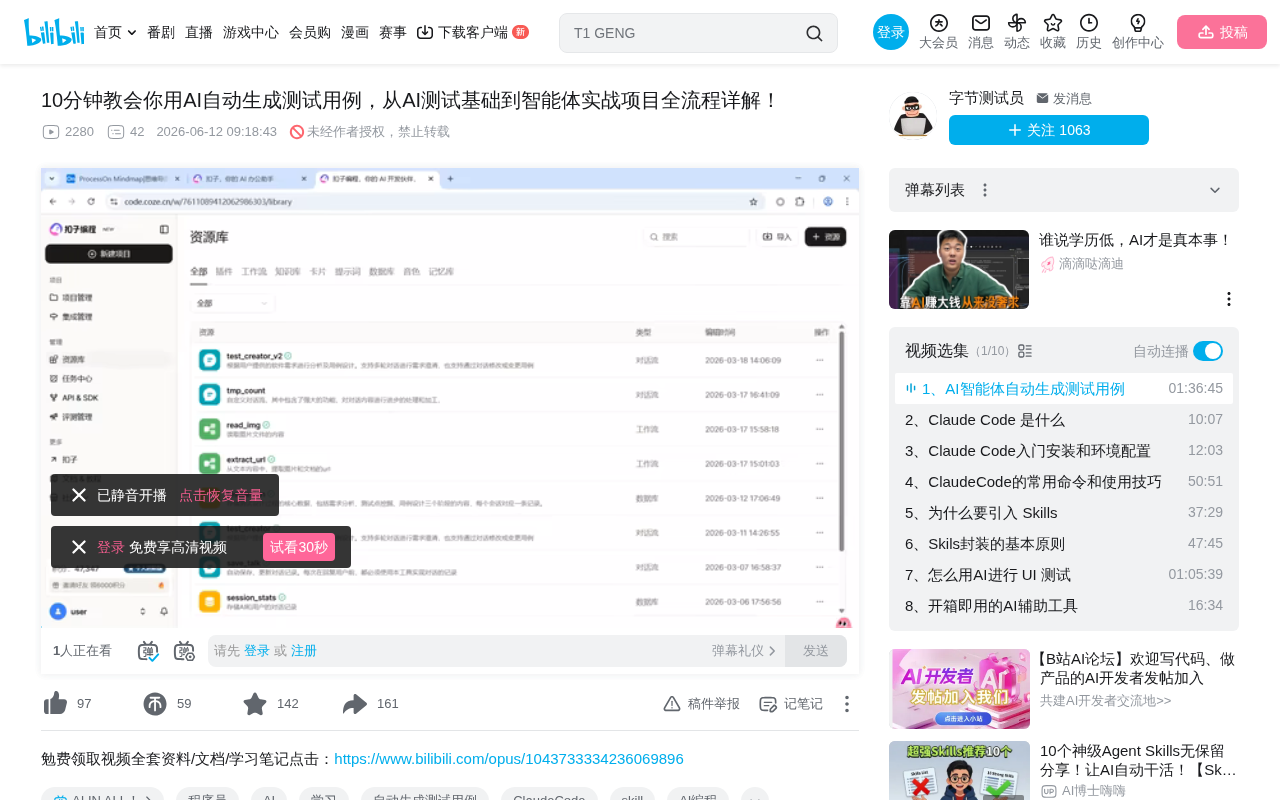
AI大模型的应用已经从简单的文字问答,逐步演进到智能体(Agent)阶段。对于软件测试工程师而言,这意味着一个重要的转变:AI不再只是帮你回答问题的聊天工具,而是可以自主完成「需求分析→测试点挖掘→用例设计→代码生成→结果汇报」整条链路的智能助手。
本文基于B站一位测试领域讲师的实战演示,系统梳理了如何利用扣子(Coze)平台搭建测试用例自动生成的智能体,并深入分析了智能体与传统AI对话的本质区别、工作流编排的核心技巧,以及实际落地中的经验教训。
智能体与大模型的两个关键区别
区别一:能调用外部工具与现实世界交互
直接使用DeepSeek、千问、ChatGPT等大模型的网页版时,你输入文字,它输出文字——仅此而已。它无法查询实时天气、无法读取你的文件、无法操作外部系统。
而智能体的核心突破在于:它可以调用外部工具与现实世界产生交互。在扣子平台中,这些工具以「插件」的形式存在,包括联网搜索、天气查询、文件读取、图片理解、飞书表格操作等。例如,当你问智能体"北京3月18日天气怎么样",它会自动调用天气查询插件获取真实数据,而不是凭训练数据猜测。
区别二:能自主持续推进任务
使用DeepSeek时,每一轮对话都是「回合制」的——你问一句,它答一句,然后停下来等你的下一条指令。如果你不继续推动,流程就永远停在那里。
智能体则不同。它可以根据上一步的输出结果,自动决策并推进到下一步,直到整个任务完成。 这正是通过「工作流」实现的:你预先编排好任务链条,智能体就会像流水线一样自动执行每个环节。
扣子平台的三种智能体创建模式
扣子提供了三种智能体创建模式,适用于不同场景:
自主规划模式(单Agent)
这是最接近传统AI对话的模式。你为大模型提供一系列插件和工作流,由AI自主决定何时使用哪个工具。优点是灵活,缺点是结果具有随机性——因为大模型底层是概率模型,每次决策可能不同。
适合场景:初学者探索和体验阶段。
对话流模式
与自主规划不同,对话流模式要求你严格编排好执行流程,智能体会一步步按照预设路径执行,不会自行发散。这牺牲了一定的自主性,但换来了结果的确定性和可控性。
适合场景:已经验证过可行性,需要稳定输出的企业级应用。
多Agent协作模式
当单个智能体无法胜任复杂任务时,可以让多个智能体协作——一个负责执行、一个负责监督、一个负责质量检查。这属于进阶用法,适合后期复杂场景。
选择建议: 刚入门选自主规划模式;有明确流程和目标选对话流模式;需要多角色协作选多Agent模式。
工作流编排:测试用例生成的核心环节
基本结构与容易忽略的细节
每个工作流都有一个起点和终点。最简单的形式是「回音壁」——输入什么就输出什么。但实际应用中,我们需要在中间插入AI大模型节点进行智能处理。
关键细节往往被忽略:结束节点接收到数据,并不等于使用了数据。 你必须在输出配置中明确引用变量,否则即使数据已经传递到位,也不会出现在最终输出中。此外,建议开启「流式输出」,让结果逐步呈现而非等待全部生成后一次性显示。
实战案例:完整的测试用例生成工作流
一个完整的测试用例生成工作流包含以下环节:
- 意图识别 —— 判断用户输入是新需求、需求补充、用例修改还是闲聊
- 需求分析 —— 使用AI提取业务需求关键信息,要求JSON格式输出以确保结构化
- 风险评估 —— 检查需求是否存在矛盾、缺漏或不完整
- 人工干预节点 —— 允许用户选择忽略风险继续推进(现实中需求确实经常不完整)
- 测试点挖掘 —— 基于需求分析结果深度挖掘测试场景
- 用例设计 —— 生成结构化的测试用例
- 文件生成 —— 通过插件将结果导出为PDF、Excel或写入飞书表格
提示词工程对输出质量的决定性影响
系统提示词直接决定了AI的输出质量。例如:
- 设定「回复内容不超过10个字」,AI就会严格遵守字数限制
- 要求「为每个用例标注优先级、重要程度和预估工期」,输出就会包含这些字段
- 指定「使用JSON格式输出」,可以避免AI用聊天口吻或不确定的格式回复
在需求分析节点,提示词应明确角色定位(如"你是一个需求分析工程师")和输出规范;在用例设计节点,则应包含团队的具体要求。
模型选择策略与三种输出方式对比
如何选择合适的大模型
扣子平台提供了多种大模型,选择时需关注几个标签:
- 图片理解/视频理解:如果需要分析原型图,必须选择支持多模态的模型(DeepSeek不支持图片理解)
- 深度思考:推理能力更强但速度更慢,适合关键环节
- 上下文缓存:对同一话题反复追问时效率更高
- Pro vs Mini/Lite:参数量大的模型能力强但慢,轻量模型速度快但能力有限
实用原则: 在风险评估等辅助环节用普通模型,在测试点挖掘和用例设计等核心环节用高质量模型。
三种输出策略的对比分析
| 策略 | 方式 | 速度 | 质量 | 成本 |
|---|---|---|---|---|
| 直接输出 | 一个模型一次性生成最终结果 | 最快 | 一般 | 最低 |
| 分步输出 | 一个模型按步骤逐步生成 | 适中 | 较好 | 适中 |
| 分布式输出 | 多个模型各负责一个环节 | 最慢 | 最好 | 最高 |
分布式输出之所以质量最高,有两个原因:每个模型的任务职责单一,且每个环节都能使用完整的上下文窗口。这与DeepSeek的深度思考原理类似——不急于给出最终答案,而是分步推导。
建议: 业务验证阶段用直接输出快速试错;追求质量且不差算力时用分布式输出;日常使用分步输出取得平衡。
云端智能体的局限与本地化替代方案
扣子作为云平台智能体有一个明显短板:无法直接访问本地电脑的文件系统和内网环境。 这意味着它无法读取本地需求文档、无法在本地生成和执行自动化测试代码、无法访问仅限内网的测试环境。
对于需要更深度集成的场景,可以考虑以下本地化方案:
- 基于LangChain等框架开发本地化智能体
- 使用类似OpenClaw这样部署在本地电脑上的智能体工具
本地化方案可以直接读取电脑中的需求文档,在本地生成和执行自动化代码,访问内网测试环境——这是云端方案无法替代的能力。
实际踩坑经验与解决思路
在演示过程中,工作流因单个模型运行超过3分钟而超时失败。这是一个典型的实战问题,解决思路有两个:
- 优化提示词,减少AI的推理深度,缩短单节点运行时间
- 使用异步任务节点替代同步节点,避免超时限制
此外,工作流的描述文字对自主规划模式至关重要——它是AI决定是否调用该工作流的唯一依据。对话流模式下描述可以简略,但普通工作流必须详细说明用途和触发条件。
总结
智能体代表了AI应用从「问答工具」到「任务执行者」的质变。对于测试工程师而言,掌握智能体的构建能力不仅能提升当前工作效率,更是进入AI测试领域的必备技能。从扣子这样的低代码平台入手理解核心概念,再逐步过渡到本地化开发,是一条务实的学习路径。
相关推荐
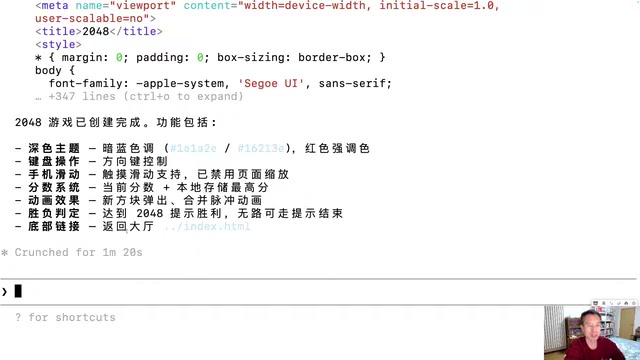
一句话提示词生成10款网页游戏:Claude Code实战体验
资深开发者用Claude Code命令行工具,仅凭一句话自然语言提示词,在一小时内生成2048、五子棋、俄罗斯方块等10款可玩网页游戏并部署上线。深度解析AI编程的真实能力与局限。

测试人必备的Cursor Skills五大技能包详解
详解测试工程师必备的五大Cursor Skills技能包,覆盖PRD需求分析、用例生成、JMeter脚本自动化、压测报告一键输出、Web自动化测试全流程,助你从执行者升级为质量架构师。
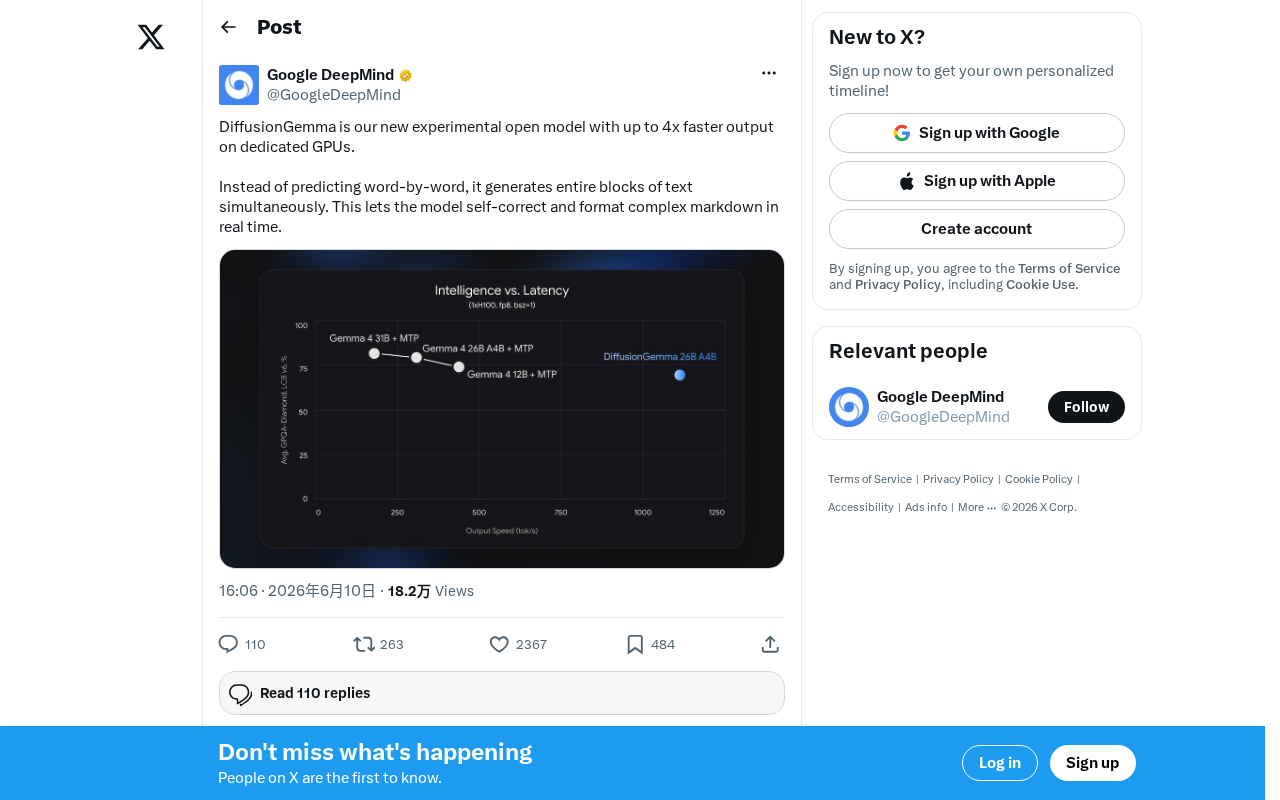
DiffusionGemma:谷歌开源扩散式语言模型,推理速度提升4倍
谷歌发布开源扩散式语言模型DiffusionGemma,将扩散模型思路引入文本生成,实现最高4倍速度提升与实时自我纠错能力。本文详解其核心技术原理、与传统自回归模型的差异及行业影响。