LangChain核心架构解析:五大模块从入门到实战

LangChain框架的核心架构、五大模块与应用场景全面解析
LangChain是当前最热门的LLM应用开发开源框架,通过模块化设计将复杂AI开发流程简化。其核心价值包括统一接口简化开发、组件化设计、强大生态集成、支持生产部署,以及RAG和Agent等创新功能。文章重点介绍了模型I/O模块(统一大模型调用接口)和数据连接与检索模块(文档加载、文本分割、嵌入模型等),帮助开发者构建高效智能应用。
LangChain 是当前 AI 应用开发领域最热门的开源框架之一,正在深刻改变开发者构建大语言模型(LLM)应用的方式。它将复杂的 AI 开发流程模块化,像乐高积木一样让开发者快速搭建出功能强大的智能应用。本文将系统梳理 LangChain 的核心架构、五大模块以及典型应用场景,帮助你建立对这一框架的完整认知。
什么是大语言模型(LLM)? 大语言模型是基于 Transformer 架构、经过海量文本数据训练的深度学习模型。自 2020 年 OpenAI 发布 GPT-3 以来,LLM 的参数规模从亿级跃升至千亿级,涌现出理解、推理、生成等多种能力。然而,LLM 也存在固有局限:训练数据有截止日期导致知识过时、容易产生"幻觉"(Hallucination,即生成看似合理但实际错误的内容)、单次处理的上下文长度有限等。正是这些局限催生了 LangChain 等框架的需求——通过工程化手段弥补模型本身的不足,让 LLM 在实际业务场景中真正可用。
LangChain的核心价值:为什么它如此重要
LangChain 覆盖了从想法构思到产品上线的完整开发链路,无论是智能客服、数据分析助手,还是 AI 创作工具,都能在这个框架下高效实现。其核心价值可以归纳为五个方面:
第一,简化开发流程。 以往对接不同大模型和数据库需要处理各异的 API 和参数格式,LangChain 提供了一套统一的标准接口,就像给不同品牌的电器配了通用插座,插上即用。
第二,组件化与模块化设计。 复杂的 AI 应用可以拆分为数据处理、模型推理、结果展示等独立模块,各模块可以单独开发测试,再灵活组合。
第三,生态集成能力强大。 LangChain 与主流 LLM 提供商(OpenAI、Anthropic、Google等)、各类数据库和 API 深度打通,几乎你想用的模型和数据源都能找到对应的集成插件。
第四,支持生产化部署。 通过 LangServe 等工具,开发好的应用可以顺利部署到生产环境,真正跑起来服务用户。
第五,催生创新应用。 RAG(检索增强生成)和 Agent(智能体)等高级功能,让 AI 不仅能理解上下文,还能主动检索外部知识、做出决策,催生出大量前所未有的智能应用。
LangChain 的发展历程 LangChain 由 Harrison Chase 于 2022 年 10 月作为开源项目发布,凭借其模块化设计和活跃的社区迅速成为 LLM 应用开发的事实标准,GitHub 星标数在一年内突破 8 万。其生态系统包含三个核心产品:LangChain(核心框架)、LangServe(将 Chain 和 Agent 部署为 REST API 的工具)和 LangSmith(用于调试、测试、评估和监控 LLM 应用的可观测性平台)。2023 年,LangChain 推出了 LangChain Expression Language(LCEL),采用声明式的链式语法,显著提升了流式输出、并行执行和异步处理能力,标志着框架从快速原型工具向生产级基础设施的演进。
模型I/O模块:统一的大模型调用接口
模型 I/O 是 LangChain 的基石模块,解决的是大模型调用的碎片化问题。当前市面上的大模型种类繁多——OpenAI GPT、Anthropic Claude、Google Gemini、百度文心一言、阿里通义千问,每家的 API 和参数格式都不一样。如果每次切换模型都要重写大量代码,开发效率将大打折扣。
LangChain 的模型 I/O 模块提供了一个统一的抽象层,充当"翻译官"的角色。不管底层调用的是哪家模型,开发者都可以用同一套代码完成调用,轻松切换甚至同时对比多个模型的效果。这种"供应商无关性"对企业尤其重要,既避免了技术锁定,也为未来集成新模型留足了扩展空间。
数据连接与检索:给AI装上外置硬盘
让 AI 仅凭自身训练数据回答问题,往往不够准确,也容易产生"幻觉"。数据连接与检索模块正是为了解决这个痛点而设计的,也是 LangChain 在 RAG 场景中的核心竞争力。
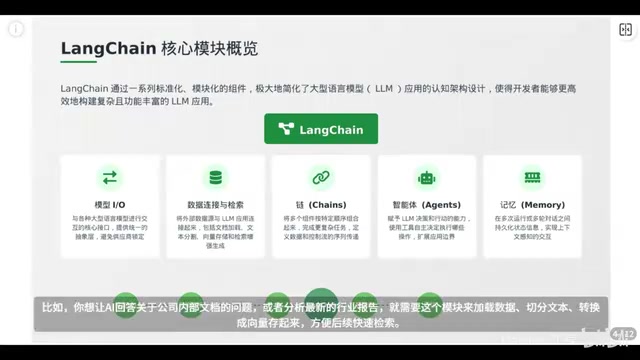
这个模块包含四个关键组件:
- 文档加载器(Document Loader):从 Word、PDF、网页、数据库甚至企业私有文档库中读取数据,整理成统一格式。
- 文本分割器(Text Splitter):由于大模型一次处理不了过长的文本,需要将长文档切分成适当大小的片段。

为什么必须切分文本? 这与 LLM 的上下文窗口(Context Window)限制密切相关。Transformer 架构的自注意力机制计算复杂度与序列长度的平方成正比,处理超长文本的计算成本急剧上升。尽管 GPT-4 Turbo 已支持 128K Token、Claude 3 支持 200K Token,但研究表明 LLM 存在"迷失在中间"(Lost in the Middle)问题——对位于超长上下文中间部分的信息提取能力显著下降。因此,将文档切分为合适大小的片段(通常 512-1024 Token),精准检索最相关的部分注入上下文,仍然是比"塞入全文"更高效、更准确的工程策略。
- 嵌入模型(Embedding Model):将文字转换为向量表示,捕捉语义信息。例如"苹果"和"水果"在向量空间中距离较近,而与"手机
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。