李宏毅2026课程笔记:AI Agent三大核心能力深度解析
李宏毅教授系统剖析AI Agent三大核心能力:记忆、工具使用与规划。
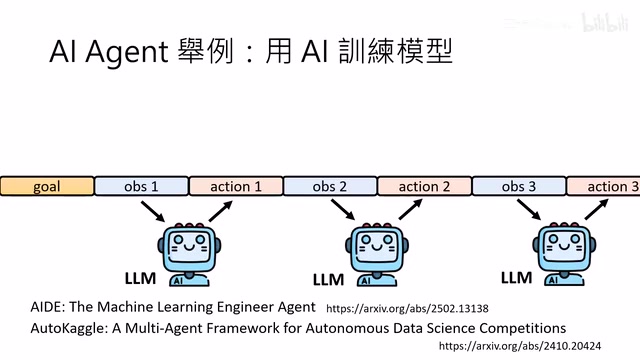
李宏毅教授在2026年最新课程中定义AI Agent为:人类只给目标,AI自主决定步骤达成目标。课程指出LLM驱动的AI Agent相比传统强化学习具有行动空间无限、无需定义奖励函数等优势,并从记忆机制(Memory+RAG)、工具使用(Function Calling)和规划能力(Tree Search+脑内模拟)三个维度系统阐述了AI Agent的核心技术与当前挑战。
什么是AI Agent?李宏毅教授的定义
在李宏毅教授2026年最新的AI Agent系列课程中,他首先明确了本课程对AI Agent的定义:人类不提供明确的行为或步骤指示,而是只给AI一个目标,AI自己想办法去达成目标。
这与我们日常使用AI的方式截然不同。平时我们给AI一个明确指令(如"翻译这段话"),AI按指令执行即可。但AI Agent需要面对的是复杂的、多步骤的任务——比如给定一个研究议题,AI Agent需要自己提出假设、设计实验、执行实验、分析结果,甚至在结果不符合预期时回头修正假设。
AI Agent的运作流程可以概括为:接收目标 → 观察环境(Observation)→ 决定行动(Action)→ 影响环境 → 获得新观察 → 循环往复,直到达成目标。AlphaGo就是一个经典的AI Agent案例:目标是赢棋,观察是棋盘状态,行动是选择落子位置。
从强化学习到LLM驱动AI Agent
过去打造AI Agent主要依赖强化学习(RL)算法,但这种方法有明显局限:你需要为每一个任务都训练一个专门的模型。AlphaGo能下围棋,但不能下象棋——能下象棋的是另一个独立训练的模型。
而今天AI Agent再次爆红,核心原因是人们有了新想法:能不能直接把大语言模型(LLM)当作AI Agent来使用?
用LLM驱动AI Agent有两大优势:
- 近乎无限的行动空间:AlphaGo只能在19×19的位置中选择,而LLM可以产生各式各样近乎无穷的输出,让Agent的行动不再有局限。
- 无需定义Reward:RL需要人工定义奖励函数(为什么编译错误是-1而不是-17.7?),而LLM可以直接读懂错误日志,获得比单一数值更丰富的反馈信息。
从LLM的角度看,当它作为AI Agent时,做的事情本质上没有任何不同——它就是在继续做文字接龙。AI Agent并不是LLM的新技术,而是LLM的一种应用方式。
AI Agent的实际应用案例
虚拟村庄与游戏NPC
2023年就有人用语言模型运行虚拟村庄中的NPC,每个NPC都有人为设定的目标(办派对、准备考试等),通过文字描述的环境信息来决定行为。后来甚至有人在Minecraft中将所有NPC换成AI驱动,据称这些AI组织了自己的金融体系和政府。
AI操作电脑
更具实际意义的应用是让AI像人类一样操作电脑,代表性产品包括Claude的Computer Use和ChatGPT的Operator。这类Agent的观察是电脑屏幕画面,行动是按键盘或点击鼠标。
AI训练AI
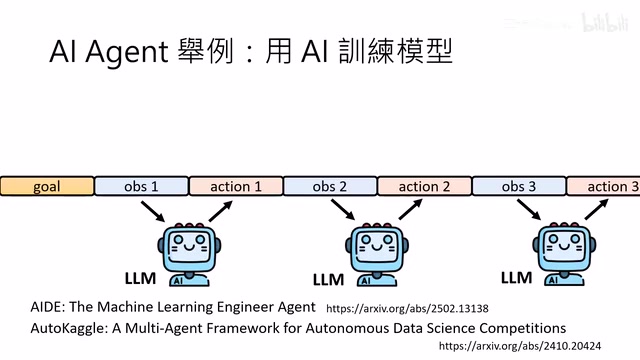
用AI来训练另一个AI模型也是重要应用方向。运作过程是:设定目标(如通过某个baseline)→ LLM编写训练程序 → 获得模型正确率 → 根据结果重新编写程序,如此循环。知名框架包括AIDE和Auto Cargo等。
核心能力一:根据经验调整行为(Memory机制)
为什么需要Memory?
AI Agent需要根据过去的经验调整行为,但不能让它每次决策都回顾"一生"的经历——这就像患有"超忆症"的人,被琐碎记忆淹没反而无法做抽象思考。
解决方案是引入Memory(长期记忆)机制:
- Read模组:从Memory中检索与当前问题相关的经验(本质就是RAG技术)
- Write模组:决定什么信息值得记录,什么可以"随风而去"
- Reflection模组:对记忆进行高层次的抽象整理,产生新的洞察
StreamBench的关键发现
在StreamBench基准测试中,一个重要发现是:负面反馈基本上没有帮助,正面例子比负面例子更有效。 与其告诉语言模型"不要做什么",不如告诉它"要做什么"——这与过去的研究一致:叫它"写短一点"比"不要写太长"更有效。
核心能力二:使用工具(Function Calling)
工具使用的通用方法
所谓工具,对语言模型来说就是函数(function)。使用工具的通用方法非常直接:在System Prompt中告诉模型有哪些工具、怎么使用,模型需要时就会输出调用指令。
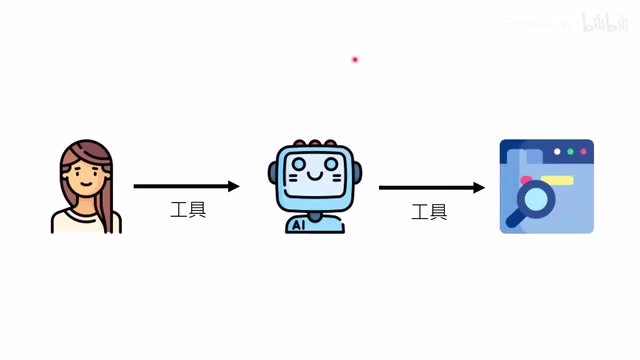
关键流程:模型输出工具调用文字 → 开发者截获并执行实际函数 → 将结果注入回模型的上下文 → 模型继续生成最终回答。
工具过多时怎么办?
当可用工具达到上百上千个时,不能让模型读完所有说明书再做事。解决方案类似Memory的RAG机制:将工具说明存入工具包,用检索模组根据当前状态选出合适的工具。
更进一步,语言模型甚至可以自己打造工具——写一个function,验证有效后存入工具包供后续使用。
AI会被工具"骗"吗?
研究发现,语言模型对工具输出有一定判断力(100度不质疑,10000度会质疑),但也存在被误导的风险。影响AI是否相信外部信息的因素包括:
- 外部知识与模型内部信念的偏差程度(偏差越大越不信)
- 模型对自身答案的信心程度(信心越高越不易动摇)
- 文章的发布时间(更相信新文章)
- 文章是否由AI撰写(更相信AI同类的话)
核心能力三:规划能力(Planning)
当前模型的规划水平如何?
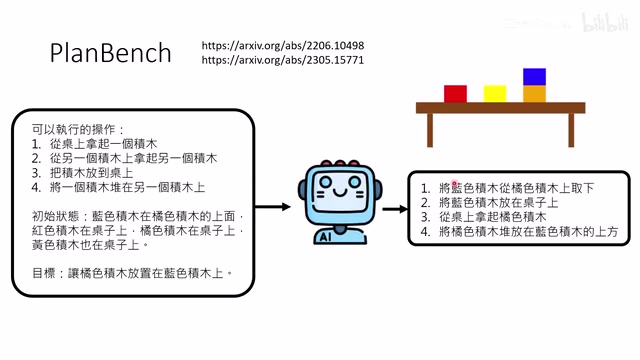
在PlanBench的"神秘方块世界"测试中(使用非常规规则避免模型照搬训练数据),2023年的模型几乎完全失败。但O1等推理模型的出现带来了显著改善。
在旅行规划任务中,2024年初的模型成功率接近0%,但在工具辅助下(如约束求解器),GPT-4和Claude 3可以达到90%以上的正确率。
Tree Search与脑内模拟
强化规划能力的方法之一是让模型进行Tree Search——尝试不同路径,评估成功概率,剪除无望分支。但现实中很多动作"覆水难收"(比如已经下单的披萨),因此更实际的做法是让一切搜索发生在**"脑内小剧场"**中——模型自己想象执行结果,在脑中找到最优路径后再真正执行。
有趣的是,具备推理能力的模型(如DeepSeek R1)在做AI Agent时,其思维链(Chain of Thought)本身就在进行类似的规划——自己尝试不同可能性,自己验证,自己扮演World Model。
Overthinking:想太多的危险
最新研究"The Danger of Overthinking"指出,能做脑内模拟的模型虽然整体表现更好,但存在想太多的问题:有些模型对一个按钮点下去会怎样反复思考却不行动,有些甚至还没尝试就自我放弃。如何避免模型"死于想太多",是未来重要的研究方向。
总结:AI Agent的技术全景
李宏毅教授这堂课从三个维度剖析了AI Agent的核心能力:
- 根据经验调整行为:Memory + RAG检索机制
- 使用工具:Function Calling + 智能工具选择
- 规划能力:Tree Search + 脑内模拟
当前的AI Agent并非依赖全新技术,而是充分利用LLM已有的文字接龙能力,通过巧妙的工程设计来实现复杂任务的自主完成。这门课程为理解和构建AI Agent提供了清晰而系统的框架,也揭示了当前技术的边界与未来的研究方向。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。