LifeSciBench:173位科学家打造的生命科学AI基准测试
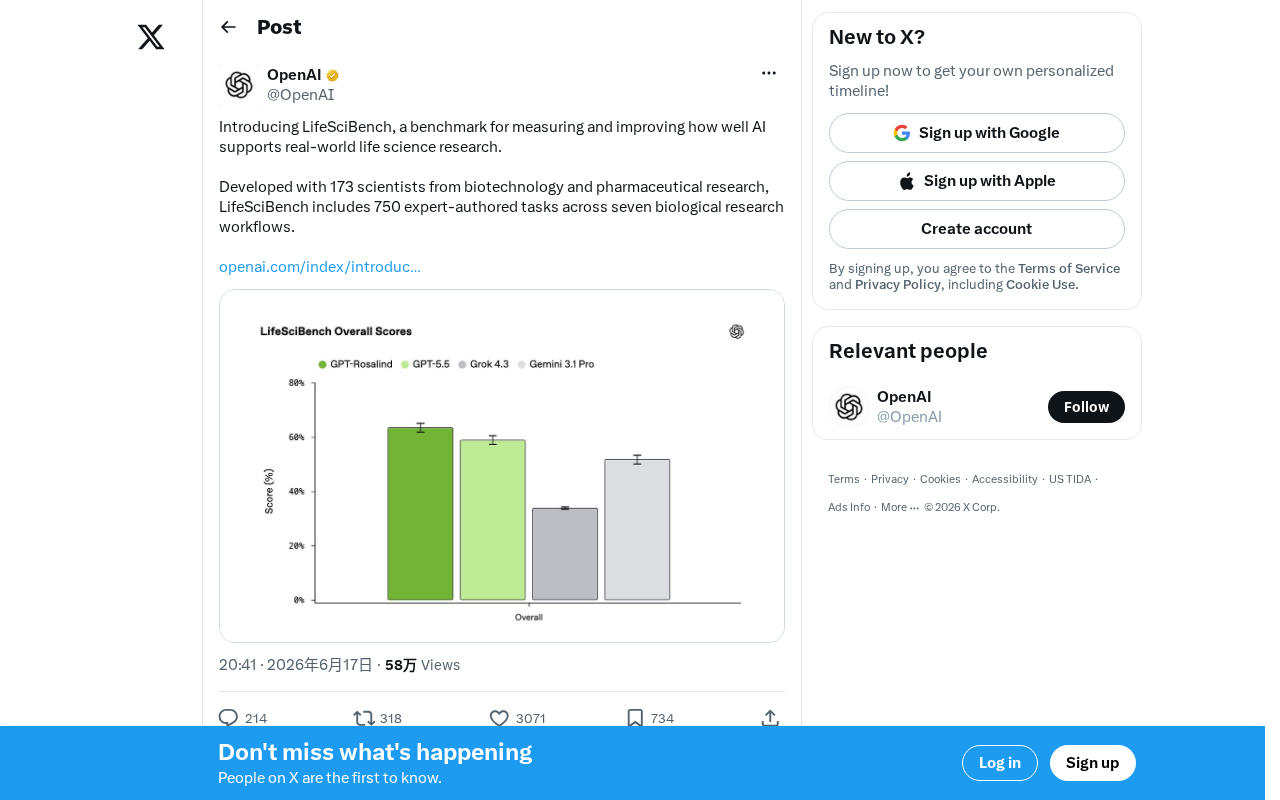
生命科学领域迎来专业AI评测标准
AI在生命科学领域的应用正在加速,但一个关键问题始终悬而未决:我们如何衡量AI在真实科研场景中的实际表现?通用的AI基准测试往往无法反映生命科学研究的复杂性和专业性。
近日,一项名为LifeSciBench的全新基准测试正式发布,旨在系统性地衡量和提升AI对真实生命科学研究的支持能力。这一基准测试由173位来自生物技术和制药研究领域的科学家共同开发,涵盖750项专家编写的任务,横跨七大生物学研究工作流程。
为什么需要专门的生命科学AI基准测试?
通用基准的局限性
当前主流的AI基准测试(如MMLU、HumanEval等)主要聚焦于通用知识问答或编程能力,对于生命科学这类高度专业化的领域,它们存在明显的评估盲区。MMLU(Massive Multitask Language Understanding)是由加州大学伯克利分校等机构于2021年提出的大规模多任务语言理解基准,涵盖57个学科的约15,000道选择题,主要测试模型的知识广度。HumanEval则由OpenAI发布,包含164个手写编程题,用于评估代码生成能力。这些基准虽然在各自领域具有标杆意义,但其评测维度高度标准化,无法模拟生命科学研究中常见的开放式问题求解、多步骤推理链条和跨模态数据整合等复杂认知过程。
生命科学研究涉及复杂的实验设计、数据解读、文献分析和假设验证,这些能力远非简单的选择题或文本生成所能覆盖。现代生命科学研究通常遵循一套高度系统化的工作流程:从文献调研形成科学假设,到实验设计与执行,再到多组学数据(基因组学、蛋白质组学、代谢组学等)的整合分析,最终完成结果验证与论文撰写。每个环节都涉及大量领域特异性知识,例如实验设计需要理解生物样本的特殊处理要求、统计学功效分析,以及伦理审查规范。这种端到端的复杂性使得通用AI工具在实际科研场景中常常力不从心。
来自一线科学家的真实需求
LifeSciBench的核心价值在于其来源的权威性——173位参与开发的科学家均来自生物技术和制药研究一线。这意味着基准测试中的每一项任务都植根于真实的科研场景,而非学术假设。这种"自下而上"的设计方法确保了评测结果与实际科研需求的高度契合。
LifeSciBench的核心设计与任务构成
750项专家编写任务
LifeSciBench包含750项由领域专家精心编写的评测任务,这一规模在生命科学AI评测领域相当可观。每项任务都经过严格的同行审核,确保其科学准确性和评测有效性。
覆盖七大生物学研究工作流程
基准测试覆盖了七个关键的生物学研究工作流程,虽然官方尚未详细披露所有工作流程的具体内容,但从生命科学研究的一般范畴推测,这些工作流程可能涵盖:
- 文献检索与综述:评估AI整合和分析科学文献的能力
- 实验设计:测试AI辅助制定实验方案的水平
- 数据分析与解读:衡量AI处理生物学数据的准确性
- 靶点发现与验证:评估AI在药物研发早期阶段的辅助能力
- 序列与结构分析:测试AI对生物分子信息的理解深度
其中,靶点发现是新药研发的起点,指识别与疾病发生发展密切相关的生物分子(通常是蛋白质)。传统靶点发现依赖大量湿实验验证,耗时长、成本高,一个新靶点从发现到验证通常需要3-5年。近年来,AI技术通过整合基因组关联分析(GWAS)、蛋白质互作网络、单细胞转录组数据等多源信息,显著加速了这一过程。DeepMind的AlphaFold在蛋白质结构预测上的突破,更是为基于结构的靶点验证提供了全新工具。LifeSciBench对这一环节的评测,将直接反映AI在药物研发最关键起始阶段的实际效能。
这种多维度的评测框架,使得LifeSciBench能够全面反映AI在生命科学研究中的综合表现,而非仅仅测试某一单一能力。
LifeSciBench对行业的深远影响
推动AI模型的定向优化
有了标准化的评测体系,AI开发者可以更有针对性地优化模型在生命科学领域的表现。过去,由于缺乏专业基准,模型开发往往只能依赖通用指标,导致在实际科研应用中表现不尽如人意。LifeSciBench的出现为模型迭代提供了明确的方向标。
加速AI在制药领域的落地
制药行业是AI应用最具商业价值的领域之一。据波士顿咨询集团和麦肯锡等机构估算,AI有望将药物研发周期缩短30%-50%,将研发成本降低数十亿美元。目前全球已有超过100家AI制药公司,包括Recursion Pharmaceuticals、Insilico Medicine、Exscientia等头部企业。其中Insilico Medicine的AI发现药物ISM001-055已进入II期临床试验,成为AI制药领域的里程碑事件。然而,行业也面临"AI洗牌"的质疑——许多公司的AI管线尚未产出获批药物,如何客观评估AI工具的真实效能成为行业痛点。
一个被行业广泛认可的基准测试,能够帮助制药企业更科学地评估和选择AI工具,降低技术选型的风险。同时,它也为AI公司提供了一个证明自身能力的舞台——在LifeSciBench上的优异表现将成为有力的市场背书。
建立科学家与AI开发者之间的桥梁
173位科学家的深度参与,本身就是一次成功的跨界协作实践。这种模式——让终端用户深度参与AI评测标准的制定——值得其他专业领域借鉴。它确保了技术发展始终以用户需求为导向,避免技术与实际应用脱节。
展望与思考
LifeSciBench的发布标志着AI在生命科学领域的应用正在从探索期迈向标准化期。当一个领域开始建立系统性的评测标准时,往往意味着该领域的AI应用即将进入快速成熟阶段。
不过,基准测试本身也面临挑战。生命科学研究日新月异,750项任务能否持续反映前沿需求?评测标准如何随着技术进步而动态更新?这些问题都需要在后续的迭代中逐步解决。值得注意的是,基准测试的"数据污染"问题是AI评测领域的长期挑战——当训练数据中包含基准测试题目时,模型得分会虚高,无法反映真实能力。此外,生命科学领域每年发表超过150万篇论文,CRISPR基因编辑、空间转录组学、AI蛋白质设计等前沿技术不断涌现,静态的评测集很快就会过时。业界的应对策略包括定期更新题库、引入动态生成机制、以及建立"活基准"(living benchmark)体系,让评测标准与科学前沿同步演进。
无论如何,LifeSciBench迈出了重要的一步——它让我们第一次有了一把可靠的尺子,来衡量AI究竟能在多大程度上真正助力生命科学研究。
核心要点
相关推荐

Claude Code插件Ponytail实测:代码量锐减,成本降低50%
实测Claude Code插件Ponytail的代码精简效果,通过YAGNI决策阶梯将AI生成代码量大幅缩减,成本降低47%-77%。包含天气仪表板对比测试、与Caveman插件组合测试及详细基准数据分析。
DeepSeek+Resonix:1.5亿Token仅花8元的低成本AI编程方案
实测DeepSeek API搭配Resonix编程工具,1.5亿Token仅花费8元人民币。深入解析DeepSeek定价策略、Resonix 95%缓存命中率的实现原理,以及与GPT模型编码能力的真实对比。

OpenAI o3诊断罕见儿童疾病:NEJM AI研究深度解读
OpenAI联合波士顿儿童医院在NEJM AI发表研究,展示o3 Deep Research模型如何帮助临床医生诊断此前未解决的罕见儿童疾病病例,为等待多年的家庭带来答案。