OpenAI o3诊断罕见儿童疾病:NEJM AI研究深度解读

研究背景:罕见病诊断的困境
罕见病诊断一直是医学领域最具挑战性的难题之一。对于患有罕见儿童疾病的家庭而言,漫长的诊断过程往往意味着数年甚至更久的等待——在医学上,这被称为"诊断奥德赛"(diagnostic odyssey)。根据全球罕见病组织(Global Genes)的统计,罕见病患者从出现症状到获得正确诊断,平均需要经历5-7年的漫长等待,期间可能辗转7-8位不同专科的医生,接受2-3次错误诊断。在美国,罕见病的定义是患病人数少于20万人的疾病,而在欧盟则是患病率低于万分之五。由于单一罕见病的患者极少,大多数临床医生在整个职业生涯中可能从未遇到过某种特定的罕见病,这使得经验积累几乎不可能。此外,约80%的罕见病具有遗传学基础,但基因变异的解读本身就是一项高度复杂的工作,许多变异的临床意义尚不明确(即所谓的"意义不明变异",VUS)。许多病例在经过多轮专家会诊后仍然无法得出明确结论,成为悬而未决的医学"冷案"。
近日,OpenAI联合波士顿儿童医院(Boston Children's Hospital)和哈佛大学的研究团队,在顶级医学AI期刊《NEJM AI》上发表了一项重磅研究。波士顿儿童医院是全球最顶尖的儿科医疗机构之一,连续多年被《美国新闻与世界报道》评为全美最佳儿童医院,其未诊断疾病项目(Undiagnosed Diseases Program)汇聚了遗传学、基因组学、代谢病学等多学科专家团队,专门处理其他医疗机构无法确诊的疑难病例。该院也是基因组医学的先驱机构之一,其Manton罕见病与个体化医学中心在全基因组测序和外显子组测序的临床应用方面积累了丰富经验。此次与OpenAI的合作,代表了顶级临床机构与前沿AI技术的深度融合。该研究展示了o3 Deep Research模型如何帮助临床医生重新审视此前未能解决的罕见儿童疾病病例,并为苦等多年的家庭找到了答案。


o3 Deep Research如何突破罕见病诊断瓶颈
o3 Deep Research的独特能力
这项研究的核心工具是OpenAI的o3 Deep Research模型。与普通大语言模型不同,Deep Research具备深度推理和大规模文献检索的能力,能够在海量医学文献中进行系统性搜索和交叉比对。
从技术架构来看,o3 Deep Research是OpenAI在2025年推出的一种具备"深度研究"能力的AI系统,它建立在o3推理模型的基础之上。与传统的大语言模型(如GPT-4)主要依赖预训练知识不同,Deep Research能够在推理过程中主动发起多轮网络搜索,实时检索和整合来自PubMed、OMIM(在线人类孟德尔遗传数据库)、ClinVar(临床变异数据库)等专业医学数据库的最新信息。其核心技术优势在于"链式思维"(Chain-of-Thought)推理与检索增强生成(RAG)的深度融合——模型不仅能搜索文献,还能在搜索结果之间建立逻辑关联,识别跨文献的模式匹配,这种能力在面对罕见病这类需要跨学科知识交叉验证的场景中尤为关键。
这种能力对于罕见病诊断尤为关键——罕见病的相关文献往往分散在不同期刊和数据库中,单靠人力几乎不可能全面覆盖。研究团队将此前未能确诊的罕见儿童疾病病例提交给o3 Deep Research进行分析,这些病例此前已经过多位专家的反复讨论,始终未能得出明确的诊断结论。
为等待多年的家庭带来确切答案
研究结果表明,o3 Deep Research能够帮助临床医生重新发现被忽略的线索,提出新的诊断假设,并在部分病例中成功找到了答案。这意味着那些已经等待数年的家庭,终于有机会获得明确的诊断——这不仅关乎治疗方案的制定,更关乎家庭对疾病的理解和未来的规划。
说个细节,研究明确强调AI是"帮助临床医生"(helped clinicians)而非"替代临床医生"。o3 Deep Research在整个过程中扮演的是强大的辅助工具角色,最终的诊断决策仍然由专业医生做出。
这项研究为何意义重大
NEJM AI发表带来的权威背书
《新英格兰医学杂志》(NEJM)是全球最具影响力的医学期刊之一,其AI子刊NEJM AI同样具有极高的学术权威性。NEJM创刊于1812年,是全球历史最悠久、影响因子最高的综合医学期刊之一(影响因子常年超过150)。NEJM AI是其于2024年正式推出的专注于人工智能与医学交叉领域的子刊,继承了母刊极为严格的同行评审标准,专门发表AI在临床医学中应用的高质量研究。在该刊发表论文意味着研究不仅在技术层面具有创新性,更在临床有效性和方法学严谨性方面经受住了顶级医学专家的审视。这与许多仅在计算机科学会议上发表的医疗AI研究形成了鲜明对比——后者往往缺乏真实临床场景的验证。这项研究能够在NEJM AI上发表,本身就说明了研究设计的严谨性和结论的可靠性,也是AI在罕见病诊断领域获得顶级医学期刊认可的重要标志。
从通用AI到专业临床场景的跨越
此前,大语言模型在医疗领域的应用多集中在常见病问答、医学知识科普等相对简单的场景。回顾AI在医疗诊断领域的演进历程,早期的专家系统(如1970年代的MYCIN)依赖手工编写的规则库,覆盖范围有限;2010年代深度学习兴起后,AI在医学影像识别(如皮肤癌检测、糖尿病视网膜病变筛查)方面取得突破,但这些应用本质上是模式识别任务;2023年以来,大语言模型开始在医学知识问答中展现能力——GPT-4在美国医师执照考试(USMLE)中的表现已超过人类平均水平。然而,从回答标准化考试题目到解决真实世界的复杂诊断问题之间存在巨大鸿沟。
罕见病诊断则是一个极其复杂的任务,需要模型同时具备深度推理、跨学科知识整合以及大规模文献检索的综合能力。模型不仅需要"知道"医学知识,还要能够在不完整、模糊甚至相互矛盾的临床信息中进行假设生成与验证,这正是o3 Deep Research试图跨越的技术门槛。
o3 Deep Research在这一场景中的成功应用,标志着AI从通用医疗助手向专业临床决策支持工具迈出了关键一步。
对全球罕见病研究生态的潜在影响
全球约有7000种已知的罕见病,影响着约3亿人口,其中大量病例面临诊断困难的问题。目前这7000种罕见病中,仅有不到5%拥有经FDA批准的治疗方案。罕见病研究面临的核心困境是"碎片化"——患者分散在全球各地,单个研究中心能够积累的病例数极为有限,这严重制约了对疾病自然史的理解和临床试验的开展。
近年来,多个国际合作项目试图打破这一困局,包括美国NIH的未诊断疾病网络(Undiagnosed Diseases Network, UDN)、欧盟的罕见病参考网络(European Reference Networks, ERNs)以及国际罕见病研究联盟(IRDiRC)。这些项目通过数据共享和跨国协作取得了显著进展,但仍有约50%的疑似遗传性疾病患者在接受全外显子组测序后无法获得明确的分子诊断。
如果o3 Deep Research的方法能够推广应用,将有望通过自动化文献挖掘和表型-基因型关联分析来填补这一缺口,系统性地加速罕见病的诊断流程,缩短患者的等待时间,甚至推动新的罕见病致病基因和发病机制的发现。
落地推广仍需关注的问题
尽管这项研究令人振奋,但在实际推广过程中仍有几个关键问题需要解决:
- 样本规模与可重复性:目前公开信息尚未详细披露研究涉及的病例数量和具体诊断成功率,后续需要更大规模的验证研究来确认结果的普适性。
- 患者数据隐私与合规:罕见病患者的数据极为敏感,如何在充分利用AI能力的同时保护患者隐私,是实际推广中必须解决的核心问题。罕见病患者数据的隐私保护面临独特挑战:由于患者群体极小,即使经过去标识化处理,罕见病患者的临床特征组合本身就可能具有高度可识别性。在法规层面,美国的HIPAA(健康保险可携性与责任法案)和欧盟的GDPR(通用数据保护条例)对健康数据的处理设定了严格要求。在技术层面,联邦学习(Federated Learning)、差分隐私(Differential Privacy)和同态加密等隐私保护计算技术正在被探索用于医疗AI场景,使模型能够在不直接接触原始患者数据的情况下进行学习和推理。此外,当AI系统需要实时检索外部数据库时,如何确保查询过程本身不会泄露患者信息,也是一个需要仔细设计的技术问题。
- 临床落地路径:从研究论文到临床常规使用,还需要经过监管审批、临床流程整合、医生培训等多个环节。
总结
这项由OpenAI、波士顿儿童医院和哈佛大学联合完成的研究,展示了AI深度推理能力在罕见儿童疾病诊断这一医学最困难领域中的巨大潜力。o3 Deep Research不仅是一项技术突破,更为那些在漫长诊断等待中煎熬的家庭带来了切实的希望。
随着AI技术的持续进步和临床验证的不断深入,我们有理由期待,更多悬而未决的罕见病"冷案"将被逐一破解,更多家庭将从中受益。
相关推荐

Claude Code插件Ponytail实测:代码量锐减,成本降低50%
实测Claude Code插件Ponytail的代码精简效果,通过YAGNI决策阶梯将AI生成代码量大幅缩减,成本降低47%-77%。包含天气仪表板对比测试、与Caveman插件组合测试及详细基准数据分析。
DeepSeek+Resonix:1.5亿Token仅花8元的低成本AI编程方案
实测DeepSeek API搭配Resonix编程工具,1.5亿Token仅花费8元人民币。深入解析DeepSeek定价策略、Resonix 95%缓存命中率的实现原理,以及与GPT模型编码能力的真实对比。
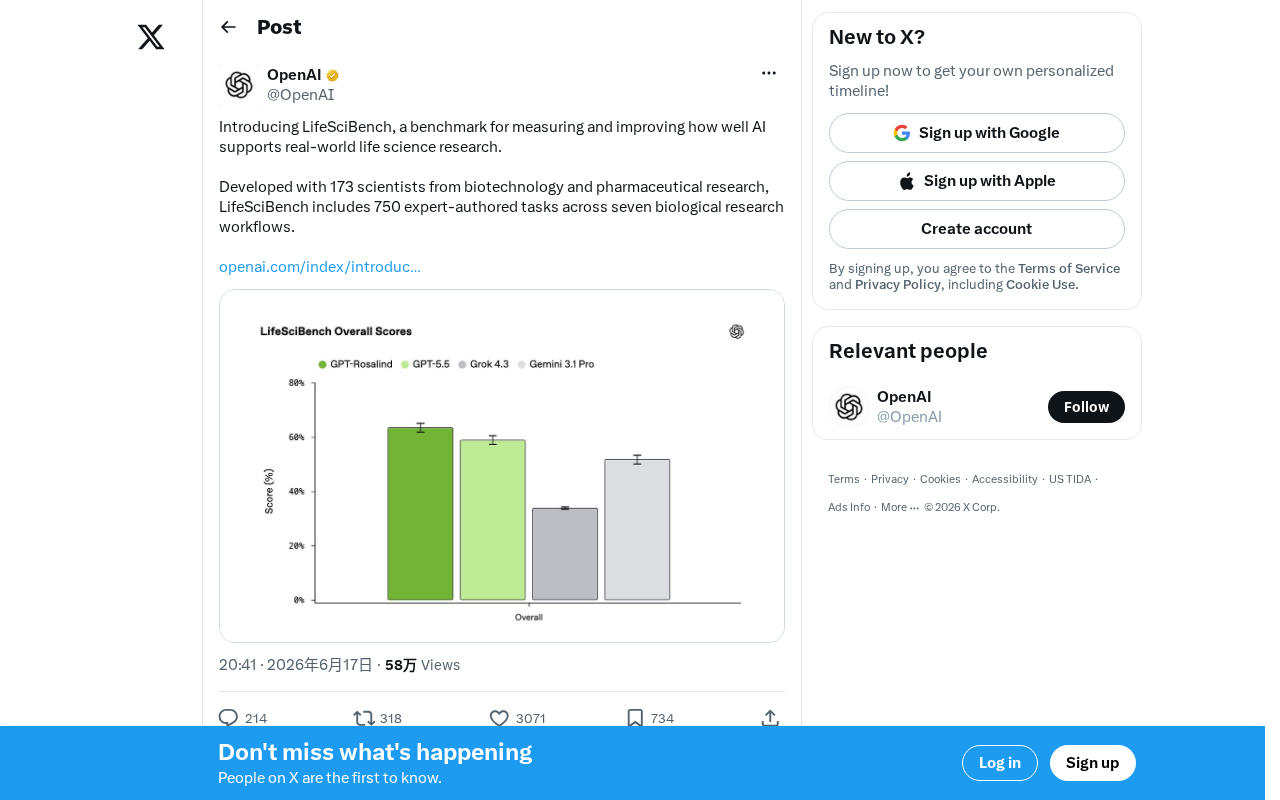
LifeSciBench:173位科学家打造的生命科学AI基准测试
LifeSciBench是由173位生物技术与制药领域科学家共同开发的生命科学AI基准测试,涵盖750项专家任务和七大研究工作流程,为AI在生命科学领域的评估提供专业标准。