Llama.cpp Windows本地部署教程:免编译三步运行大模型
前言
想在本地跑大模型,Llama.cpp 是绕不开的轻量级推理框架。它由开发者 Georgi Gerganov 于 2023 年 3 月发起,最初的目标是让 Meta 的 LLaMA 模型能够在纯 CPU 环境下运行。项目底层基于作者自研的 ggml 张量计算库,完全用 C/C++ 编写,不依赖 PyTorch、TensorFlow 等重型深度学习框架,因此编译产物极其精简,单个可执行文件就能完成模型加载和推理。正是这种"零依赖"的设计哲学,让 Llama.cpp 迅速成为本地大模型推理领域最受欢迎的开源项目之一,GitHub Star 数已超过 80k,支持的模型架构也从最初的 LLaMA 扩展到了 Qwen、Mistral、Phi、Gemma 等数十种主流开源模型。
不过很多人一听到"编译"两个字就打了退堂鼓——配环境、装依赖、处理报错,随便哪一步都能劝退非开发者用户。
好消息是,Llama.cpp 官方已经提供了预编译的 Windows 安装包,整个部署过程无需任何编译操作,下载、解压、运行三步搞定。本文将详细梳理这套免编译的 Llama.cpp Windows 本地部署流程,帮你用最短时间把大模型跑起来。
准备工作:下载所需文件
下载 Llama.cpp 主程序和 CUDA 依赖包
打开 Llama.cpp 的 GitHub 官方仓库,进入 Releases 页面。页面下方的 Assets 列表中,官方为不同平台和显卡类型编译好了安装包,直接下载即可。
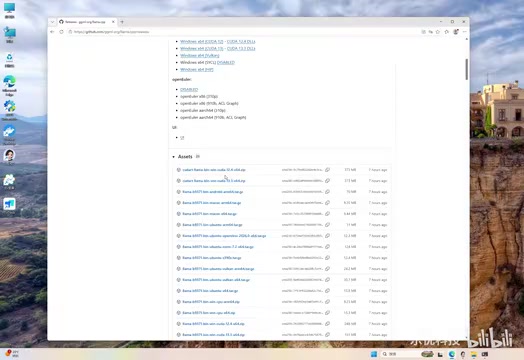
如果你使用的是 NVIDIA 显卡并希望通过 CUDA 加速推理,需要下载以下两个压缩包:
- CUDA 依赖包(cudart-llama-bin-win-cuXX):包含 CUDA 运行时所需的 DLL 文件
- 主程序包(llama-bXXXX-bin-win-cuda-cuXX):Llama.cpp 的核心可执行文件
关于 CUDA 的背景知识: CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的并行计算平台和编程模型,它允许开发者利用 GPU 上成千上万个计算核心来执行通用计算任务。大模型推理的核心操作是大量的矩阵乘法,而 GPU 天生擅长这类高度并行的数学运算——一块中端显卡的矩阵计算吞吐量可以轻松达到 CPU 的数十倍甚至上百倍。这里下载的 cudart(CUDA Runtime)包包含了 cublas64_XX.dll、cudart64_XX.dll 等动态链接库,它们是 Llama.cpp 调用 GPU 进行矩阵运算的桥梁。没有这些 DLL 文件,即使你的显卡支持 CUDA,程序也无法将计算任务分配给 GPU。
注意:两个包的 CUDA 版本号必须一致。 比如都选 cu12.4,混用不同版本会导致兼容性问题。如果你不确定自己的显卡支持哪个 CUDA 版本,可以在命令行中运行 nvidia-smi,右上角会显示驱动支持的最高 CUDA 版本——下载时选择不超过该版本的包即可。
下载 GGUF 量化模型
接下来需要准备模型文件。这里以 Qwen 3 32B 的 Q5_K_M 量化版为例,从 Hugging Face 下载 GGUF 格式的模型文件。
什么是 GGUF 格式? GGUF(GPT-Generated Unified Format)是 Llama.cpp 生态专用的模型文件格式,由早期的 GGML 格式演进而来。2023 年 8 月,社区将格式从 GGML 升级为 GGUF,主要改进包括:支持在文件头中嵌入模型元数据(如分词器配置、模型架构参数等),实现了"单文件即完整模型"的设计目标;采用更灵活的键值对存储结构,便于向前兼容。简单来说,一个 .gguf 文件就包含了运行模型所需的全部信息,不再需要额外的 tokenizer 配置文件或参数映射表。
量化技术简介: 原始的大模型权重通常以 FP16(16 位浮点数)或 FP32(32 位浮点数)存储,一个 32B 参数的模型在 FP16 下就需要约 64GB 存储空间,远超消费级显卡的显存容量。量化(Quantization)技术通过将权重从高精度浮点数压缩为低比特整数表示(如 4-bit、5-bit、8-bit),大幅缩减模型体积和显存占用,同时尽量保持推理质量。Llama.cpp 采用的 K-quant(K 量化)方案是一种混合精度量化策略——它不是对所有层一视同仁地压缩,而是根据每一层对模型输出质量的影响程度分配不同的量化位数,重要的层保留更高精度,不太敏感的层则压缩得更激进,从而在相同平均比特数下获得更好的推理质量。
不同量化版本的区别:
- Q5_K_M:每个权重平均约 5.3 比特,精度和体积之间平衡较好,推荐大多数用户选择
- Q4_K_M:每个权重平均约 4.8 比特,体积更小、显存占用更低,精度略有损失
- Q8_0:每个权重 8 比特,接近原始精度,但文件体积大、显存要求高
以 32B 参数模型为例,Q5_K_M 量化后大约需要 20-24GB 存储空间,运行时对显存也有相应要求。如果显存有限,可以优先考虑 Q4_K_M 或选择更小参数量的模型。
环境配置:解压与目录组织
在 C 盘根目录下新建一个文件夹,命名为 llamacpp。路径中不要包含中文和空格,避免后续运行时出现路径解析错误。
将以下三部分文件全部解压到这个目录下:
- CUDA 依赖包的内容
- 主程序包的内容
- 下载好的 GGUF 模型文件
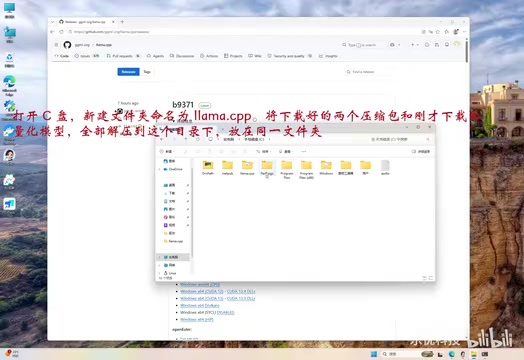
务必确保所有文件(可执行程序、DLL 文件、模型文件)都在同一个文件夹层级中,不要有多余的嵌套子目录。这是新手最容易踩的坑——解压后多了一层文件夹,导致程序运行时找不到依赖库而报错。之所以有这个要求,是因为 Windows 在加载可执行文件时,会优先在程序所在目录中搜索所需的 DLL 动态链接库。如果 llama-cli.exe 和 CUDA 的 DLL 文件不在同一目录下,系统就会报出类似"找不到 cublas64_12.dll"的错误。
运行模型:命令行操作
进入工作目录
打开 Windows PowerShell,输入以下命令切换到 Llama.cpp 所在目录:
cd C:\\\\llamacpp
验证文件是否就绪
用 dir 命令检查目录内容,确认模型文件已正确放置:
dir *.gguf
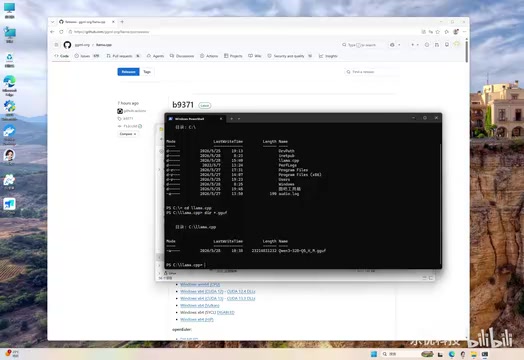
如果能看到模型文件名输出,说明准备工作已经完成。
启动 llama-cli 进行对话
使用 llama-cli 命令加载模型并进入交互式对话:
.\\\\llama-cli.exe -m qwen3-32b-q5_k_m.gguf -ngl 99 --conversation
各参数含义:
-m:指定 GGUF 模型文件的路径-ngl 99:将尽可能多的模型层卸载到 GPU 运行,数字越大 GPU 利用率越高--conversation:启用交互式对话模式
关于 -ngl 参数的工作原理: 大语言模型的核心结构是由多个 Transformer 层堆叠而成的。例如 Qwen3-32B 模型包含 64 个 Transformer 解码层。-ngl(number of GPU layers)参数控制将多少层放到 GPU 显存中运行,剩余的层则留在内存中由 CPU 处理。设置为 99 意味着"尽量把所有层都放进 GPU"——如果显存足够,全部 64 层都会在 GPU 上运行,推理速度最快;如果显存不够,Llama.cpp 会自动将放不下的层回退到 CPU,形成 GPU/CPU 混合推理模式。你也可以手动设置一个具体数值,比如 -ngl 40 表示只将前 40 层放入 GPU,这在显存紧张时可以避免 OOM(Out of Memory)崩溃。一般来说,GPU 上的层越多,推理速度越快,但显存占用也越高,需要根据自己的硬件情况找到平衡点。
如果显存不够加载全部层,可以把 -ngl 的数值调低,让一部分计算回退到 CPU 上完成。速度会变慢,但模型仍然可以正常运行。
常见问题与建议
显存不足怎么办?
- 换用更激进的量化版本,比如 Q4_K_M 或 Q3_K_M
- 降低
-ngl参数值,采用 CPU + GPU 混合推理 - 选择参数量更小的模型,比如 7B 或 14B 版本
作为参考,以下是不同显存容量的大致适配建议:8GB 显存适合运行 7B 模型的 Q4/Q5 量化版(全部层上 GPU);12GB 显存可以运行 14B 模型的 Q4 量化版或 7B 的 Q8 版本;24GB 显存(如 RTX 4090)可以运行 32B 模型的 Q4_K_M 全量上 GPU,或 Q5_K_M 的大部分层上 GPU。如果你的显存只有 6GB 甚至更低,建议选择 3B 或 1.5B 的小模型先体验流程。
想要 Web 界面怎么操作?
用 llama-server 替代 llama-cli,它会在本地启动一个 Web 服务,提供类似 ChatGPT 的网页交互界面:
.\\\\llama-server.exe -m qwen3-32b-q5_k_m.gguf -ngl 99
启动成功后,在浏览器中访问 http://localhost:8080 就能直接使用。
llama-server 的更多能力: 除了提供开箱即用的 Web 聊天界面,llama-server 还会同时暴露一套兼容 OpenAI API 格式的 REST 接口(默认监听在 http://localhost:8080/v1/chat/completions 等端点)。这意味着你可以将它作为本地 API 服务器,直接对接任何支持 OpenAI API 的第三方客户端和开发框架——比如用 Open WebUI 获得更丰富的聊天界面,用 Chatbox 作为桌面客户端,或者在 Python 代码中通过 openai 库直接调用本地模型,只需将 base_url 指向 http://localhost:8080/v1 即可。这种兼容设计极大地扩展了 Llama.cpp 的使用场景,让它不仅仅是一个命令行工具,更是一个完整的本地推理服务后端。
性能优化建议
- 把 NVIDIA 显卡驱动更新到最新版本
- 运行前关闭其他占用显存的程序(游戏、视频编辑软件等)
- 如果有多张显卡,可以通过
--split-mode参数配置多卡并行推理
多卡推理详解: 如果你的机器安装了多张 NVIDIA 显卡,Llama.cpp 支持两种多卡分割模式。--split-mode layer(默认模式)按层分割,将不同的 Transformer 层分配到不同的 GPU 上,类似于流水线并行;--split-mode row 按行分割,将同一层的矩阵运算拆分到多张卡上并行计算,类似于张量并行。对于大多数用户,默认的 layer 模式已经足够好用。你还可以通过 --tensor-split 参数精确控制每张卡分配的比例,例如 --tensor-split 3,7 表示第一张卡承担 30% 的负载,第二张卡承担 70%,这在两张不同型号的显卡混用时特别有用。
总结
整个 Llama.cpp 的 Windows 本地部署流程可以归纳为四步:
- 从 GitHub Releases 下载主程序包和 CUDA 依赖包(版本号保持一致)
- 从 Hugging Face 下载 GGUF 格式的量化模型
- 将所有文件解压到同一个目录
- 在 PowerShell 中执行命令加载模型
不用装 Python,不用配编译环境,也不用折腾 Docker,真正做到了零门槛部署。如果你想在本地体验大模型又不想被复杂的环境配置劝退,Llama.cpp 的预编译方案是目前最省心的选择之一。
值得一提的是,Llama.cpp 社区的更新节奏非常快,几乎每周都有新版本发布,持续优化推理性能、支持新的模型架构、修复各类 Bug。建议定期关注 GitHub Releases 页面,及时更新到最新版本以获得最佳体验。
相关推荐
OpenAI Codex免费速率重置包领取教程
OpenAI向Plus、Pro、Business付费用户发放免费Codex速率限制重置包,每人1次免费重置,邀请好友最多再获3次。本文详解领取方式、使用时机及注意事项,30天有效期别错过。

用AI+Cursor开发微信小程序:从构思到前端的全流程实战
实测用DeepSeek、Claude、GPT三大AI模型做产品构思,再用Cursor编写微信小程序代码。零基础四轮迭代完成前端开发,详解AI辅助创业的完整流程与实战经验。
校友寻小程序技术解析:DeepSeek驱动的AI失物招领系统
深入解析校友寻失物招领小程序的技术架构与AI能力,涵盖DeepSeek智能匹配、OCR图片识别、扫码归还闭环、AI看板娘交互等核心功能,探索AI赋能校园失物招领的全栈实践方案。