#本地大模型推理
共 9 篇相关文章
 产品体验
产品体验·9 分钟
Google Gemma 4实测:手机离线运行+Ollama部署教程
实测Google Gemma 4开源模型在三台手机上的离线运行表现,详解Dense与MOE架构区别,附Ollama + Claude Code完整部署教程。从1B到31B四款模型覆盖手机到工作站全场景,4GB显存即可运行。
阅读全文 →
 产品体验
产品体验·8 分钟
WhichLLM:一键检测你的电脑最适合跑哪个本地大模型
WhichLLM 是一款开源工具,能自动检测电脑硬件配置,结合权威评测数据推荐最适合本地运行的大语言模型。支持模拟任意显卡配置、过滤虚假评测、一键下载开聊,帮你告别选模型的纠结。
阅读全文 →
 教程攻略
教程攻略·10 分钟
llama.cpp MTP加速部署指南:配置步骤与性能实测
详解llama.cpp如何启用MTP多Token预测加速技术,涵盖CUDA环境配置、桌面端设置、模型选择及实测性能数据,Qwen3 27B实测近60 Token/s。
阅读全文 →
 教程攻略
教程攻略·9 分钟
oMLX+MTP+Qwen3.6:本地AI编程速度突破新极限
使用oMLX推理引擎结合MTP多令牌预测技术和Qwen3.6 35B模型,在Apple Silicon Mac上实现86.7 tokens/s的本地编程速度,5分钟内完成全栈应用开发的完整实战解析。
阅读全文 →
 教程攻略
教程攻略·6 分钟
本地部署大模型怎么判断显存爆了?一文看懂显存监控方法
本地部署大模型时如何判断显存是否爆满?本文详解专用显存与共享GPU内存的区别,教你通过任务管理器快速判断显存溢出,并提供模型量化、上下文长度控制等避免爆显存的实用建议。
阅读全文 →
 科技前沿
科技前沿·4 分钟
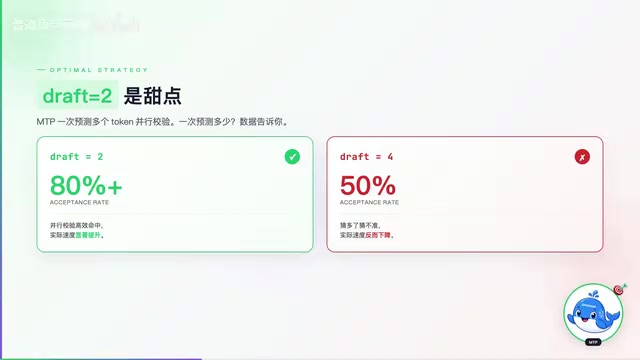
Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6实验性MTP-GGUF版本实测,单GPU将35B-A3B模型推理速度提升至220 token/s,比原版快1.4倍且精度零损失。详解MTP原理、最优Draft Tokens策略及RTX 5090实测数据。
阅读全文 →
 教程攻略
教程攻略·10 分钟
Codex+Ollama本地部署教程:零成本搭建AI编程助手
手把手教你用Codex搭配Ollama在本地部署免费AI编程助手,涵盖硬件检测、Ollama安装、Gemma/Qwen模型下载与接入配置全流程,轻松实现隐私安全的本地AI编程工作流。
阅读全文 →
 教程攻略
教程攻略·15 分钟
Ollama完全指南:一行命令本地运行DeepSeek等大模型
Ollama是GitHub 17万Star的开源工具,支持一行命令本地运行DeepSeek、Qwen、Kimi-K2.5等主流大模型。本文详解Ollama的模型生态、核心优势、应用场景及为何它成为本地LLM部署的事实标准。
阅读全文 →
 产品体验
产品体验·14 分钟
LibreChat:一个界面接入所有AI模型的开源聊天平台
深度解析LibreChat开源项目,支持GPT-5、Claude、Gemini、DeepSeek等多模型统一接入,内置Agents、MCP协议、代码解释器等功能,Docker一键部署,适合个人和企业自托管的ChatGPT替代方案。
阅读全文 →