Qwen3.6 MTP加速实测:单GPU推理飙到220 token/s
Qwen3.6的MTP-GGUF版本实现单GPU 220 token/s推理,速度提升超1.4倍且精度无损。
Daniel Han发布了Qwen3.6的实验性MTP-GGUF版本,通过将多token预测(MTP)能力内置于模型训练阶段,在单GPU上将35B-A3B模型推理速度提升至220 token/s,比原版快超1.4倍且精度零损失。测试发现Draft Tokens设为2是最佳策略,接受率可达80%以上。该方案无需额外草稿模型,一条命令即可启用,标志着本地大模型推理进入高性能新阶段。
Daniel Han(Onslaught AI创始人,前NVIDIA ML工程师)刚刚放出了Qwen3.6的实验性MTP-GGUF版本,在单GPU上将35B-A3B模型的推理速度推到了220 token/s,比原版GGUF快超过1.4倍,且精度零损失。这意味着本地大模型推理正式进入一个新阶段——不再是"能跑就行"的妥协方案,而是真正可用的高性能方案。
MTP是什么?从投机解码到内置多token预测
要理解这次加速的本质,需要先搞清楚MTP(Multi-Token Prediction)到底做了什么。
传统的大模型推理是串行的:每一步只预测一个token,生成完一个才能生成下一个。这种方式的瓶颈不在计算力,而在内存带宽——GPU大部分时间都在等数据搬运,算力严重空转。
这一现象有其深层的硬件原因。以RTX 4090为例,其理论FP16算力高达82.6 TFLOPS,但显存带宽仅有1008 GB/s。在自回归解码阶段,每生成一个token都需要将数十亿参数从显存搬运到计算单元,而实际计算量极小——这种"搬运多、计算少"的特性导致GPU算力利用率往往不足10%。这一现象被称为"内存密集型"(Memory-Bound)操作,与矩阵乘法等"计算密集型"(Compute-Bound)操作形成鲜明对比。MTP的核心价值正在于此:通过一次数据搬运预测多个token,将原本串行的多次IO操作压缩为一次,从根本上提升了内存带宽的利用效率。
传统的投机解码(Speculative Decoding)用一个小的"草稿模型"来加速:小模型先快速猜几个token,大模型再并行校验,猜对的直接采纳,猜错的回退重来。这一思路最早由Google DeepMind在2023年系统化提出,核心依据是"大模型校验比生成更快"——由于Transformer的并行注意力机制,验证N个token的计算成本与验证1个token相近。然而传统投机解码在工程实践中面临诸多挑战:草稿模型与目标模型需要词表完全对齐、两个模型同时驻留显存导致内存压力倍增、草稿模型的分布偏差会影响最终输出质量。
MTP的思路更优雅:在训练阶段就把多token预测能力内置到模型里。Meta在LLaMA 3的技术报告中首次将MTP作为训练目标引入,证明了在训练阶段直接优化多token预测可以同时提升模型能力和推理效率。Qwen3.6沿用并强化了这一设计,在训练时就加入了MTP头,模型本身就具备一次预测多个未来token的能力。Unsloth团队把这些MTP权重也量化打包进了GGUF格式,llama.cpp那边做了kernel适配,整条链路打通了。

不需要额外的小模型,不需要复杂配置,一条命令就能启用加速。这是架构层面的简洁性优势。
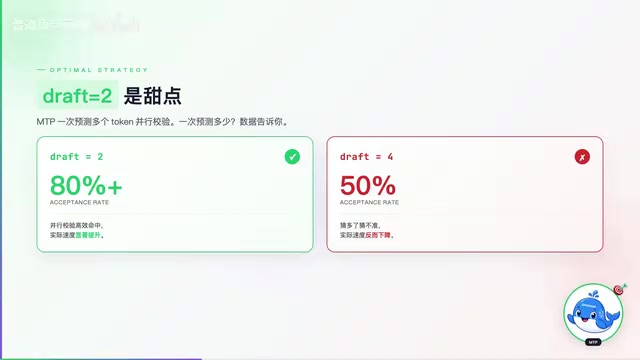
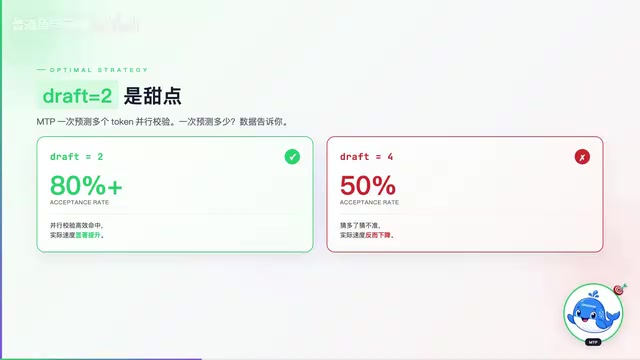
最优策略:Draft Tokens设为2是性能甜点
Daniel Han团队在测试中发现了一个非常重要的最优策略:Draft Tokens数量设为2是最佳选择。
这背后有精确的数学逻辑支撑。接受率(Acceptance Rate)是投机解码中衡量加速效果的核心指标。设草稿长度为k,每个token的接受率为α,则平均每次解码步骤生成的token数期望值约为(1-α^(k+1))/(1-α)。当α=0.8、k=2时,期望生成token数约为2.44,理论加速比接近2.44倍;而当α=0.5、k=4时,期望生成token数约为1.97,加速比反而更低。这一规律揭示了最优草稿长度需要根据具体模型的预测置信度动态校准——超出收益递减的临界点后,更长的草稿窗口只会带来更多无效计算。
当射程设为2时,接受率能达到80%以上——也就是说模型猜的两个token里,大概率都是对的,直接省掉了一半的解码步骤。但如果你贪心地把射程拉到4,接受率会暴跌到50%左右。猜得越远,不确定性越大,错误率飙升,反而需要更多的回退和重算。Daniel的原话是:"再多就是反作用了。"
这个发现对实际部署非常有指导意义:不要盲目追求更大的投机窗口,找到接受率和并行度的平衡点才是关键。
RTX 5090实测数据:27B与35B模型对比
在RTX 5090上的实测数据相当亮眼:

27B模型(Q4量化):
- 不开MTP:解码速度约63 token/s
- 开启MTP:解码速度跳到105 token/s
- 预填充速度:从174提升到253 token/s
- 草稿接受率:稳定在80%左右
- 显存占用:约18GB
35B-A3B(MoE版本):
- 推理速度:220 token/s
- 显存占用:约23GB
值得注意的是,35B-A3B中的"MoE"指混合专家架构(Mixture of Experts),"35B"是总参数量,"A3B"表示每次推理实际激活的参数量仅约3B。MoE的核心机制是路由器(Router):对于每个输入token,路由器从数十个"专家
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。