MEME基准测试揭示LLM记忆系统致命缺陷:依赖推理准确率不足50%

MEME基准揭示AI Agent记忆系统在依赖推理上全面失败,最佳准确率不到一半
KAST图宾根大学等机构提出MEME基准,首次系统评估AI记忆系统的依赖推理能力,涵盖级联、缺失、删除等六大任务。实验显示六大主流记忆系统全面失守,最佳准确率仅0.42,级联和缺失任务更低至0.3和0.1。失败根因在检索阶段而非存储,传统调优手段几乎无效,唯一有效方案成本高达70倍,指明未来需在架构层面实现依赖传播机制。
为什么记忆能力成为AI Agent的核心瓶颈
随着大语言模型越来越多地作为智能代理与用户进行多轮、跨会话交互,能否准确存储、更新和推理过往交互信息,已经成为衡量Agent能力的关键指标。
当前AI Agent的记忆系统大致分为三种技术范式:基于向量检索的RAG(检索增强生成)方式,将历史对话编码为向量后通过相似度匹配召回;基于LLM摘要提取的结构化记忆方式,由大模型主动从对话中抽取关键事实存入知识库;以及基于文件系统的代理式记忆,让LLM像操作文档一样读写记忆文件。这三种范式各有优劣,但它们共同面临的挑战是:如何在信息不断更新的动态环境中保持记忆的一致性和准确性。
举个直观的例子:用户告诉AI助理自己刚搬到了新城市,助理不仅要记录新地址,还要意识到之前与旧住址相关的信息——比如通勤时间、家附近的超市推荐——都已经失效了,不能再拿旧信息来回答问题。这种看似简单的场景,实际上对记忆系统提出了极高的要求。
来自KAST图宾根大学和Never AI Lab的最新研究提出了**MEME(Multi-Entity Evolving Memory Evaluation)**基准,首次系统性地评估了当前主流记忆系统在依赖推理上的表现——结果相当出人意料:表现最好的系统准确率也不到一半。
现有LLM记忆评估体系的三大盲区
记忆评估的演进历程
记忆评估已经经历了好几代迭代:最早是单轮长上下文基准,测试模型能否一次记住长文本里的信息;后来发展到多会话静态事实留存测试;再后来出现了带动态更新的基准,测试实体值跨会话变化时能否及时更新。
但这些评估都有一个共同的盲区:只测独立实体的更新,完全没有考虑实体之间的依赖关系推理。
三个从未被测试的关键能力
论文指出了现有基准完全缺失的三类任务:
- 级联效应(Cascade):修改上游实体信息后,下游依赖它的事实会不会跟着自动更新?级联效应的概念源自知识编辑(Knowledge Editing)领域的研究。知识编辑旨在修改大模型内部存储的特定事实而不影响其他知识,但研究者很早就发现,修改一个事实往往会引发连锁反应——例如将"法国首都"从巴黎改为马赛后,模型是否能自动推断出"埃菲尔铁塔所在城市"也应更新。这种级联一致性问题在参数级知识编辑中已被广泛讨论,但在外部记忆系统中却几乎未被系统评估,MEME首次将这一问题从模型内部延伸到了外部记忆架构层面。
- 缺失推理(Missing):上游改了但没有对应更新规则时,系统能否正确输出"不确定"?
- 删除验证(Deletion):用户明确要求删除某个事实后,系统是否真的不再提及?

对比ROAR、Nolima、LoCoMo、LongMemEval等知名基准,它们最多覆盖了精确召回、聚合、跟踪三个任务,删除、级联、缺失三个任务全都是空白。MEME是第一个完整覆盖这六个任务的评估基准。
MEME的二维评估框架设计
实体范围与时间动态:两个正交维度
论文提出了一个清晰的二维评估框架:
- 实体范围维度:分为单实体和多实体,类似问答领域的单跳与多跳推理。单跳推理只需定位一个信息源即可回答,而多跳推理需要从多个信息源中提取并组合信息,难度呈指数级增长。
- 时间动态维度:分为静态和演化,对应知识编辑中的级联效应问题。静态场景中信息一旦写入就不再变化,而演化场景中同一实体的值会随时间反复更新,系统必须始终追踪最新状态。
这两个维度此前一直是分开研究的,但在实际交互场景中它们同时存在。更新一个实体的信息,变化可能会沿着依赖链影响多个下游实体,必须联合评估才有实际意义。
六大评估任务详解
基于二维框架,MEME定义了六个代表性任务:
检索类(静态维度):
- 精确召回:完全逐字复现单个静态实体信息,如准确说出用户生日
- 聚合:整合分散在不同会话中的多个静态实体信息
状态管理类(单实体动态):
- 跟踪:按时间顺序重建单个实体的完整修改历史
- 删除:用户要求移除事实后,系统不再报告该信息
依赖推理类(多实体动态):
- 级联:根据依赖规则和上游更新,推断下游实体的新值
- 缺失:上游变了但无对应规则时,正确输出"不确定"

数据集构建:基于DAG知识图谱的可验证设计
知识图谱驱动的数据生成
MEME的数据集基于有向无环图(DAG)知识图谱生成,覆盖两个领域。有向无环图是一种没有环路的有向图结构,在计算机科学中广泛用于表示依赖关系,例如编译系统中的模块依赖、任务调度中的前后置关系等。在MEME基准中,DAG被用来建模实体之间的依赖链:节点代表实体(如用户的住址、通勤方式),有向边代表依赖关系(通勤时间依赖于住址和工作地点)。这种结构天然支持拓扑排序,使得当上游节点发生变更时,可以沿着有向边精确计算哪些下游节点需要同步更新,从而为级联和缺失任务提供可验证的黄金答案。
具体覆盖的两个领域为:
- 个人生活场景:39个实体,34条依赖边
- 软件项目场景:51个实体,27条依赖边
共生成100个评估片段,每个片段约3.5万Token对话上下文,总计产生694个变更后的评估问题。所有实体值都使用虚构名字,避免大模型参数知识干扰评估结果。
五步构建流程
每个评估片段的构建严格遵循五步流程:选实体集→赋初值并做一致性校验→根据拓扑角色分配任务→混合方式生成自然对话→插入干扰内容。其中对话生成采用GPT-4O自聊方式,依赖规则用模板直接插入以确保准确性,再经两层LLM验证(GPT-4O标注+Gemini 2.5 Flash语义审核)。
这套设计确保了所有任务的黄金答案都可验证,尤其是级联和缺失任务——答案不直接出现在对话中,而是通过DAG规则传播计算得出。
实验结果:6大主流记忆系统全面失守
六大系统无一幸免
论文评估了6个主流记忆系统,覆盖三大技术范式:
- 原始检索类:BM25、Text Embedding 3 Small。BM25是一种经典的基于词频统计的信息检索算法,属于稀疏检索方法,它通过计算查询词与文档之间的词汇重叠度来排序,对精确关键词匹配效果好但缺乏语义理解能力。与之对应的Text Embedding方法属于稠密检索,将文本映射到高维向量空间后通过余弦相似度等指标衡量语义相近程度,能捕捉同义词和语义关联但可能在精确匹配上不如BM25。
- LLM处理记忆类:Memo-Me、GraphTD。这类系统在信息写入时就利用大模型对原始对话进行加工处理,提取结构化事实或构建知识图谱,试图在存储阶段就完成信息的组织和关联。
- 文件代理类:Carp-Wiki、MD-Flat。这类系统赋予LLM文件操作能力,让它像人类管理笔记一样创建、编辑和查询Markdown文件或Wiki页面,理论上具有最大的灵活性。
所有系统统一使用GPT-4 Mini作为内部LLM和回答LLM,排除模型能力差异的干扰。
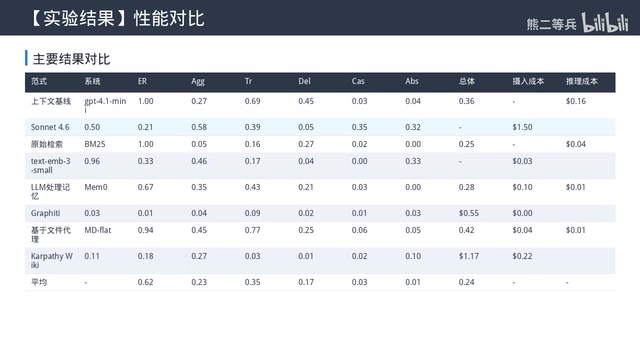
结果令人意外:表现最好的MD-Flat整体准确率也只有0.42。依赖推理类任务更是全面崩溃——级联任务平均准确率仅0.3,缺失任务更低至0.1,远低于静态任务的表现水平。
多实体+演化场景的叠加效应
- 从单实体到多实体:平均准确率下降0.31
- 从静态到演化:平均准确率下降0.228
- 两个维度同时满足(多实体+演化):准确率直接降到0.2
这恰恰是现实中最常见的场景——多个相关实体随时间不断变化,而现有系统在这种场景下几乎完全失效。
失败根因分析:检索瓶颈与推理断裂
检索阶段是核心瓶颈
论文将记忆系统分为编码、维护、检索三个阶段进行追踪分析,发现大部分系统的编码和维护阶段其实没有问题——规则和变更事件都好好存在存储里。问题集中在检索阶段:
- GraphTD:变更事件的边排在TopK之外,未被检索到
- Carp-Wiki:查询代理只看了旧文件,没打开存变更事件的新日志文件
- BM25:变更事件排序太低,因为变更描述中的关键词与用户查询的措辞不完全匹配,导致词频匹配得分偏低
- 少数系统(Text Embedding、Memo-Me)虽然检索到了变更事件,但回答LLM仍然使用了旧值,暴露出模型在面对新旧信息冲突时的推理缺陷
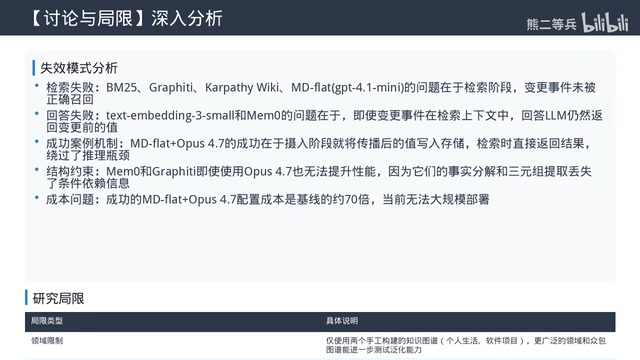
五种干预方式几乎全部失败
作者尝试了五种不改变架构的干预方式:
| 干预方式 | 效果 |
|---|---|
| 提示词优化(DSPY-SIM) | 级联和缺失准确率仍接近地板 |
| 增加检索深度(TopK→40) | 级联仍接近0,缺失略有提升后下降 |
| 更强回答LLM(Claude Sonnet 4) | 仅缺失任务略有提升 |
| 减少干扰内容 | 完全无效 |
| 更强内部LLM(Claude Opus 4) | 唯一有效,但成本是基线的70倍 |
其中,DSPY-SIM方案使用的是斯坦福大学开发的DSPY声明式框架,该框架允许开发者定义输入输出的签名和模块化的推理步骤,然后通过编译器自动搜索最优的提示词组合和少样本示例。然而实验结果表明,即使经过自动优化,提示词层面的改进对依赖推理任务的提升极为有限,说明问题的根源在架构层面而非指令层面。
唯一有效的方案是MD-Flat搭配Claude Opus 4——它在Ingest阶段会主动扫描依赖条目,将传播后的新值直接写入存储,绕过了检索瓶颈。但70倍的成本代价使其在实际应用中难以推广。
未来方向:从召回率优化到依赖传播机制
MEME基准第一次全面暴露了当前LLM记忆系统在依赖推理上的结构性缺陷。核心发现可以总结为三点:
- 瓶颈在检索而非存储:信息存进去了但取不出来,或取出来了但推理不对
- 传统调优手段基本无效:提示词优化、增加检索深度等常规手段对依赖推理任务几乎没有改善
- 需要架构层面的创新:比如在Ingest阶段主动做依赖传播,或优化检索排序逻辑让变更事件优先级高于旧值
所谓Ingest阶段的主动依赖传播,本质上是一种"写时传播"策略,类似数据库中的物化视图更新机制——当检测到上游实体变更时,立即沿依赖链计算所有下游实体的新值并写入存储,将计算成本从查询时前移到写入时,以空间和写入成本换取查询时的准确性。这一思路为下一代记忆系统的架构设计提供了重要参考。
此前业界更多关注记忆的召回率,现在MEME告诉我们:依赖传播才是更核心的痛点。这为下一代记忆系统的设计指明了方向——不仅要记得住,更要"想得通"。
核心要点
- MEME是首个覆盖级联、缺失、删除等六大记忆任务的完整评估基准,填补了现有基准在依赖推理测试上的空白
- 六大主流记忆系统全面翻车:最好的MD-Flat准确率仅0.42,级联任务平均仅0.3,缺失任务低至0.1
- 多实体+动态演化的现实场景下准确率降至0.2,现有系统在最常见场景中基本失效
- 失败根因集中在检索阶段而非存储阶段,提示词优化、增加检索深度等传统干预方式几乎无效
- 唯一有效方案是在Ingest阶段主动做依赖传播(Claude Opus 4),但成本是基线的70倍,指明了未来架构创新方向
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。