LLM推理能力演进:从思维链到DeepSeek-R1全解析

从思维链到推理模型,系统梳理LLM推理能力的技术演进路线
文章围绕GitHub开源项目Awesome-LLM-Reasoning,系统梳理了LLM推理能力的技术演进:从Chain-of-Thought提示技术开创推理研究,到Self-Consistency、Tree-of-Thought等改进方案,再到OpenAI o1引入推理时间计算新维度、DeepSeek-R1以开源方式揭示强化学习驱动的推理训练路径。当前研究正朝可扩展性、可靠性、效率优化和多模态推理四大方向发展。
引言
大语言模型(LLM)的推理能力,已经成为当前AI领域最热门的研究方向。从2022年Chain-of-Thought(思维链)提示技术的提出,到OpenAI o1模型的横空出世,再到DeepSeek-R1以开源姿态实现推理能力突破,这条技术演进路线正在深刻改变我们对人工智能的理解。
GitHub上的开源项目 Awesome-LLM-Reasoning 系统性地梳理了这一领域的发展脉络,目前已获得超过3600颗星标,成为研究者和开发者了解LLM推理技术的重要参考资源。
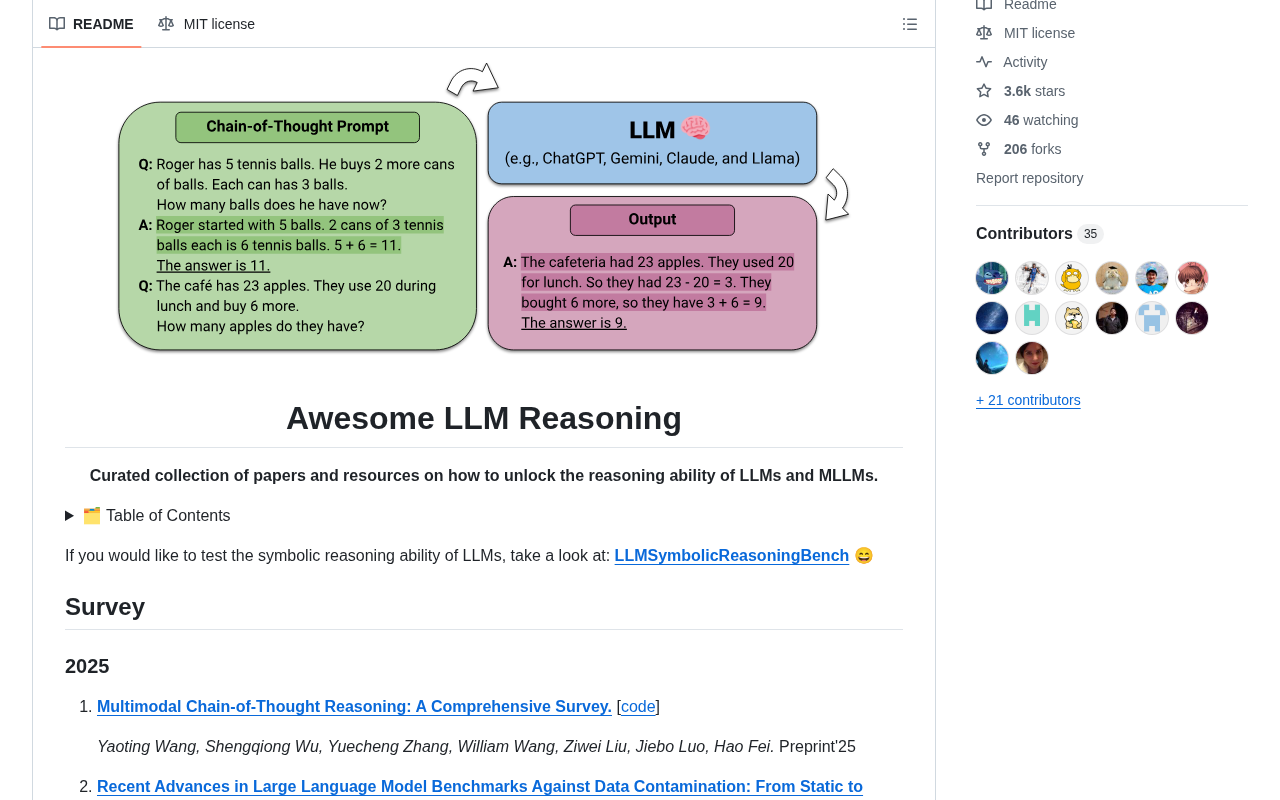
从思维链到推理模型:技术演进的完整路线
Chain-of-Thought:LLM推理的起点
Chain-of-Thought(CoT)提示是LLM推理能力研究的里程碑。2022年,Google的Jason Wei等人首次提出这一概念——在提示中加入逐步推理的示例,引导模型展示"思考过程",而不是直接输出答案。这个看似简单的技巧,却大幅提升了大模型在数学推理、逻辑推理和常识推理等任务上的表现。
CoT的提出建立在一个重要的认知科学发现之上:人类在解决复杂问题时,会将问题分解为多个中间步骤,而非直接从问题跳跃到答案。在CoT出现之前,研究者主要依赖few-shot prompting(少样本提示)来引导模型完成任务,但这种方式在需要多步推理的任务上效果有限。CoT的突破性在于,它不需要修改模型参数或架构,仅通过改变输入格式就能激发模型潜在的推理能力。后续研究还发现了Zero-shot CoT——仅需在提示中加入"Let's think step by step"这样的简单指令,就能在无需示例的情况下触发模型的逐步推理行为,这进一步证明了大模型内部已经具备了某种程度的推理潜力。
CoT的核心洞察在于:让模型"展示解题过程"本身就能提升推理质量。这和人类解题时"写出步骤"的道理一样——把思维过程外化,不仅便于检查,还能有效减少跳跃性错误。
从提示工程到模型内化:推理范式的升级
在CoT之后,研究社区迅速涌现出一系列改进方案:
- Self-Consistency(自一致性):多次采样不同推理路径,选择最一致的答案,提升推理鲁棒性
- Tree-of-Thought(思维树):将线性思维链扩展为树状搜索结构,允许模型探索多个推理分支
- Graph-of-Thought(思维图):进一步将推理结构泛化为图结构,支持更复杂的推理拓扑
- Step-by-Step Verification(逐步验证):引入过程奖励模型(PRM),对推理的每一步进行验证
其中,过程奖励模型(Process Reward Model, PRM)是相对于结果奖励模型(Outcome Reward Model, ORM)而言的一种更精细的评估方式。ORM只关注最终答案是否正确,而PRM对推理过程中的每一个中间步骤都给出评分。OpenAI在2023年发表的论文"Let's Verify Step by Step"中系统性地证明了PRM在数学推理任务中的优越性。PRM的训练需要大量的步骤级标注数据——标注者需要判断推理链中每一步是否正确,这使得数据获取成本较高。但PRM的优势在于它能更精确地定位推理错误发生的位置,从而指导模型改进特定的推理环节,而非仅仅知道最终结果对错。
这些方法从不同维度丰富了LLM的推理范式,但大多停留在推理阶段(inference-time)的技巧层面。真正的范式转变,来自将推理能力内化到模型训练过程中。
OpenAI o1与DeepSeek-R1:两条推理模型路线对比
OpenAI o1:闭源推理模型的先行者
OpenAI o1系列模型标志着"推理模型"这一全新品类的诞生。与传统LLM不同,o1在回答问题前会进行长时间的内部"思考",生成一条隐藏的推理链。这种设计使其在数学竞赛、编程和科学推理等高难度任务上取得了突破性成绩。
o1的关键创新在于将推理时间计算(test-time compute)作为提升模型能力的新维度。传统的Scaling Law(缩放定律)由OpenAI的Jared Kaplan等人在2020年提出,指出模型性能与训练数据量、模型参数量和训练计算量之间存在幂律关系。这一定律长期指导着大模型的发展方向——更大的模型、更多的数据、更长的训练时间。然而o1模型引入的test-time compute概念打破了这一单一维度的思维:即使模型参数固定,通过在推理阶段投入更多计算资源(如生成更长的思维链、进行多次采样和验证),也能显著提升输出质量。这被一些研究者称为"推理阶段的Scaling Law",它为提升AI能力开辟了一条不依赖于持续增大模型规模的新路径。
DeepSeek-R1:开源推理模型的里程碑
DeepSeek-R1的发布从另一个角度推动了推理模型的发展。作为开源模型,R1不仅展示了与o1相当的推理能力,更关键的是公开了训练推理模型的技术路径:
- 强化学习驱动推理训练:R1大量使用强化学习(RL)来训练模型的推理能力,而非单纯依赖监督学习
- 推理行为的自发涌现:在RL训练过程中,模型自发学会了自我验证、回溯和反思等推理策略
- 推理能力的蒸馏迁移:R1证明了大模型的推理能力可以有效蒸馏到参数量更小的模型中
DeepSeek-R1采用的强化学习训练范式与传统的监督微调(SFT)有本质区别。在SFT中,模型学习模仿人类标注的推理过程,这意味着模型的推理能力上限受限于标注数据的质量。而在RL训练中,模型通过与环境交互(如尝试解题并获得正确性反馈)来自主探索有效的推理策略。具体而言,R1使用了GRPO(Group Relative Policy Optimization)等强化学习算法,以数学题的最终答案正确性作为奖励信号。在这个过程中,模型自发涌现出了"aha moment"——即突然学会自我纠错和反思的行为,这种涌现现象在纯监督学习中极为罕见。这表明RL能够帮助模型发现人类标注者可能未曾想到的推理策略。
在蒸馏方面,知识蒸馏(Knowledge Distillation)最初由Geoffrey Hinton等人在2015年提出,核心思想是将大模型(教师模型)的知识迁移到小模型(学生模型)中。在推理模型的语境下,蒸馏的意义尤为重大:推理模型通常需要生成很长的思维链,这导致推理成本极高。DeepSeek-R1证明了可以将671B参数的大模型的推理能力蒸馏到7B、14B甚至1.5B的小模型中,且蒸馏后的小模型在推理任务上的表现远超同等规模的非推理模型。蒸馏的具体方式包括:使用大模型生成的推理链作为小模型的训练数据,或者让小模型学习模仿大模型的输出分布。这为推理模型的实际部署和边缘计算应用打开了大门。
DeepSeek-R1的开源意义深远。它让整个研究社区都能在此基础上进行探索和改进,极大地加速了推理模型技术的普及和迭代。
Awesome-LLM-Reasoning项目:研究者的技术地图
结构化的知识体系
该项目的核心价值在于提供了一份结构化的LLM推理技术地图。对于刚进入该领域的研究者,它提供了清晰的学习路径;对于资深研究者,它是追踪最新进展的高效工具。项目获得3600+星标和200+Fork,反映了社区对这类系统性资源的强烈需求。
当前LLM推理研究的四大趋势
从该项目收录的论文和技术方向来看,当前LLM推理研究呈现几个明显趋势:
- 推理能力的可扩展性:如何让推理能力随计算资源的增加而持续提升
- 推理的可靠性:如何减少推理过程中的幻觉和逻辑错误
- 推理的效率优化:如何在保持推理质量的同时降低计算成本
- 多模态推理:将推理能力从纯文本扩展到视觉、代码等多模态场景
LLM推理能力的未来发展方向
LLM推理能力的发展正处于一个关键节点。从技术层面看,有三个方向值得重点关注:
推理与规划的深度融合。 当前的推理模型主要擅长"给定问题求解",但在需要长期规划和多步决策的场景中仍有不足。将推理能力与Agent框架结合,让模型具备自主规划和执行的能力,是一个充满潜力的方向。Agent框架是指让LLM作为自主智能体,具备感知环境、制定计划、使用工具和执行行动的能力。当前主流的Agent架构包括ReAct(Reasoning + Acting)、AutoGPT、BabyAGI等。将推理模型与Agent框架结合的核心挑战在于:推理模型擅长在给定信息下进行深度思考,但Agent场景要求模型在信息不完整的情况下做出决策,并根据环境反馈动态调整策略。这涉及到从"单轮深度推理"到"多轮交互式推理"的范式转变。例如,一个具备强推理能力的Agent在执行复杂任务时,需要在每一步都评估当前状态、预测可能的结果、选择最优行动,这本质上是将推理能力应用于序贯决策问题。
推理能力的跨领域泛化。 目前推理模型在数学和编程领域表现突出,但在开放域推理、因果推理等方面仍有提升空间。如何让推理能力真正泛化到各类认知任务,是一个核心挑战。
推理过程的可解释性。 随着推理链变得越来越长和复杂,如何确保推理过程的透明性和可审计性,将成为推理模型走向实际应用的关键门槛。
结语
从Chain-of-Thought思维链的灵感突破,到OpenAI o1和DeepSeek-R1的系统性创新,LLM推理能力的演进速度令人瞩目。Awesome-LLM-Reasoning项目为我们提供了一个观察这场技术变革的全景窗口。
对于关注AI发展的研究者和开发者来说,理解LLM推理能力的技术脉络,不仅有助于把握当前的研究前沿,更能为未来的技术选型和研究方向提供参考。推理能力的持续进化,很可能是通向更强大、更可靠AI系统的关键路径。
核心要点
- Chain-of-Thought提示技术开创了LLM推理研究的先河,通过外化思维过程显著提升模型推理能力
- OpenAI o1将推理时间计算(test-time compute)确立为提升模型能力的新维度,开创了推理模型新品类
- DeepSeek-R1通过开源揭示了强化学习驱动的推理模型训练路径,加速了推理技术的民主化
- Awesome-LLM-Reasoning项目以3600+星标成为该领域最重要的系统性知识梳理资源
- LLM推理研究正朝着可扩展性、可靠性、效率和多模态四个方向持续演进
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。