MemGAS:多粒度记忆关联让AI Agent精准回忆

MemGAS提出多粒度记忆关联与自适应选择框架,让对话Agent在正确粒度上回忆。
ICLR 2026论文MemGAS针对对话Agent长期记忆中单一粒度难以兼顾细节与关系的问题,提出同时维护Session、Turn、Summary、Keyword四种粒度记忆,通过高斯混合模型建立可信关联,利用熵路由器自适应选择最优粒度,并借助Personalized PageRank实现联想式回忆。实验在四个基准上全面超越主流基线,验证了多粒度协同的有效性。
当一个用户和AI Agent聊了几个月,系统到底应该记住什么?是整段对话、每一句细节、摘要,还是关键词?来自ICLR 2026的MemGAS论文给出了一个清晰的回答:不能只选一个。这篇论文提出了一套多粒度记忆关联与自适应选择框架,让对话Agent不仅「会记住」,更关键的是「会在正确粒度上想起来」。
单一粒度记忆的困境
现有的对话记忆系统通常沿用RAG思路,把历史对话切成session、turn、summary或topic chunk,再做向量检索。部分方法会进一步构建树或图结构,但往往还是围绕单一层级运作——比如只用实体图或只用摘要索引。
问题在于,用户的问题经常跨会话、跨主题、跨时间。单一粒度很难同时保留细节和关系。比如用户问「我总共完成了几门在线课程」,如果系统只存了session级摘要,可能只找到「学习计划和职业建议」这样的粗粒度信息,而丢失了具体的课程数量;反过来,如果只存了turn级细节,又可能只命中其中一次对话,遗漏分散在不同会话中的信息。

这篇论文来自中国科学技术大学、香港城市大学和华为等机构,核心作者包括许德荣等人,论文标题为《From Single to Multi-Granularity: Toward Long-Term Memory Association and Selection of Conversational Agents》。
MemGAS的四种记忆粒度设计
MemGAS的核心设计是同时维护四种粒度的记忆单元:
- Session级:保留一整段会话,适合查看完整背景和上下文
- Turn级:保留具体轮次,适合查找日期、人名、数量等精确信息
- Summary级:用LLM压缩话题,提供中等粒度的语义概括
- Keyword级:用关键词和实体做精确锚点,支持快速定位
但关键不只是「多存几个索引」。MemGAS真正的创新在于记忆关联机制:当新对话进来时,系统会把不同粒度编码成向量,与历史记忆比较相似度,再用**高斯混合模型(GMM)**把历史记忆分成「相关集合」和「无关集合」。只有相关的旧记忆才会与新记忆建立连边,进入关联图。
为什么用GMM而不是固定阈值?
GMM解决的是「哪些旧记忆值得连边」这个问题。如果只按固定阈值切分,很容易受数据分布影响。GMM把相似度看成两类分布——一类更像相关记忆,一类更像无关记忆——这样新记忆不会盲目连到所有历史节点,而是只强化比较可信的关联。
熵路由器:自适应选择最优记忆粒度
查询来了以后,MemGAS怎么决定该用哪种粒度?这里用的是一个熵路由器(Entropy Router)。
系统分别计算查询在session、turn、summary、keyword四种粒度上的相似度分布。如果某个粒度的分布很集中(熵低),说明匹配更确定,就给它更高权重;如果分布很散(熵高),说明不确定,就降低权重。

举个直观的例子:用户问「我总共完成了几门在线课程」,turn级可能能精确命中「三门Coursera」和「两门edX」,而session级会带出很多学习计划和职业建议——此时细粒度更确定,权重更高。反过来,如果用户问「我最近主要在规划什么」,session或summary可能更合适,因为它们能提供完整的上下文脉络。
图传播机制:从精确检索到联想式回忆
普通的TopK检索只看谁和问题最像,而MemGAS引入了**Personalized PageRank(PPR)**在关联图上做传播。
具体流程是:先用加权相似度选出若干种子节点(seed nodes),再在图上做PPR扩散。这样一个关键词被命中后,和它稳定相连的session、turn、summary都有机会被带出来——更像是联想式回忆,而不是简单的模式匹配。

论文中的典型案例:用户分别在两次会话里提到完成了三门Coursera课程和两门edX课程。当问题问总数时,只检索到第一段会话会回答「三门」,而MemGAS的多粒度关联能通过共同主题和关键词把两段会话一起找回来,得到正确答案「五门」。
图传播的扩展与收窄平衡
图传播会不会把不相关内容也带出来?确实存在这个风险。所以MemGAS最后还有一个LLM过滤层,把TopK候选记忆和查询一起交给LLM,让它去掉重复、无关或噪声内容,只把最关键的上下文交给回答模型。也就是说:图负责扩展召回,过滤负责收窄上下文。
论文验证的两个关键超参数:种子节点数量在约15附近效果较好,熵温度参数在约0.2附近较稳。重点不是固定数值,而是让联想可以扩散但不能无边界扩散。
实验结果:MemGAS全面领先主流基线
论文在四个长期记忆基准上进行了评估:Locomo、LongMemEval-S、LongMemEval-M和LongMTBench Plus,基线包括FullHistory、Contriever、SEACOM、HIPPO RAG、RAPTOR、AMEM等主流方法。
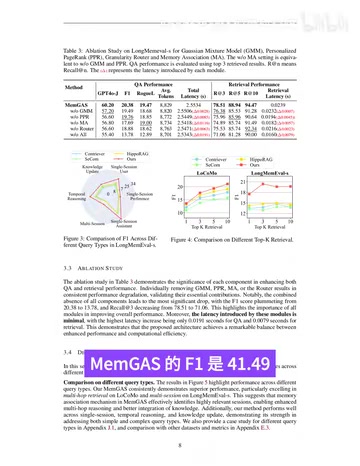
几个代表性数字:
| 数据集 | 指标 | MemGAS | 最强基线 |
|---|---|---|---|
| LongMemEval-S | F1 | 20.38 | 14.73 (HIPPO RAG) |
| LongMemEval-S | Recall@3 | 78.51 | 75.53 (HIPPO RAG) |
| LongMemEval-M | F1 | 16.85 | 11.88 (Contriever) |
| LongMTBench Plus | F1 | 41.49 | 36.07 (FullHistory) |
| Locomo | Recall@10 | 81.82 | 次优基线 |
消融实验也很直接:完整MemGAS的F1为20.38,去掉全部核心组件后降到13.78;单独去掉GMM、PPR、记忆关联或熵路由器,表现都会下降,说明每个模块都有独立贡献。
计算成本与资源开销分析
论文的结论是成本可控。在LongMemEval-S上,构建记忆处理约52.9M input tokens,接近原始语料规模;Summary和Keyword带来的额外内存约27MB,大约是原始记忆的10%;核心模块引入的检索延迟也很小。
局限性与实际落地挑战
尽管MemGAS在实验中表现优异,在真实产品中仍面临几个关键挑战:
- 摘要和关键词提取的稳定性:情绪化表达、隐含意图或非事实性碎片可能导致LLM提取不稳定
- 错误联想风险:相似度高不等于语义上应该关联,图结构可能产生误连
- 长期运维成本:记忆持续增长后,隐私管理、权限控制、遗忘机制、冲突更新和实时成本控制都是必须面对的问题
总结:从「会记住」到「会想起」的范式升级
MemGAS推进的是长期记忆系统的结构化范式:不要把对话历史当成一堆等待检索的文本块,而要把它拆成不同粒度,建立可信关联,再按问题自适应选择和传播。
它和知识图谱RAG、技能图有本质区别——知识图谱围绕实体关系,技能图围绕执行依赖,而MemGAS的记忆关联图节点背后是不同粒度的对话记忆,它不负责规划动作,而是负责在长期对话历史里找到既有细节又有上下文的证据。
对对话Agent来说,「会记住」还不够,关键是会在正确粒度上想起来。
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。