MEMOIR:用Git版本控制思维解决AI Agent记忆管理难题
MEMOIR用Git版本控制理念重新定义AI Agent记忆管理,解决上下文污染与记忆漂移问题。
MEMOIR是一个开源AI Agent记忆管理系统,将Git版本控制(分支、提交、合并、回滚)引入记忆管理,解决传统方案中上下文污染、记忆漂移和不可追溯的痛点。它采用语义路径替代扁平UUID实现层级化组织,双引擎(关键词精确匹配+LLM语义检索)并行检索,并提供多维可视化和多Agent协作支持,让AI记忆从黑盒变为可追溯、可调试的白盒。
AI Agent的记忆困境:上下文污染与记忆漂移
做过AI Agent开发的人都知道,记忆管理是整个系统中最让人抓狂的环节之一。随着对话轮次不断增加,上下文污染、Token浪费和记忆漂移这几个老大难问题就会接踵而至。
上下文污染(Context Pollution)是指在多轮对话中,无关或过时的信息不断累积在上下文窗口中,干扰模型对当前问题的理解和推理。记忆漂移(Memory Drift)则是指随着对话推进,Agent对早期信息的"记忆"逐渐偏离原始含义,产生语义失真。这两个问题的根源在于当前大语言模型的注意力机制——Transformer架构中的自注意力对所有Token赋予权重,当上下文过长时,早期关键信息的权重会被稀释,导致模型"注意力涣散"。目前主流LLM的上下文窗口从4K到200K Token不等,但研究表明即使在128K窗口下,模型对中间位置信息的召回率也会显著下降,这就是所谓的"Lost in the Middle"现象。
向量数据库虽然能存记忆,但它本质上是个黑盒——没有版本控制,无法回滚,调试起来更是无从下手。向量数据库(如Pinecone、Weaviate、Chroma等)通过将文本转换为高维向量嵌入(Embedding),利用余弦相似度或欧氏距离进行近似最近邻(ANN)检索。这种方式虽然能实现语义级别的记忆存取,但存在几个结构性缺陷:向量嵌入是有损压缩,原始语义信息在编码过程中不可避免地丢失;向量空间中的相似度并不总是等同于逻辑相关性,容易产生"语义幻觉"式的错误召回;最关键的是,向量数据库缺乏时序感知和版本管理能力,无法回答"这条记忆是什么时候产生的""它经历了哪些变化"这类问题,这使得调试和审计几乎不可能。
想象一下这个场景:你的Agent在第50轮对话中突然"忘记"了第3轮的关键信息,或者把两段毫不相关的上下文张冠李戴。这时候你想排查问题,却发现根本无从入手。MEMOIR这个项目的出发点,就是从根本上解决这类痛点——它把Git版本控制的理念搬到了AI记忆管理领域,构建了一套分层语义记忆系统。
核心设计:Git式版本控制 + 语义记忆
版本控制:让每一步记忆变化都可追溯、可回滚
MEMOIR最大的亮点,是把Git的版本控制机制完整移植到了AI记忆管理中。它支持分支(Branch)、提交(Commit)、**合并(Merge)和回滚(Rollback)**这些开发者熟悉的操作,同时用加密机制保障记忆数据的完整性。
Git的版本控制基于有向无环图(DAG)数据结构,每次提交都是一个不可变的快照,通过SHA-1哈希值保证数据完整性。分支本质上只是指向某个提交的可移动指针,合并则是将两条分支的变更历史整合为一条。这套机制之所以强大,在于它同时解决了三个问题:可追溯性(每次变更都有完整记录)、可逆性(任何操作都可以回滚)和并行性(多条分支可以独立演进)。MEMOIR将这些概念映射到AI记忆管理中,意味着每一次记忆的增删改都会生成一个带有加密哈希的快照,形成完整的记忆演化链条,从根本上解决了传统方案中记忆变更不可追踪的问题。
这套机制带来的实际好处非常直接:当Agent在某次对话中产生了错误的记忆关联,你可以像操作Git仓库一样,精确回滚到某个"记忆快照",逐步排查到底是哪一步出了问题。对于需要可复现测试的场景,这种能力更是不可或缺——你完全可以在不同的记忆分支上测试不同策略,最后把效果最好的那个合并进来。
语义路径:告别扁平化的UUID存储
传统方案通常用扁平化的UUID索引来管理记忆,所有条目堆在同一层级,查找效率低,组织结构也很混乱。UUID(通用唯一标识符)是一种128位的随机标识符,所有条目在逻辑上处于同一层级。这种方式在数据量较小时尚可应对,但当记忆条目达到数万甚至数十万级别时,检索效率急剧下降,因为缺乏层级结构意味着每次查询都可能需要遍历大量无关条目。
MEMOIR用**语义路径(Semantic Path)**取代了这种方式,实现了层级聚合和对数级的快速查找。语义路径借鉴了文件系统的层级目录结构和知识图谱的本体论(Ontology)思想,将记忆按照语义关系组织成树状或图状结构。这种设计使得检索复杂度从O(n)降低到O(log n),同时路径本身就携带了丰富的上下文信息——看到路径就能理解这条记忆的归属和含义,大幅降低了认知负担。
说白了,记忆不再是一堆散乱的碎片,而是按语义关系组织成了树状结构。比如"项目A/需求讨论/第三轮修改"这样的路径,既符合人类的认知习惯,检索效率也大幅提升。这种设计思路对处理复杂的长期记忆尤其有效。
双引擎检索:精确匹配与智能检索并行
MEMOIR在检索层采用了双引擎架构,这一设计理念源自信息检索领域的混合检索(Hybrid Search)范式,两条路径各司其职:
- 关键词精确匹配引擎:基于倒排索引(Inverted Index)技术,类似于Elasticsearch的工作原理,通过分词、建立词项到文档的映射关系来实现毫秒级精确查找。当你明确知道要找什么时,它能提供毫秒级的精确定位。
- 大模型智能检索引擎:借助LLM的语义理解能力,处理模糊查询和语义关联检索。例如用户问"之前讨论的那个性能问题",LLM能够理解这里的"性能问题"可能对应记忆中的"延迟优化""QPS瓶颈"等不同表述,实现同义词替换和隐含语义关联的识别。
这两个引擎互为补充,覆盖了不同的使用场景。纯关键词匹配搞不定语义近似的问题,而纯LLM检索在精确查找时既慢又贵——双引擎的设计恰好规避了单一方案的短板。两个引擎的协同策略通常采用"先粗筛后精排"的级联模式:实际开发中,大部分检索请求可以先走关键词引擎快速过滤缩小候选集,只有在需要语义理解时才调用LLM对候选结果进行语义重排序,这样既控制了API调用成本,又保证了检索的语义准确性,既省Token又保证了检索质量。
多维可视化:让Agent记忆看得见摸得着
MEMOIR内置了多种可视化探索视图,包括树状视图、图状视图和时间线视图,支持一键在浏览器中打开,让你直观地浏览Agent的整个记忆结构。
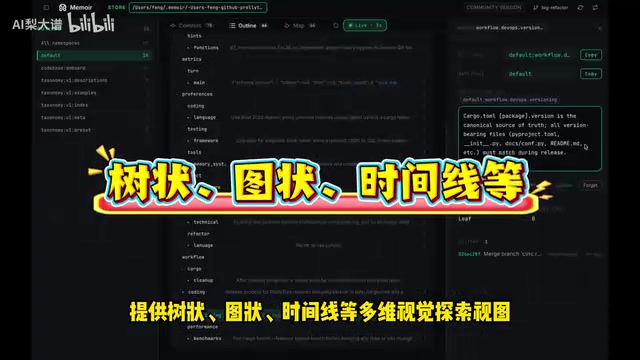
这个功能对调试和优化Agent行为的帮助非常大。当你能用图形化的方式看到记忆之间的关联关系、时间演变和层级结构时,定位问题的效率会提升好几个量级。跟在日志文件里大海捞针相比,可视化探索的体验完全不在一个层面上。尤其是在排查记忆漂移问题时,时间线视图能让你清楚地看到记忆是从哪个节点开始"跑偏"的。
工程化集成:开箱即用的开发体验
CLI与Python API双端支持
MEMOIR同时提供CLI命令行和Python API两种接入方式。命令行适合快速调试和脚本化操作,Python API则方便在代码中深度集成。在模型适配方面,它兼容多家主流大模型,迁移成本很低。
自动化钩子与多Agent协作
项目支持Claude和Codex插件的自动钩子(Hook)机制,能自动完成上下文注入和记忆捕获,省去了手动编写记忆管理代码的麻烦。钩子(Hook)是软件工程中的经典设计模式,它允许在特定事件发生时自动触发预定义的操作,无需修改核心业务逻辑。在AI Agent开发中,这意味着在对话开始时自动注入相关历史记忆(上下文注入),在对话结束时自动提取和归档新产生的关键信息(记忆捕获),实现记忆管理的全自动化。
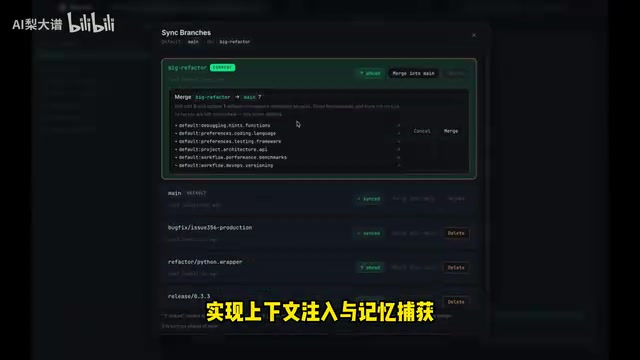
在多Agent协作场景中,MEMOIR支持离线路径操作与在线自动分类。这涉及分布式系统中的经典挑战——数据一致性与隔离性的平衡。离线路径操作类似于Git的本地分支,每个Agent在自己的记忆空间中独立工作;在线自动分类则类似于持续集成(CI),当Agent产生新记忆时,系统自动将其分类到正确的语义路径下,并在需要时通过类似Git Pull的机制与其他Agent同步共享信息。不同Agent可以各自维护独立的记忆空间,需要时又能共享和同步关键信息。整个工具通过pip一键安装即可使用,上手门槛很低。
适用场景与价值分析
MEMOIR在以下几类开发场景中能发挥最大价值:
- 长对话AI Agent开发:需要在数十甚至上百轮对话中保持记忆一致性的场景
- 多Agent协作系统:多个Agent之间需要共享和隔离记忆的复杂架构
- 可复现的回归测试:需要精确控制Agent记忆状态来做自动化测试
- Agent行为调试:需要追踪和排查Agent异常行为的根因
从技术架构的角度来看,MEMOIR的核心价值在于把软件工程中久经验证的版本控制理念与AI记忆管理结合起来,补上了当前AI Agent开发工具链中记忆管理这块短板。它不是在做一个更好的向量数据库,而是重新定义了AI记忆应该如何被组织、检索、追踪和调试。
总结:让AI记忆从黑盒变白盒
对于正在开发AI Agent的团队和个人开发者而言,MEMOIR提供了一套系统化的记忆管理解决方案。Git式版本控制、语义路径组织、双引擎检索加上多维可视化,这几项能力组合在一起,让AI记忆从"黑盒"变成了"白盒"——可追溯、可调试、可回滚。如果你正被Agent的记忆管理问题困扰,这个开源项目值得花时间深入了解和实际试用。
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。