memU记忆框架解读:用文件系统统一多模态Agent记忆

memU项目将AI Agent记忆组织为文件系统,实现层级化持久记忆管理。
memU是一个Agent Memory框架,核心创新在于将记忆映射为文件系统结构(文件夹=类别、文件=条目、符号链接=关联)。它采用对话层→条目层→类别层的三层语义抽象架构,通过Agent Loop与memU Loop双循环协作实现主动记忆,并提供RAG和LLM两种检索模式。文章同时讨论了Agent Memory领域面临的评测标准不统一、方法雷同等挑战,以及知识内化等未来方向。
Agent Memory的发展方向之争
Agent Memory是指为AI智能体提供跨会话持久化记忆能力的技术体系。传统大语言模型本质上是无状态的——每次对话结束后,上下文信息随之消失。为解决这一问题,研究者和工程师开发了各类外挂式记忆系统,使Agent能够"记住"用户偏好、历史交互和领域知识。这一领域近年来随着ChatGPT Memory功能的推出和各类Agent框架的兴起而快速发展,成为构建个性化AI助手的关键基础设施。
在深入memU项目之前,有必要先聊聊Agent Memory领域当前的发展态势。根据社区讨论和投票数据,Memory技术的未来走向大致分为几个方向:
- 强化学习与知识内化:获得最多支持,被认为是Memory的终极目标。既然大语言模型本身是参数化的权重文件,为什么不能将记忆直接内化到模型中?这类似于自动驾驶领域的端到端思路。将记忆内化到模型参数的思路,本质上是通过持续学习(Continual Learning)或在线强化学习让模型权重随交互经验动态更新。这与当前主流的外挂式记忆系统形成根本性区别——前者将知识编码在神经网络权重中,后者依赖外部存储和检索。知识内化的核心挑战在于"灾难性遗忘"(Catastrophic Forgetting)问题——模型在学习新知识时往往会覆盖旧知识,这是持续学习领域尚未完全解决的难题。
- 仿生与类脑:借鉴神经科学和认知科学的路线,与计算机科学路线形成互补。
- 分层迁移与评分:当前主流做法,包括短期/中期/长期记忆、L1/L2/L3层级等。
- 知识图谱与多模态:相对较新的探索方向。
一个值得关注的现实问题是:几乎所有Memory框架都围绕CRUD(Create、Read、Update、Delete)四个操作展开。CRUD是数据库领域的经典操作范式,代表对数据的四种基本操作,在Memory框架中对应记忆的创建、读取、更新和删除。这些框架通过embedding做向量检索——即将文本转化为高维向量,通过计算余弦相似度等指标找到语义相近的记忆条目——方法高度雷同。Locomo等评测数据集也被"刷烂"了,不同框架使用不同的judgment prompt(用于让LLM判断答案是否正确的提示词),导致分数缺乏可比性。这种"审美疲劳"正在推动社区寻找新的突破口。
memU的核心设计:记忆即文件系统
memU项目的核心创新在于将记忆组织为文件系统。文件系统作为操作系统的核心抽象,已有数十年的发展历史,具备极强的通用性和可理解性。将记忆映射到文件系统的思路,本质上是借用人类已经熟悉的信息组织心智模型。这个设计理念与近期Harness概念工程的趋势一脉相承——无论是Claude Code的读写Markdown,还是各种CLI工具和Agent框架,文件系统正在成为一种通用的信息组织范式。
文件系统的组织结构
memU的记忆存储采用以下层级:
- 文件夹 = 类别:自动组织的主题文件夹,如
preferences/、relationships/、knowledge/、context/ - 文件 = 记忆条目:每个Markdown文件存储提取的事实、偏好、技能等
- 符号链接 = 关联记忆:符号链接(Symbolic Link)是Unix/Linux系统中的一种特殊文件,指向另一个文件或目录,类似于快捷方式。memU借此机制表达记忆之间的关联关系,使得同一条记忆可以在多个类别下被引用而无需重复存储。
- 挂载点 = 外部资源:挂载点(Mount Point)是将外部存储设备或资源接入文件系统树的机制,memU借此概念实现对对话、文档、图像等原始资源的引用,做到"有据可循"。
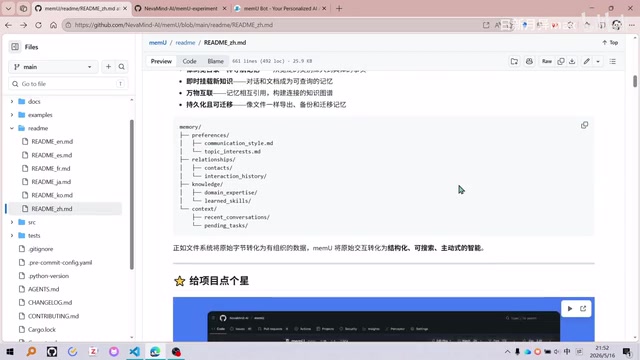
这种设计带来了几个实际好处:浏览目录即可导航记忆,从宽泛类别逐步深入到具体事实;记忆以文件形式存在,天然支持导出、备份和迁移;新知识通过挂载成为可查询的记忆,做到"有据可循"。
三层记忆抽象架构
memU设计了从原始数据到高层语义的三级抽象:
第一层:对话层(资源层)——存储用户与Agent对话的原始数据,包括用户提问、Agent回复以及多模态信息。这是最底层的原生数据。
第二层:条目层(Item Layer)——从对话中提取事实性记忆,通过大模型将原始对话转化为结构化条目。条目涵盖情景记忆、语义记忆、感知记忆、过程记忆等多种类型。
第三层:类别层(Category Layer)——将条目进一步组织为摘要级概览,生成更高抽象级别的语义文件。例如将所有profile相关条目整合到profile/文件夹下的多个Markdown文件中。
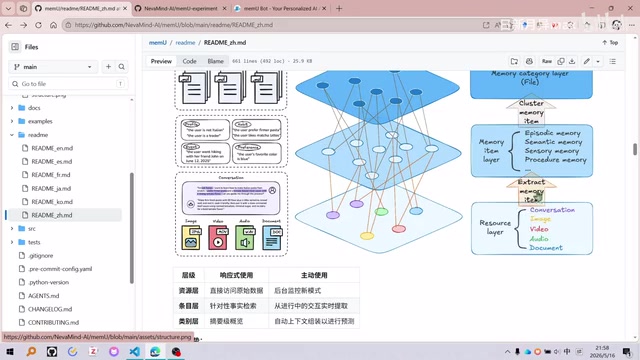
这实现了从对话→条目→文件的逐级语义抽象过程,是memU区别于其他Memory框架的关键特征。
主动记忆的工作原理
memU强调的两大优势是主动智能体和降低token成本。其工作原理涉及两个并行循环:
双循环协作机制
Agent Loop(主循环):用户通过飞书等平台发送请求,Agent接收输入、规划执行、返回响应,形成标准的对话循环。
memU Loop(记忆循环):memU软件作为独立插件实时运行,执行以下操作:
- 监测:实时跟踪用户输入输出,观察Agent行为,记录对话轨迹
- 存储与检索:通过记忆功能实现记忆的更新和注入
- 提取:从Agent的思考和工具调用中提取skills、知识,更新用户画像
- 预测与建议:根据返回结果预测用户意图,执行主动任务,向Agent Loop提供建议
关键在于memU会将记忆注入到飞书机器人中,使其能够"记住"之前存储的信息。memU本质上是一个独立运行的记忆插件,与主Agent形成协作关系。
代码架构解读
memU的代码结构清晰,核心实现集中在src/memu/目录下。
核心模块
App目录——最核心的服务层:
service.py:核心服务入口,也是云端部署的主文件memorize.py:记忆存储实现(约1000+行),负责将对话数据提取为条目,再通过冲突消解整理为文件retrieve.py:记忆检索实现(约1000+行),提供两种检索方式crud.py:记忆的增删改查操作实现
两种检索模式
基于RAG的检索:RAG(Retrieval-Augmented Generation,检索增强生成)是当前AI应用中最主流的知识增强技术之一,其核心思路是在生成回答前先从外部知识库中检索相关内容,将检索结果与用户问题一同输入大模型。在memU中,RAG检索速度快,直接通过embedding在知识库中检索并拼接结果,适合对延迟敏感的场景。
基于LLM的检索:更深度的推理,包括意图预测、查询改写(rewrite)、查询演化等步骤,最终将检索到的记忆与query合并(merge context)后交给Agent回答。这种方式通过意图理解弥补了纯向量检索可能遗漏需要推理才能关联的记忆的不足,但代价是更高的延迟和token消耗。两种模式在速度与精度之间提供了明确的权衡选择。
Prompts目录
这是另一个值得认真研读的目录。Memory系统的核心能力很大程度取决于prompt的设计质量。memU将prompt组织为JSON字符串形式,按功能分类存放,如retrieve/下包含reranker和rewrite等子模块。
配置要求
与大多数Memory框架类似,memU需要两个基础配置:
- LLM API:用于记忆的提取、存储和推理操作
- Embedding API:用于向量化检索
项目支持通过UV管理虚拟环境,依赖Rust运行时,支持Telegram、Discord、Slack和飞书四种接入方式。
性能与局限性思考
memU在Locomo测试中达到了92%的准确率,覆盖单跳、多跳、开放域和时序等多种场景。Locomo(Long-Context Conversation Memory)是专为评估对话记忆系统设计的基准数据集,包含长达数月的多轮对话记录,涵盖单跳推理(直接从记忆中找答案)、多跳推理(需要关联多条记忆)、开放域问答和时序理解等多种任务类型。但正如社区讨论所指出的,当前评测基准本身存在局限性——不同框架使用不同的judgment prompt,分数的绝对值缺乏可比性,这一"评测污染"现象在NLP评测领域普遍存在。
从实际应用角度看,除了token成本外,记忆的存储和检索时间成本同样关键。过于复杂的框架在检索和增删改查上的延迟可能已经不符合实际应用需求。memU通过文件系统的方式在一定程度上简化了这个问题,但在大规模记忆场景下的性能表现仍需验证。
Memory领域目前面临的核心挑战不在于框架设计的复杂度,而在于如何在简洁性、实用性和记忆质量之间找到平衡点。memU的文件系统思路提供了一个有趣的视角——将记忆问题转化为文件管理问题,这或许能降低系统复杂度,同时保持足够的灵活性。
核心要点
- memU将记忆组织为文件系统结构,通过文件夹=类别、文件=条目、符号链接=关联的方式实现层级化记忆管理
- 采用三层抽象架构:对话层(原始数据)→条目层(结构化提取)→类别层(语义文件),实现逐级语义抽象
- 通过Agent Loop和memU Loop双循环协作机制实现主动记忆,memU作为独立插件实时监测、存储、检索和注入记忆
- 提供基于RAG(快速)和基于LLM(深度推理)两种记忆检索模式,在速度和精度间提供选择
- Agent Memory领域面临评测标准不统一、方法高度雷同(CRUD+embedding)的挑战,强化学习与知识内化被认为是未来方向
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。