Mercury 2 实测:扩散模型驱动的最快推理大模型,18秒生成完整游戏
Inception Labs发布基于扩散模型的Mercury 2,推理速度超1000 Token/秒,颠覆传统自回归生成范式。
Inception Labs推出Mercury 2,一款基于扩散模型的大语言模型,通过并行生成和迭代优化文本,实现每秒超1000 Token的推理速度,是主流模型的5倍。与GPT等自回归模型逐词生成不同,Mercury 2采用类似"先写初稿再润色"的方式,打破串行计算瓶颈。在AIME数学测试中获91.1分,代码生成、结构化推理和规则遵循等实测中均表现优异,证明速度提升未牺牲质量。
Inception Labs 近日发布了 Mercury 2,一款基于扩散模型构建的大语言模型,号称全球推理速度最快。与 GPT、Claude 等自回归模型逐词生成的方式不同,Mercury 2 能够并行生成文本并迭代优化输出,实测达到每秒超过 1000 个 Token。这不只是速度层面的提升,更代表了一种全新的文本生成范式。
扩散模型 vs 自回归模型:范式级的差异
我们熟悉的 GPT、Claude、Gemini 等模型都属于自回归(Autoregressive)架构,核心工作方式是逐词生成——每次只预测下一个 Token,再基于已生成的内容继续预测。这种方式虽然成熟可靠,但天然存在速度瓶颈:生成 1000 个 Token 就需要执行 1000 次前向推理。
自回归模型的核心限制在于其串行计算特性。每次前向推理(Forward Pass)都需要将整个上下文(包括已生成的所有 Token)重新输入模型,才能预测下一个 Token。即便使用 KV Cache(键值缓存)技术来复用历史计算结果,顺序依赖的本质限制依然存在——因为第 N 个 Token 的生成依赖于第 N-1 个 Token 的结果,这些运算无法并行化。这也是为什么当前主流模型在实时对话场景中往往存在明显的首字延迟(Time to First Token)和整体生成延迟。
Mercury 2 采用的扩散模型思路完全不同。它的工作方式更像一位编辑:先并行生成整个回答的初稿,然后通过多轮迭代逐步润色优化。这意味着它可以在一步中同时处理多个 Token,从根本上打破了顺序生成的限制。
扩散模型最初在图像生成领域大放异彩,Stable Diffusion、DALL-E 2 等模型通过「加噪-去噪」的迭代过程生成高质量图像。将这一范式迁移到文本领域面临根本性挑战——文本是离散的 Token 序列,而非连续的像素值,无法直接套用连续空间的扩散过程。早期的离散扩散语言模型(如 MDLM、SEDD)通过在 Token 嵌入空间或掩码空间中定义扩散过程来解决这一问题。Mercury 系列正是在这一研究方向上的商业化突破,代表了离散扩散语言模型从学术原型走向生产可用的重要里程碑。
从实际跑分来看,Mercury 2 的生成速度达到了 Claude Haiku 4.5 和 GPT-5 Mini 等速度优化模型的 5 倍,同时在 AIME 基准测试中取得了 91.1 的高分,说明速度提升并没有以牺牲推理质量为代价。
AIME(American Invitational Mathematics Examination,美国数学邀请赛)是美国高中数学竞赛体系中的重要赛事,题目以高难度的数论、代数、组合数学和几何问题著称。在 AI 评测领域,AIME 已成为衡量模型数学推理能力的黄金标准之一,满分为 150 分(15 题×10 分)。Mercury 2 取得 91.1 分意味着其数学推理能力已达到顶尖水平,与 OpenAI o 系列、DeepSeek-R1 等专注推理的模型处于同一竞争梯队。这一成绩对扩散模型尤为重要,因为它打破了外界对「并行生成会损害逻辑连贯性」的质疑。
实战测试:代码生成能力全面对比
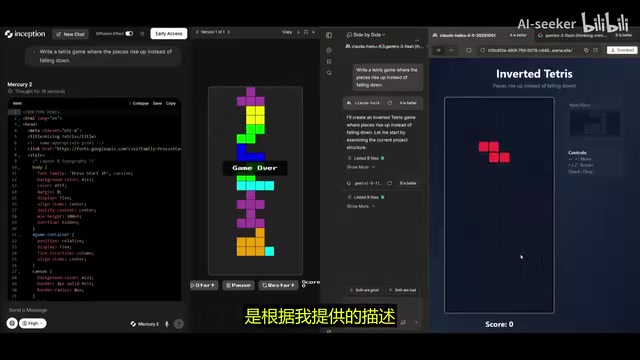
俄罗斯方块游戏生成
在一个颇具挑战性的测试中,作者要求各模型生成一个「方块上浮而非下落」的俄罗斯方块游戏。结果差异明显:
- Gemini 3 Flash:耗时约 1 分 08 秒,生成的游戏甚至无法运行
- Claude Haiku 4.5:耗时 1 分 24 秒,物理机制实现正确
- Mercury 2:仅用 18 秒,生成了完全可玩的游戏,且正确遵循了方块上浮的设定
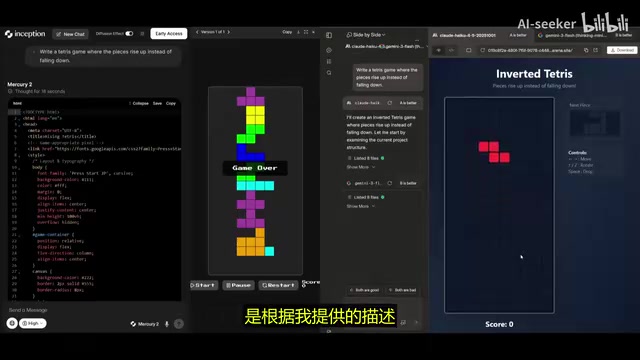
如果将推理强度调低,Mercury 2 甚至可以在几秒内完成代码生成。开启扩散模式后,可以直观看到答案并行生成的过程——指令刚发出,代码几乎瞬间完成。
MacOS 风格网页操作系统
在前端开发能力测试中,作者要求 Mercury 2 在高推理模式下编写一个 MacOS 风格的网页版操作系统,包含 SVG 图标。通常这类任务需要几分钟,而 Mercury 2 仅用了 12 秒就搭建出了基础前端框架,包括完整的组件结构和 SVG 图标代码。虽然各应用程序的完整逻辑尚未写全,但作为快速原型搭建工具,表现已经相当出色。
物理模拟:500 颗恒星的星系
更令人印象深刻的是一个物理模拟测试:生成包含 500 颗恒星的星系,恒星通过引力相互作用,并支持点击添加超大质量黑洞。Mercury 2 不仅成功生成了可运行的代码,还准确模拟了多个黑洞对周围恒星的引力影响,展现了出色的多步编码和算法推理能力。
结构化推理与规则遵循能力
速度快只是 Mercury 2 的一个维度,它在结构化推理方面同样值得关注。
客户支持场景测试
作者将模型设定为技术支持专员,要求用小学五年级的通俗水平解释智能恒温器的 WiFi 连接问题。Mercury 2 在极短时间内给出了十步解决方案,同时满足了多项严格要求:阅读难度控制、避免专业术语堆砌、正确的文本排版格式。

基于规则的客服智能体
在更复杂的客服场景中,模型需要执行严格的退换货规则(如 45 天时限),同时抵抗用户施压,保持角色一致性。Mercury 2 正确理解了时限约束,通过恰当的询问引导用户,稳定遵循了结构化规则,没有出现角色偏离或逻辑错误。
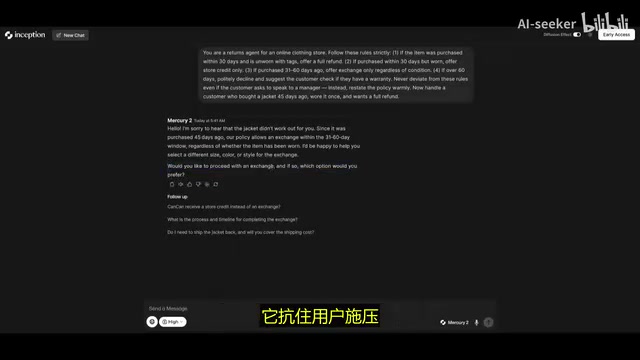
这也体现了扩散模型在避免累积错误方面的天然优势。自回归模型存在一个被称为「曝光偏差」(Exposure Bias)的固有问题:训练时模型看到的是真实的历史 Token,而推理时却依赖自身生成的 Token 作为输入。一旦某个位置生成了错误的 Token,这个错误会被后续所有生成步骤继承和放大,形成累积误差。扩散模型通过全局并行生成从根本上规避了这一问题——它在每次迭代中可以「回头修正」之前生成的内容,类似于人类写作时的草稿-修改流程,而非自回归模型的「一笔写就、无法回头」。这也解释了为何 Mercury 2 在需要精确遵循多条规则的客服场景中表现稳定。
长程规划能力:递增句子长度的故事创作
一个特别有意思的测试考察了模型的全局规划能力:要求从两个单词的句子开始,逐步增加句子长度直到 20 个单词,同时保持叙事连贯。这对自回归模型来说极具挑战,因为需要在生成过程中持续追踪和规划句子长度。
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。