Meta Muse Spark技术解析:三维度Scaling如何实现10倍算力缩减
Meta发布Muse Spark,预训练效率较前代提升10倍以上,瞄准"个人超级智能"。
Meta公开了Muse Spark模型的技术细节,通过模型架构、优化算法和数据策展三方面重构预训练技术栈,实现了比Llama 4 Maverick减少超过10倍计算量的效率突破。该模型沿预训练、强化学习和测试时推理三个维度系统性研究Scaling特性,目标定位为"个人超级智能",标志着大模型竞赛从堆算力转向提效率。
Meta近日公开了其最新模型Muse Spark的技术细节,围绕"个人超级智能"(Personal Superintelligence)这一宏大愿景,详细阐述了模型在预训练、强化学习和测试时推理三个维度上的Scaling特性。最引人注目的是,Muse Spark在预训练效率上实现了超过一个数量级的计算量缩减,展现出极强的工程能力。
Muse Spark预训练效率:比Llama 4 Maverick省10倍以上算力
Meta团队在过去9个月里,对预训练技术栈进行了全面重构,涵盖三个核心方向:
- 模型架构改进:优化了底层网络结构设计
- 优化算法升级:提升了训练过程的收敛效率
- 数据策展优化:更精细地筛选和组织训练数据
这三项改进的共同目标是:从每一单位计算资源中提取更多的模型能力。
值得注意的是,**数据策展(Data Curation)**已被越来越多的研究证明是影响模型能力的关键变量,而非辅助手段。早期大模型研究倾向于"数据越多越好",但微软Phi系列模型的成功打破了这一认知——Phi-1仅凭不到7B参数和高质量合成数据,在代码任务上超越了参数量大得多的竞争对手。数据策展的核心技术包括基于困惑度(Perplexity)的质量过滤、MinHash LSH去重算法、领域配比优化,以及利用强模型对数据进行质量打分。高质量数据能让模型在更少的Token上学到更多,直接降低达到目标性能所需的总计算量。Meta将数据策展列为三大支柱之一,表明其在数据质量维度上可能实现了系统性突破,而非单纯依赖架构创新。
为了严格验证新方案的效果,团队采用了经典的Scaling Law方法论——先在一系列小模型上拟合缩放定律曲线,然后比较达到特定性能水平所需的训练FLOPs(浮点运算次数)。
Scaling Law(缩放定律)是现代大模型研究的核心理论工具,最早由OpenAI在2020年的Kaplan等人论文中系统化提出,其核心发现是:模型性能与参数量、数据量、计算量之间存在幂律关系(Power Law)。2022年DeepMind的Chinchilla论文进一步修正了这一理论,指出业界普遍存在"模型过大、数据不足"的训练失衡问题,并提出了更优的参数量与数据量配比公式。通过比较"达到同等性能所需的FLOPs",可以排除模型规模差异的干扰,直接衡量训练效率本身的进步——这是一种严格且被业界广泛认可的基准测试方法。
这里的**FLOPs(浮点运算次数)**是衡量深度学习训练计算量的标准单位,通常由"6 × 参数量 × Token数量"这一经验公式近似估算。使用FLOPs而非"GPU小时"或"训练时间"作为效率指标,是因为它与具体硬件无关,能够更公平地跨代际、跨厂商进行比较。
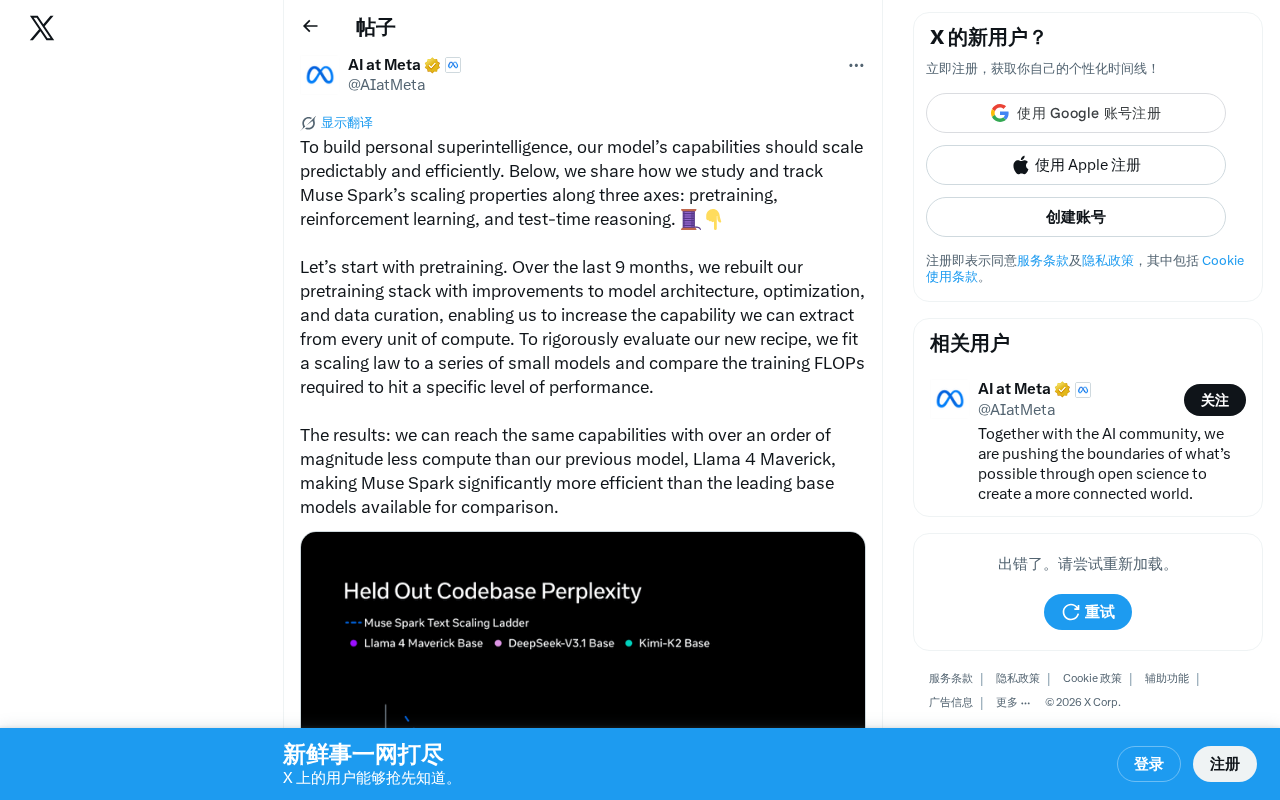
结果相当惊人:Muse Spark达到相同能力水平所需的计算量,比上一代模型Llama 4 Maverick减少了超过一个数量级(10倍以上)。这意味着在同等算力预算下,Muse Spark能够获得远超前代的模型能力,或者说达到同样的性能只需要十分之一的训练成本。在FLOPs层面实现10倍以上的压缩,通常需要架构、优化器和数据质量的协同改进才能达到,单一因素很难实现如此量级的提升。
Meta还特别指出,这一效率不仅优于自家前代模型,也"显著优于可供比较的领先基础模型",暗示其预训练效率已经处于行业前沿。
三维度Scaling战略:Muse Spark的完整能力提升框架
Meta为Muse Spark规划了三个Scaling维度,形成了一套完整的能力提升框架:
预训练Scaling:奠定基础能力
这是模型的基础能力来源。通过上述架构、优化和数据三方面的改进,Meta已经证明了在这一维度上的显著突破。预训练效率的提升意味着团队可以用同样的资源训练出更强的基座模型,或者以更低的成本快速迭代。
强化学习Scaling:精细化能力对齐
在预训练之后,通过强化学习进一步对齐和增强模型能力,已经成为当前大模型开发的标准范式。**强化学习(RL)**在大模型中最具代表性的形式是RLHF(基于人类反馈的强化学习),由OpenAI在InstructGPT和ChatGPT中率先大规模落地:首先收集人类对模型输出的偏好标注,训练奖励模型(Reward Model)来模拟人类判断;然后用PPO(近端策略优化)等算法优化语言模型,使其输出获得更高的奖励分数。近年来,DeepSeek-R1等模型进一步探索了纯RL训练路径,证明RL不仅能对齐模型行为,还能激发出自发的推理链条等涌现能力。Meta将RL作为独立的Scaling维度来研究,意味着他们正在系统性地探索"投入更多RL计算资源能带来多少能力增益"这一规律,有望形成RL阶段的类似预测公式,说明他们在这一环节有系统性的方法论来追踪和预测能力增长。
测试时推理Scaling:按需释放更强智能
这是近一年来行业最热门的方向之一。**测试时推理Scaling(Test-Time Compute Scaling)**由OpenAI o1系列模型的发布引爆了行业讨论,其核心思想是:在推理阶段投入更多计算资源,让模型"多想一会儿",从而在不更新模型权重的前提下提升复杂任务的表现。具体实现路径包括:Chain-of-Thought(思维链)让模型逐步推理而非直接输出答案;Best-of-N采样生成多个候选答案后择优;蒙特卡洛树搜索(MCTS)在推理空间中进行系统性探索;以及Process Reward Model(过程奖励模型)对推理中间步骤打分引导搜索方向。DeepMind的研究表明,测试时计算与训练时计算在某些任务上存在可互换性——即"推理时多花10倍算力"有时等效于"训练时多花数倍算力"。Meta将其纳入Scaling框架,表明Muse Spark很可能具备强大的推理时计算能力,对于数学、编程、科学推理等复杂任务尤为有效。
Meta的"个人超级智能"愿景意味着什么
Meta将Muse Spark的目标定位为"个人超级智能",这一表述值得关注。它暗示Meta的AI战略不仅仅是打造通用大模型,而是要构建能够深度服务个人用户的超强AI助手。这与Meta在社交平台上的庞大用户基础高度契合——如果每个用户都能拥有一个"超级智能"级别的AI伙伴,其商业想象空间巨大。
从技术路线来看,三维度Scaling的框架也体现了Meta的务实思路:预训练提供基础能力,RL实现精细对齐,测试时推理则在实际使用中按需释放更强的智能。这种分层递进的设计,既保证了效率,也为持续的能力提升留出了空间。
Muse Spark对AI行业的启示
效率比规模更重要。 Muse Spark的案例再次证明,在大模型竞赛中,单纯堆算力已经不是最优解。通过架构创新、优化改进和数据工程的协同提升,可以实现"用更少的资源做更多的事"。这对于整个行业的可持续发展不能忽视——当训练成本持续下降,AI的普及速度将进一步加快。
Meta在开源Llama系列的同时,推出Muse Spark这样的闭源高效模型,也反映出其双轨并行的AI战略正在加速推进。
核心要点
- Muse Spark达到相同能力水平所需计算量比Llama 4 Maverick减少超过一个数量级
- Meta在过去9个月重构了预训练技术栈,涵盖模型架构、优化算法和数据策展三大改进
- Muse Spark沿预训练、强化学习、测试时推理三个维度系统性地研究Scaling特性
- Meta将Muse Spark定位为"个人超级智能",目标是深度服务个人用户
- 预训练效率的突破表明大模型竞赛正从"堆算力"转向"提效率"
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。