面向Skills编程:领域知识工程驱动Code Agent高效生成代码

阿里妈妈提出面向Skills编程的领域知识工程,让AI高效驾驭复杂业务代码
阿里妈妈技术团队针对Code Agent在企业级复杂代码库中上下文不足、知识断层的痛点,提出了基于领域知识工程的「面向Skills编程」方法论。核心方案包括:Skill三层渐进式披露结构实现按需加载、知识与代码的显式映射提升生成准确率至90%以上、四层防腐体系解决知识腐化问题,以及Domain Scale开发范式形成可复用的团队知识资产。
引言
AI编程工具发展迅猛,Code Agent处理小型项目已经游刃有余,但面对企业级复杂业务架构时却频频碰壁——上下文窗口不够用、改了这里那里就崩。阿里妈妈技术团队针对这一痛点,提出了一种基于领域知识工程的「面向Skills编程」方法论。核心思路很明确:通过结构化的知识管理和渐进式披露机制,让AI在复杂代码库中也能拿到精准的上下文,从而大幅提升代码生成的准确率和效率。
AI编程在复杂业务架构下的真实困境
知识断层才是核心痛点
当代码库膨胀到几十万行,AI面临的最大障碍并非算力不足,而是知识彻底断层:代码的历史逻辑不清晰、文档与实际代码严重脱节、核心开发人员已经离职……每次AI要修改一个需求,都需要人类重新补充大量背景知识,最终AI沦为一个「高级打字员」,完全发挥不了真正的价值。
这里需要理解Code Agent的技术定位与能力边界。Code Agent是指具备自主规划、工具调用和代码生成能力的AI编程智能体,典型代表包括Cursor Agent、Devin、OpenHands等。与传统的代码补全工具(如GitHub Copilot的早期版本)不同,Code Agent能够理解自然语言需求、自主浏览代码库、调用终端命令、执行测试并迭代修复。然而,其能力边界高度依赖于所能获取的上下文质量——在小型项目中,Agent可以通过遍历文件快速建立全局理解;但在数十万行的企业级代码库中,Agent无法在有限的上下文窗口内装下所有相关信息,必须依赖外部知识管理机制来弥补这一缺陷。
代码库的复杂性远超想象
在20多万行的代码中,真正活跃的可能只有2万行,其余大量是历史遗留或已废弃的逻辑。不同业务线之间的耦合关系错综复杂,AI在做需求变更时经常搞不清上下文的依赖关系,「改了这里,那里就出错」,最终只能放弃自动生成,完全依赖人类干预。
领域知识工程:为Code Agent打造一本专家手册
问题的根源在于,无论是开发人员还是AI,面对庞大系统时如果没有集中的、结构化的知识管理方式,就只能各自摸索,极易出现理解偏差或关键信息遗漏。
领域知识工程的核心思路是:将团队中碎片化的、只存在于部分人脑中的领域知识进行集中整理和结构化,构建一本「专属的专家手册」。这本手册既能帮助开发人员快速查找,也能让Code Agent准确读取,从而提升整个开发流程的效率和质量。
Skill三层结构与渐进式披露机制详解
直接喂文档给AI为什么行不通
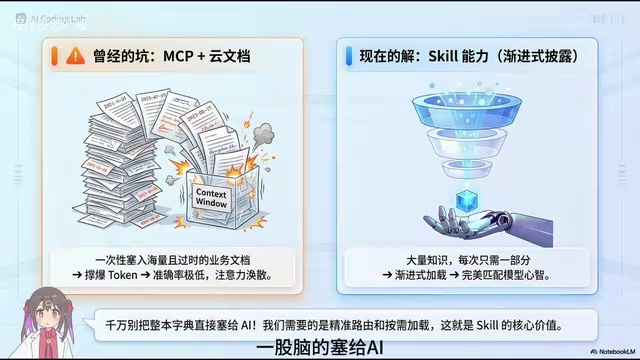
早期的做法是直接把大量甚至已经过时的业务文档一股脑塞给AI,结果不仅token数量直接爆掉,而且AI根本抓不住重点,准确率直线下降,注意力极度涣散。这种「信息轰炸」式的方案在实际工程中几乎不可用。
这背后涉及上下文窗口与注意力机制的工程瓶颈。当前主流大语言模型(如GPT-4、Claude等)的上下文窗口虽然已扩展到128K甚至更长的token,但在实际工程场景中,窗口长度并不等于有效利用率。研究表明,当输入内容超过一定长度后,模型对中间部分信息的关注度会显著下降(即「Lost in the Middle」现象),导致关键信息被忽略。此外,token消耗直接关联API调用成本,在企业级高频调用场景下,无节制地填充上下文窗口会带来巨大的成本压力。这正是Skill三层结构和渐进式披露机制要解决的核心工程问题。
Skill的精准路由与按需加载
Skill的核心理念是:不再给AI一本字典,而是给它一个能精准路由和按需加载的机制。每次AI只需访问当前所需的那部分知识,既节省了token消耗,又让推理过程更加可控和高效。
每个Skill由三层结构组成,采用渐进式披露策略:
- 概要层(约100字):始终可见,包含Skill名称和简短描述,帮助模型快速判断是否需要使用该Skill
- 主体层(约3000字):仅在模型判断需要深入了解时加载,包含业务规则、核心概念、主流程和变更指南
- 细节层:只有在生成代码过程中遇到具体的数据结构或接口定义时才加载,包括接口说明、数据模型定义等
这个设计就像我们查资料一样:先看目录,再看摘要,遇到细节问题再翻附录。这种渐进式披露机制让Code Agent在每个阶段都只处理恰到好处的信息量。
基于领域知识的AI推理路径设计
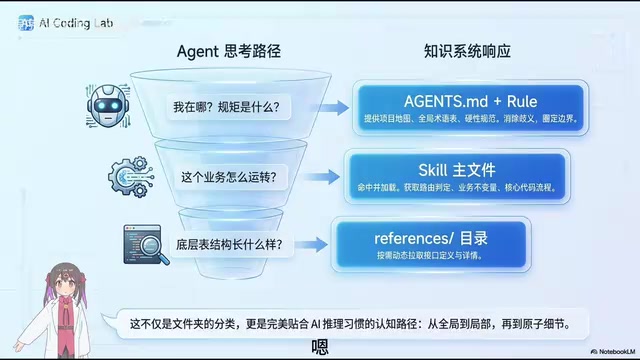
整个知识系统被分为三个层次,引导Code Agent按照从宏观到微观的步骤思考和生成代码:
第一层:全局项目地图
包括项目的AGENTS.md和规则文件(Rules),将整个项目的结构、术语表以及硬性规范先告诉AI,让它知道「我现在在哪」以及「这一片的规矩是什么」。
值得一提的是,AGENTS.md是一种新兴的项目级AI配置文件规范,最早由Google在其内部工程实践中推广,随后被Cursor的.cursorrules、Windsurf的.windsurfrules等工具采纳为类似概念。它的作用是在代码仓库根目录放置一个结构化的说明文件,告诉Code Agent该项目的技术栈、目录结构、编码规范、测试要求等关键信息。这相当于给AI一份「项目入职手册」,让它在开始工作前就建立起对项目的基本认知框架,而不是盲目地从零开始探索。
第二层:Skill主文件
当AI遇到具体任务时,加载相应Skill的主文件,其中包含该业务的核心逻辑和关键代码流程。
第三层:References细节
遇到更细致的内容(如接口定义),AI才会进入references目录拉取具体细节。
这种从全局到局部再到原子细节的推理路径,非常符合大语言模型的思维习惯,避免了一次性加载过多信息导致的注意力分散问题。
知识与代码流程的显式映射
传统方式只告诉AI有什么规则,AI需要自己去猜测规则与代码的对应关系,极易出错。面向Skills编程的方案中,每一条规则都标明了它所在的流程、节点以及入口位置,相当于直接给AI画了一张导航图。通过这种显式映射,代码生成的准确率可以提升到90%以上。
知识防腐:贯穿开发周期的四层防护体系
过时知识比没有知识更危险
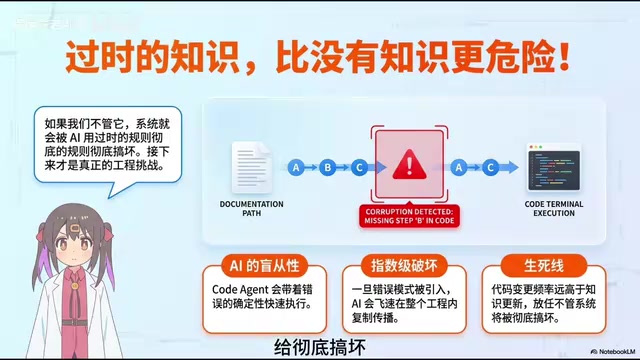
Code Agent在生成代码时会盲目相信规则,一旦使用了过时或错误的信息,就会快速在整个工程中复制这个错误。而代码的变更速度远快于知识的更新,如果不及时处理,整个系统很快就会被错误规则搞坏。
知识腐化(Knowledge Rot)其实是软件工程领域的一个经典难题,指的是文档、注释、Wiki等知识载体与实际代码逐渐脱节的现象。据Stack Overflow的开发者调查,超过60%的开发者认为内部文档「经常或总是过时」。在传统开发模式下,知识腐化的后果主要是增加新人上手成本和沟通成本;但在AI编程时代,这个问题被急剧放大——Code Agent会将过时的规则视为「真理」并严格执行,错误会以代码生成的速度在整个工程中快速扩散,其破坏力远超人类手动编码时的影响范围。
四层防护确保知识持续准确
团队搭建了一个贯穿整个开发周期的四层防护体系:
- 反向校验:AI在读取知识或代码时,如果发现两边不一致,会自动生成修正建议
- 沟通补充:AI遇到不理解的地方,会主动与开发者探讨,将讨论结果总结后直接更新到知识库
- Commit校验:每次代码提交都强制检查,有代码变动就必须同步更新知识,防止新的腐化进入
- 全量巡检:每次发布后对整个代码库和知识库进行全局比对,确保没有遗漏
通过这套机制,文档更新变成了开发过程中自然而然的事情,不再需要专门派人手动维护。
Domain Scale vs SDD:AI编程开发范式的根本转变
传统的SDD(规范驱动开发)比较适合全新项目,但在日常小迭代中,写Spec的成本远高于直接写代码,而且这些Spec基本是一次性的,很难积累出有价值的东西。
关于SDD的背景,有必要做进一步说明。SDD(Spec-Driven Development,规范驱动开发)是近年来随着AI编程工具兴起而流行的一种开发范式,其核心思想是在编写代码之前,先用自然语言撰写详细的技术规范文档(Spec),然后让AI根据Spec生成代码。这种方法在全新项目或大型功能模块的初始开发中效果显著,因为Spec可以为AI提供清晰的需求边界和技术约束。然而,在日常迭代中,一个小需求可能只涉及几行代码的修改,却需要花费数倍时间编写和维护Spec,投入产出比严重失衡。更关键的是,这些Spec通常是面向单次任务的,任务完成后就失去了价值,无法沉淀为可复用的团队知识资产。
Domain Scale(领域知识驱动开发)则强调维护一套不断成长的核心领域业务知识。这个知识库随项目推进越来越丰富,是真正的团队资产。每次写的新代码都是知识的一种物理实现,能够不断积累产生复利效应,而不是每次都在造「用完就扔的一次性餐具」。
未来竞争力:领域知识才是AI编程时代的护城河
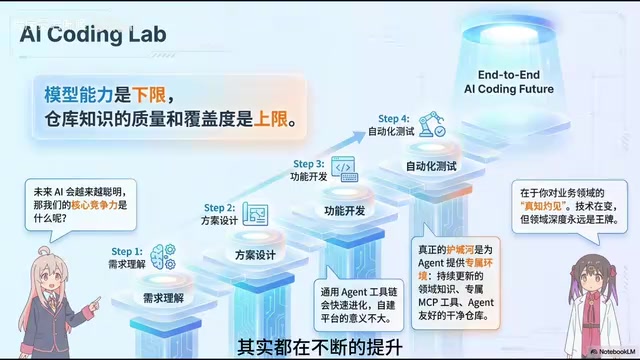
随着大模型能力的不断提升,通用AI编程工具链会进化得非常快。未来决定团队能否脱颖而出的关键因素不再是谁的工具更好,而是:
- 是否拥有持续更新的领域知识体系
- 是否有专门为Code Agent打造的MCP工具
- 是否有一个干净且结构良好的专属代码仓库
这里提到的MCP(Model Context Protocol,模型上下文协议)是由Anthropic提出的一种开放标准协议,旨在为大语言模型提供统一的外部工具和数据源接入方式。通过MCP,Code Agent可以像调用API一样访问数据库、搜索引擎、内部知识库等外部资源,而不需要将所有信息都塞进上下文窗口。在领域知识工程的语境下,专属MCP工具意味着团队可以将自己的Skill知识库、代码索引、业务规则引擎等封装为MCP服务,让任何兼容MCP协议的AI工具都能无缝接入,从而实现知识的标准化分发和复用。
团队不必纠结于自研底层AI工具链,而应该把精力放在让领域知识形成壁垒,选择最适合业务闭环的场景进行深度定制和优化。
落地实践建议
- 先评估业务适配性:确认业务是否是闭环的,领域知识是否可以被完整列举
- 小范围试点:先找变更最频繁或痛点最明显的模块做起来,快速看到效果且风险可控
- 防护机制先行:一定要先把Commit校验这道关设好,流程保障优先于文档完善,否则容易积累技术债务,越做越乱
总结
面向Skills编程的领域知识工程,本质上是在AI与复杂业务代码之间搭建了一座结构化的桥梁。通过渐进式披露的Skill三层设计、从宏观到微观的推理路径、知识与代码的显式映射,以及四层知识防腐体系,让Code Agent真正具备了理解和驾驭复杂业务的能力。在AI编程工具日趋同质化的今天,深耕领域知识工程,才是团队构建长期技术护城河的关键所在。
核心要点
- Skill采用渐进式披露机制(概要→主体→细节三层结构),实现精准路由和按需加载,大幅节省token消耗并提升AI推理精准度
- 通过知识与代码流程的显式映射,为每条规则标明所在流程、节点和入口位置,将代码生成准确率提升至90%以上
- 构建反向校验、沟通补充、Commit校验、全量巡检四层防护体系,解决知识腐化问题,让文档更新成为开发过程中的自然环节
- Domain Scale(领域知识驱动开发)相比SDD(规范驱动开发),强调维护不断成长的知识库,形成可复用的团队资产和复利效应
- 未来AI编程的核心竞争力不在于底层工具链,而在于持续更新的领域知识、专属MCP工具和结构良好的代码仓库
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。