NotebookLM恢复服务:Google AI研究助手重新上线

NotebookLM服务恢复,用户学习研究回归正轨
Google旗下的AI学习与研究工具NotebookLM近日宣布服务已全面恢复,用户可以继续正常使用其学习、研究和知识整理功能。
短暂中断后NotebookLM重新上线
NotebookLM团队通过社交媒体发布了简短的恢复公告,表示平台已重新上线运行,用户可以回到日常的学习、研究工作流程中。团队同时对用户在服务中断期间的耐心和理解表示了感谢。
虽然官方并未详细说明此次服务中断的具体原因和持续时间,但从公告的语气来看,这次中断对部分依赖该工具进行日常学习和研究的用户产生了一定影响。云端AI服务的稳定性问题并非NotebookLM独有——随着大语言模型推理对GPU算力的巨大需求,AI服务面临的基础设施压力远超传统云服务。单次推理请求可能需要数十亿次浮点运算,而像Gemini这样的大模型在处理长文档理解任务时,需要在数千块GPU组成的集群上并行计算,任何硬件故障或网络抖动都可能引发连锁反应。服务器负载管理、模型版本更新部署、以及底层云基础设施(如Google Cloud Platform)的维护都可能导致短暂中断。此外,AI服务还面临"推理成本"与"服务可用性"之间的平衡难题:为了控制成本,服务商通常会对并发请求进行限流,当用户量激增时容易触发过载保护机制。OpenAI的ChatGPT、Anthropic的Claude等主流AI服务也曾多次经历类似的服务波动,这反映了当前AI基础设施仍处于快速扩展期的现实。
值得注意的是,AI推理服务与传统Web服务在架构上存在根本差异。传统Web应用主要是CPU密集型或I/O密集型任务,可以通过成熟的水平扩展(Horizontal Scaling)策略轻松应对流量波动——只需增加更多廉价的通用服务器即可。而AI推理服务高度依赖专用硬件加速器(如NVIDIA的H100/H200 GPU或Google自研的TPU v5),这些硬件不仅价格昂贵(单块H100售价约3-4万美元),而且全球供应紧张,扩容周期以月甚至季度计算。这意味着当用户需求突然激增时,AI服务商无法像传统云服务那样在几分钟内弹性扩展算力,这种"算力刚性"是AI服务频繁出现降级或中断的深层原因。Google为NotebookLM提供支撑的TPU(Tensor Processing Unit)是其自主设计的AI专用芯片,虽然在自有数据中心中部署规模庞大,但在模型升级换代或数据中心维护期间,仍可能出现算力供给的暂时性缺口。
NotebookLM核心功能与技术架构
NotebookLM作为Google推出的AI驱动研究助手,基于Google的Gemini大语言模型构建,采用了检索增强生成(Retrieval-Augmented Generation,简称RAG)技术架构。RAG是当前企业级AI应用中最主流的架构模式之一,由Meta AI研究团队于2020年在论文《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中首次系统性提出。该论文的核心洞察是:与其试图将所有知识压缩进模型参数中(这会导致知识过时和幻觉问题),不如让模型在生成回答时动态检索外部知识源。与通用聊天机器人直接依赖模型参数中存储的知识不同,RAG架构的核心优势在于AI的回答严格基于用户上传的源文档,而非模型的预训练知识,这大幅降低了AI"幻觉"(即生成看似合理但实际错误的内容)的风险。研究表明,纯粹依赖参数记忆的大语言模型在事实性问答任务中的幻觉率可高达15-25%,而良好实现的RAG系统可将这一比率降低至3-5%以下。
具体而言,RAG的工作流程分为三个阶段:首先是索引阶段,用户上传的文档被分割成语义完整的文本块(通常每块包含200-500个token,并保留一定的重叠区域以维持上下文连贯性),然后通过嵌入模型(Embedding Model)将每个文本块转化为高维向量表示(通常是768维或1536维的浮点数数组),存储在向量数据库中。嵌入模型的核心能力是将语义相近的文本映射到向量空间中相邻的位置——例如"心脏病"和"冠状动脉疾病"虽然字面不同,但在向量空间中距离很近。Google可能使用其自研的Gecko或更大规模的嵌入模型来完成这一步骤;其次是检索阶段,当用户提出问题时,问题同样被转化为向量,系统通过余弦相似度(Cosine Similarity)等算法在向量数据库中找到语义最相关的文档片段。余弦相似度衡量的是两个向量方向的一致程度,值域为-1到1,越接近1表示语义越相关。现代向量数据库(如Google的ScaNN、开源的Pinecone、Weaviate等)使用近似最近邻(ANN)算法,能在毫秒级时间内从数百万个向量中找到最相关的结果;最后是生成阶段,检索到的相关片段作为上下文(Context)与用户问题一起输入大语言模型,模型基于这些片段生成回答,并提供引用来源。这种"先检索、后生成"的模式确保了回答的可溯源性和准确性。
NotebookLM的核心功能包括:
- 文档理解与总结:上传PDF、网页、视频、音频等多种格式的资料,AI自动提取关键信息并生成结构化摘要。得益于Gemini模型超长的上下文窗口(Gemini 1.5 Pro支持处理高达100万token的输入,相当于约700页的学术论文或数十小时的音频转录文本),NotebookLM能够处理篇幅极长的学术论文和书籍。上下文窗口(Context Window)是指模型单次处理时能"看到"的最大文本长度,这一指标直接决定了AI工具处理长文档的能力上限。相比之下,早期的GPT-3.5仅支持4096个token的上下文窗口,处理一篇超过10页的论文就需要分段处理
- 智能问答:基于用户上传的资料进行精准的问答交互,每个回答都附带源文档引用,用户可以一键跳转到原文验证。这种"可溯源"的设计哲学在学术研究中尤为重要,因为研究者需要验证每个论点的出处,而非盲目信任AI的输出
- 音频概述生成:将复杂文档转化为播客风格的音频摘要,这是NotebookLM最具辨识度的创新功能
- 笔记整理:帮助用户系统化地组织研究素材,支持将AI生成的回答保存为笔记,并在笔记之间建立关联。这种设计借鉴了卡片笔记法(Zettelkasten Method)的理念——由德国社会学家尼克拉斯·卢曼(Niklas Luhmann)发明的知识管理系统,强调通过笔记之间的链接而非层级分类来组织知识
其中,音频概述(Audio Overview)功能是NotebookLM最具差异化的特色之一。该功能利用Google DeepMind开发的先进文本转语音(TTS)技术和对话脚本生成能力,将用户上传的复杂学术论文或长篇文档转化为两位AI主持人自然对话讨论的播客形式。从技术实现角度看,这一功能涉及多个AI子系统的协同工作:首先,大语言模型需要理解源文档的核心内容并生成一个结构化的对话脚本,包括确定讨论的重点、设计提问和回应的节奏、插入适当的类比和例子;然后,TTS系统需要将这些脚本转化为自然流畅的语音,包括适当的语调变化、停顿、语气词甚至笑声。Google DeepMind的TTS技术(可能基于其SoundStorm或类似架构)已经能够生成几乎无法与真人区分的语音质量。生成的对话不是简单的文本朗读,而是包含提问、回应、举例说明甚至适度幽默的真实对话风格。
这种方式借鉴了认知科学中的"精细化加工"(Elaborative Processing)理论——该理论由心理学家Fergus Craik和Robert Lockhart在1972年提出的"加工深度"(Levels of Processing)框架中首次系统阐述。核心观点是:信息被加工的深度越深、与已有知识的连接越丰富,长期记忆的效果就越好。简单的重复阅读属于"浅层加工",而通过讨论、质疑、类比等方式处理信息则属于"深层加工"。当学习者通过多种方式(如听觉、讨论、类比)接触同一材料时,大脑会建立更丰富的神经连接,从而加深理解和长期记忆。此外,这种对话形式还利用了"测试效应"(Testing Effect)——听到一位主持人提出问题时,听众会不自觉地在脑中尝试回答,这种主动检索的过程比被动阅读更能巩固记忆。通过听取两位"主持人"从不同角度讨论和解读材料,用户能够在通勤、运动等碎片化时间中被动吸收知识,实现学习场景的延伸。该功能自2024年9月推出后迅速走红社交媒体,成为NotebookLM的标志性卖点,也推动了"AI播客"这一新兴内容形态的流行。据报道,该功能推出后的几周内,社交媒体上出现了大量用户分享自己用NotebookLM生成的播客片段,话题标签#NotebookLM一度登上Twitter/X的热门趋势。
这些功能使其成为学生、研究人员和知识工作者的重要生产力工具。据Google官方数据,NotebookLM自公开发布以来用户增长迅速,尤其在学术研究、法律文献分析和商业报告整理等场景中获得了广泛应用。在学术领域,研究者使用NotebookLM来快速消化大量文献综述、识别研究空白和交叉引用关系;在法律领域,律师利用其处理冗长的判例法文档和合同条款;在商业领域,分析师用它来整合多份行业报告并提取关键趋势。Google还推出了面向企业的NotebookLM Business版本,提供更强的数据隐私保护和团队协作功能。
依赖AI工具的用户该如何应对服务中断
此次短暂中断也提醒我们,在日益依赖AI工具辅助工作和学习的今天,建立多元化的工具链和本地备份习惯仍然十分重要。当单一云端服务出现中断时,用户不应完全陷入被动等待的状态。这一问题在AI工具领域尤为突出,因为与传统SaaS工具不同,AI服务的中断往往意味着用户不仅失去了存储的数据访问权,还失去了"智能处理能力"——这种能力目前很难通过本地设备完全替代。虽然开源社区已经推出了可在消费级硬件上运行的小型语言模型(如Meta的Llama系列、Mistral等),但这些本地模型在处理长文档理解、多文档交叉分析等复杂任务时,性能仍与云端大模型存在显著差距。这种"智能能力的云端锁定"是AI时代用户面临的新型依赖风险,与传统软件时代的"数据锁定"(Vendor Lock-in)问题有本质区别。
对于重度依赖NotebookLM的用户而言,建议采取以下策略:首先,定期导出重要笔记和研究成果,确保在任何情况下都能保持工作连续性。NotebookLM支持将笔记导出为Google Docs格式,用户应养成每周或每个研究阶段结束后导出关键成果的习惯。其次,可以考虑搭配本地知识管理工具作为补充方案。例如,Obsidian是一款基于本地Markdown文件的知识管理工具,所有数据以纯文本形式存储在用户自己的设备上,即使完全断网也能正常使用。Obsidian的核心设计哲学是"面向未来的笔记"——因为Markdown是一种开放的纯文本格式,即使Obsidian这款软件本身停止维护,用户的笔记仍然可以被任何文本编辑器打开和阅读。其双向链接(Bidirectional Links)功能允许用户在笔记之间建立网状关联,而图谱视图(Graph View)则将这些关联可视化为知识网络图,帮助用户发现不同概念之间的隐藏联系。Notion则提供了更强的协作能力和数据库功能,其关系型数据库(Relational Database)特性特别适合管理文献库、研究项目进度和团队任务分配,适合团队研究项目。此外,Zotero作为开源的学术文献管理工具,可以与NotebookLM形成互补——用Zotero管理PDF文献库和引用格式,用NotebookLM进行深度内容理解和知识提取。
将AI生成的洞察及时沉淀到这些个人知识库中,不仅能避免因单一平台的不可用而中断整个研究工作流,还能帮助用户真正内化AI辅助产生的知识,而非仅仅依赖AI的实时生成能力。这一点涉及到学习科学中的一个重要概念——"生成效应"(Generation Effect),即人们对自己主动加工和重新表述过的信息记忆更深刻。如果用户只是被动地阅读AI生成的摘要而不进行任何个人化的整理和反思,这些知识很可能只会停留在短期记忆中。因此,最佳实践是将NotebookLM作为"理解加速器",但仍然通过手动整理、重新组织和与已有知识建立连接来完成真正的学习过程。
此外,用户还可以关注NotebookLM的状态页面和官方社交媒体账号,以便在服务中断时第一时间获取信息,合理安排工作节奏。Google Workspace的服务状态仪表板(Google Workspace Status Dashboard)通常会实时更新各项服务的运行状态,用户可以将其加入书签以便快速查看。
核心要点
- NotebookLM服务已全面恢复,用户可正常使用学习研究功能
- 云端AI服务因GPU/TPU算力需求巨大且硬件扩容周期长,面临的基础设施稳定性挑战远超传统云服务
- NotebookLM基于RAG架构构建,通过"先检索源文档、后生成回答"的三阶段流程(索引→检索→生成)确保回答准确性,将幻觉率从15-25%降低至5%以下
- 音频概述功能借鉴认知科学中的加工深度理论和测试效应,通过AI播客形式帮助用户在碎片化时间中实现深层学习
- 用户应建立多元化工具链,搭配Obsidian、Notion、Zotero等本地或互补工具,避免对单一云端AI服务的过度依赖,同时通过主动整理实现知识的真正内化
相关推荐
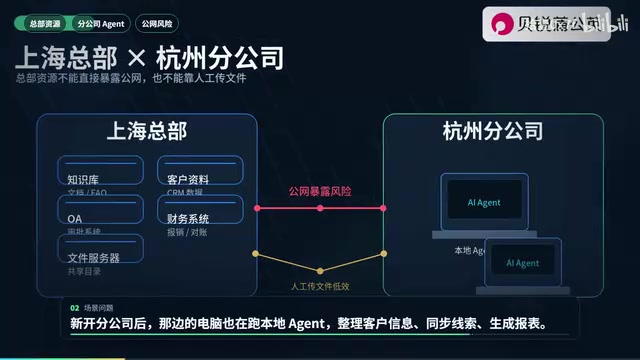
企业AI Agent异地互联:智能组网方案全解析
企业多地部署AI Agent面临网络互通难题。本文解析如何通过智能组网方案,低成本实现异地Agent统一接入总部知识库、OA系统等内部资源,保障Agent稳定高效运行。
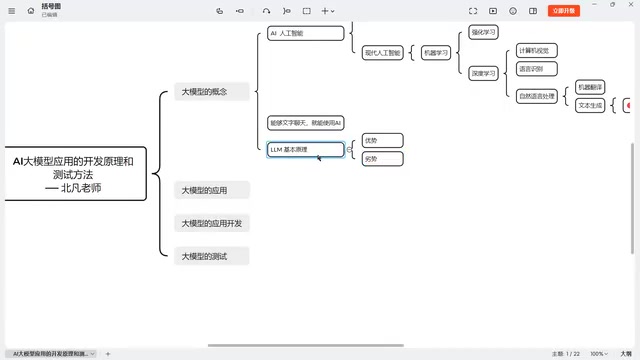
AI大模型原理详解:Transformer架构与测试实战指南
深入解析AI大模型核心原理,从Transformer架构到概率推算本质,详解大语言模型在测试领域的应用场景、AI应用测试挑战及应对策略,帮助测试人员快速掌握AI工具与AI测试方法论。

Codex超级Agent完全指南:从安装到多任务并行实战
全面拆解OpenAI Codex桌面端应用的安装配置、Plugin外挂、Skill技能系统、Agent.md设置及多任务并行实战,帮助零编程基础用户快速上手这款超级AI Agent工具。