NVIDIA合成3D医学影像:如何用AI生成数据破解训练瓶颈

NVIDIA用合成3D医学影像解决AI训练数据稀缺难题
医学影像AI发展受限于数据稀缺、隐私法规和标注成本三大瓶颈。NVIDIA提出通过扩散模型大规模合成逼真的3D医学影像,在解剖一致性、多模态支持和可控生成方面实现技术突破,采用"合成预训练+真实微调"的范式,以极低的真实数据成本实现高性能临床AI模型训练。
医学影像AI的数据瓶颈:为什么真实数据远远不够
高质量的3D医学影像数据是现代放射学AI的基石,但获取这些数据却面临重重障碍。数据稀缺、隐私法规限制、标注成本高昂——这三座大山长期制约着医学影像AI模型的发展。NVIDIA最新发布的技术方案,通过大规模合成逼真的3D医学影像,为预训练模型的交付开辟了一条全新路径。
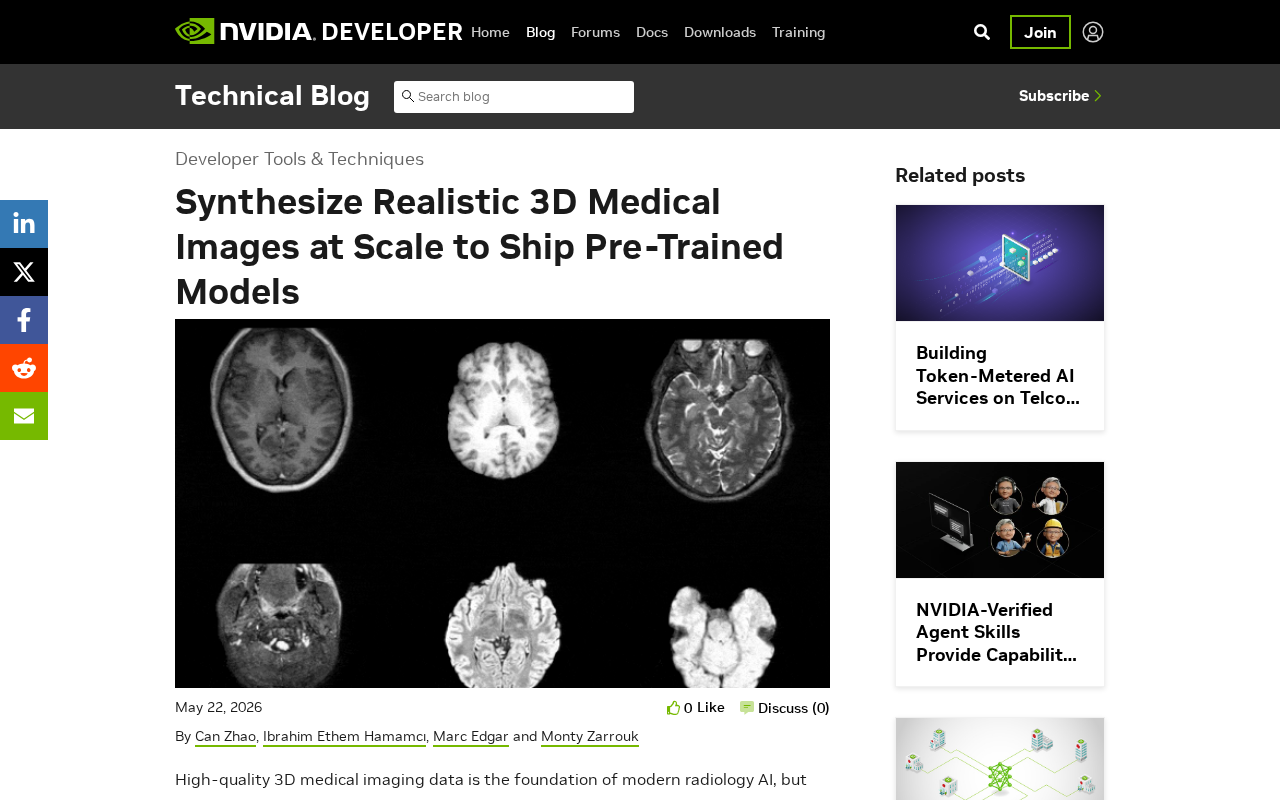
这一方案的核心思路直截了当:既然真实数据难以获取,那就用AI生成足够逼真的合成数据来替代。不过,要让合成数据真正可用于临床级AI模型的训练,技术挑战远比想象中复杂。
医学影像数据为何如此稀缺
隐私与合规的硬约束
医学影像数据天然携带患者隐私信息,受到HIPAA、GDPR等严格法规的约束。**HIPAA(健康保险可携性和责任法案)**是美国1996年颁布的联邦法律,规定了受保护健康信息(PHI)的使用和披露标准,违规罚款最高可达每年190万美元。**GDPR(通用数据保护条例)**则是欧盟2018年生效的数据保护法规,将健康数据列为"特殊类别数据",处理须满足更严格的合法性基础,违规罚款可达全球年营业额的4%。
值得注意的是,即便对影像数据进行去标识化处理(如移除DICOM头文件中的患者姓名、出生日期等元数据),研究表明仍可通过面部重建、骨骼特征等手段实现重识别,这使得监管机构和医疗机构对数据共享始终保持高度警惕。跨机构、跨国的数据协作更是举步维艰。
3D影像标注的高成本与专业门槛
3D医学影像(如CT、MRI)的标注需要经验丰富的放射科医生逐层标记,一个高质量的3D分割标注往往需要数小时。理解这一挑战需要了解医学影像的数据结构:医学影像普遍采用**DICOM(医学数字成像和通信)**国际标准存储,一个完整的3D CT扫描通常包含数百至数千张2D切片,每张切片的像素值代表对应体素的X射线衰减系数(以Hounsfield单位HU表示);MRI则通过T1、T2、FLAIR等不同脉冲序列反映组织的不同物理特性,同一解剖部位在不同序列下呈现截然不同的对比度。放射科医生需要在三维空间中理解这些复杂的解剖关系,才能完成准确标注。这使得大规模标注数据集的构建成本居高不下,严重限制了模型训练的数据规模。
罕见病例的长尾分布问题
罕见疾病的影像样本天然稀少,但恰恰是这些长尾病例对AI模型的泛化能力至关重要。真实数据集中常见病例占绝对多数,罕见病例的不足直接影响模型在临床场景中的可靠性。统计学上,这种数据分布的极度不均衡会导致模型在训练时过度拟合常见病例的特征,在面对罕见但临床上同样重要的病例时出现显著的性能下降。
NVIDIA大规模合成3D医学影像的技术路径
从GAN到扩散模型:生成技术的快速迭代
从早期的GAN到扩散模型,3D医学影像合成技术经历了快速迭代。**扩散模型(Diffusion Model)**是近年来生成式AI领域最重要的突破之一,其核心原理是通过逐步向数据添加噪声(前向过程),再训练神经网络学习逆向去噪过程,从而实现高质量内容生成。相比早期的GAN(生成对抗网络),扩散模型训练更稳定、生成多样性更强,且不易出现模式崩溃问题。
在医学影像领域,扩散模型面临独特挑战:3D CT/MRI数据的体素分辨率远高于自然图像,内存和计算需求呈立方级增长;同时,解剖结构的空间连贯性要求模型在三维空间中保持全局一致性,而非逐切片独立生成。NVIDIA的方案通过**潜空间压缩(Latent Diffusion)**和3D注意力机制等技术,有效应对了这些挑战,能够合成在解剖结构、组织对比度、病理表现等方面高度逼真的3D医学影像。
关键技术突破体现在三个层面:
- 解剖一致性:合成影像在三维空间中保持解剖结构的连贯性,而非简单的2D切片堆叠
- 多模态支持:能够生成CT、MRI等不同模态的影像,并保持跨模态的解剖对应关系——这对于需要融合多模态信息的下游任务(如肿瘤分割)至关重要
- 可控生成:支持条件生成,可以指定特定的病理类型、严重程度、解剖变异等参数
合成预训练 + 真实微调:完整工作流
合成数据的最终目标是服务于模型训练。这里的核心范式——预训练+微调(Pre-training + Fine-tuning)——源自NLP领域BERT、GPT等大语言模型的成功实践:在大规模通用数据上预训练获得强大的特征表示能力,再用少量任务特定数据进行微调,以极低的数据成本实现高性能的下游任务适配。研究表明,即便合成数据与真实数据存在一定的分布差距,只要预训练模型学到了足够通用的解剖特征表示,少量真实数据的微调便足以弥合这一差距,这一现象被称为**"领域适应"(Domain Adaptation)**。
NVIDIA的方案将合成数据生成与预训练模型交付整合为一个完整的工作流:
- 大规模生成:利用GPU集群批量生成多样化的3D医学影像及其对应标注
- 质量筛选:通过自动化质量评估管道,过滤掉不合格的合成样本
- 预训练:使用合成数据训练基础模型,建立强大的特征表示能力
- 微调适配:用少量真实数据对预训练模型进行微调,适配具体临床任务
这种"合成预训练 + 真实微调
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。