OpenAI Codex实战:上下文引用、推理等级与TODO转任务详解
引言
OpenAI Codex 扩展不仅仅是一个代码生成工具,它在开发者工作流中的深度集成能力才是真正的亮点。本文基于 Codex 官方教程系列第8期的内容,详细解析三个核心功能:为提示词添加上下文、调节AI推理等级以及将代码中的TODO注释自动转化为Codex任务。这些功能组合使用,能够显著提升AI辅助编程的效率和准确性。
为提示词添加上下文
使用 @ 符号引用文件
与 Codex CLI 的用法类似,在 Codex 扩展的聊天窗口中,我们可以通过 @ 符号来引用项目中的文件,将其作为提示词的上下文。输入 @ 后开始键入文件名,Codex 会自动搜索项目中的匹配文件。说个细节,你不需要输入完整的文件路径,只需输入文件名的一部分即可。例如输入 page,Codex 就会列出所有包含该关键词的文件供你选择。
在大语言模型(LLM)驱动的编程工具中,"上下文窗口"是一个核心概念。LLM 在生成代码时,只能基于当前输入的提示词和附带的上下文信息进行推理,它并不会自动"看到"你整个项目的所有文件。当前主流 LLM 的上下文窗口从 128K 到 200K token 不等(GPT-4o 支持 128K,Claude 3.5 支持 200K),每个被引用的文件都会占用宝贵的上下文空间。因此,如何精准地向模型提供相关上下文,直接决定了生成结果的质量——开发者需要有策略地选择引用哪些文件,而非盲目添加所有相关文件。@ 符号引用本质上是一种上下文注入机制——它将指定文件的内容序列化后拼接到提示词中,让模型在生成代码时能够参考该文件的结构、类型定义和业务逻辑。这种模式在 VS Code 生态中已经成为主流交互范式,GitHub Copilot Chat、Cursor 等工具都采用了类似的设计。
除了 @ 符号,还可以点击聊天窗口底部的加号图标来搜索和添加文件上下文,效果完全一致。
图片也能作为上下文
一个非常实用的功能是支持图片上下文。点击底部的「添加图片」按钮可以从本地选择图片,也可以直接将图片复制粘贴到聊天窗口中。
这一能力依赖于底层模型的**多模态(Multimodal)**处理能力。GPT-4o 等多模态模型能够同时处理文本和图像输入,其视觉能力基于 CLIP 等视觉编码器架构,将图像分割为固定大小的 patch 后转换为 embedding 向量,再与文本提示词联合推理。需要注意的是,模型对 UI 截图的理解并非像素级精确复制,而是语义级别的理解——它能识别按钮的形状、阴影方向、渐变趋势等设计意图,但可能在精确色值、像素间距等细节上存在偏差。在前端开发场景中,这一能力尤为实用:设计师提供的 UI 稿、竞品截图、甚至手绘草图都可以直接作为输入,模型会尝试从视觉信息中提取布局结构、颜色方案、组件样式等要素,并将其转化为对应的代码实现。这种"所见即所得"的交互方式大幅缩短了从设计到代码的转化路径。
教程中演示了一个典型场景:作者从 Google 搜索到一个 3D 按钮的截图,将其复制粘贴到聊天中,然后输入提示词:
Can you update @button.tsx to have a 3D bevel effect like in this image
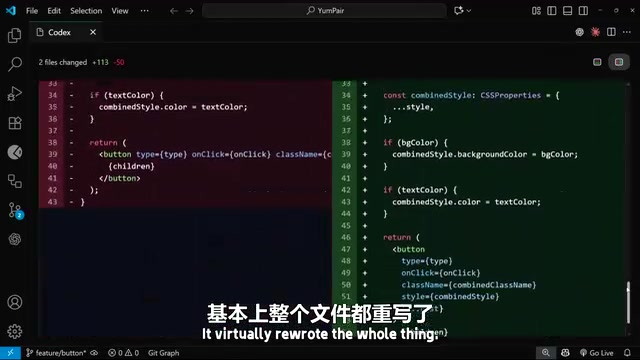
这条提示词同时使用了两种上下文——通过 @ 引用了 button.tsx 组件文件,并附上了目标效果的截图。Codex 处理完成后,不仅修改了 button.tsx 文件(几乎重写了整个组件),还添加了大量 CSS 代码,包括一个新的 button-bevel 类。
查看变更差异
任务完成后,可以点击变更文件查看 diff 差异对比,清晰地看到 Codex 添加、修改和删除了哪些代码。
diff(差异对比)是软件工程中最基础也最重要的代码审查工具之一,源自 Unix 系统的 diff 命令。它以逐行对比的方式展示两个版本之间的差异:绿色标记新增内容,红色标记删除内容,黄色或灰色标记修改内容。在 AI 辅助编程场景下,diff 视图的重要性被进一步放大——因为 AI 可能在一次操作中修改大量文件和代码行,开发者必须通过 diff 视图逐一审查这些变更,确保 AI 没有引入不必要的修改、删除关键逻辑或破坏已有功能。这也是为什么 Codex 扩展将 diff 查看作为核心交互流程的一部分。
在浏览器中预览后,按钮确实呈现出了 3D 效果,虽然颜色可能不完全符合预期(比如底部是灰色而非深绿色),但整体思路是正确的。这时只需再次提示 Codex 进行微调即可。
AI推理等级:速度与质量的平衡
三档推理等级详解
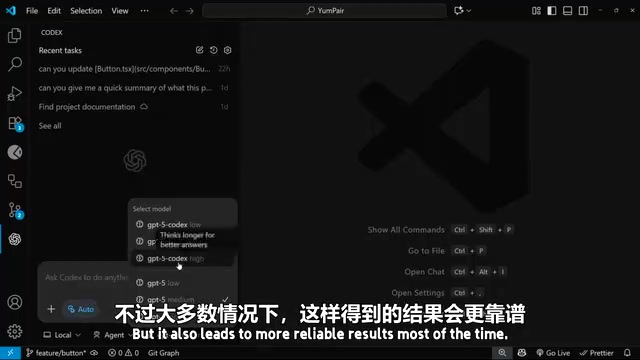
Codex 提供了多个推理等级(reasoning effort levels),可以在聊天窗口底部的菜单中找到。默认设置为 Medium(中等),但你可以根据任务复杂度灵活调整:
| 等级 | 特点 | 适用场景 |
|---|---|---|
| Minimal / Low | 速度快,思考和规划时间短 | 简单的代码编辑、重构 |
| Medium | 速度与质量的平衡点 | 中等规模的功能开发 |
| High | 更多规划和思考,耗时更长 | 复杂任务,需要考虑边界情况 |
推理等级背后的技术原理
推理等级的概念与 OpenAI 的 o 系列推理模型密切相关。o1、o3 等模型采用了**"链式思维"(Chain-of-Thought, CoT)**推理机制,在生成最终答案之前会进行内部的逐步推理过程。推理等级本质上控制的是模型在这个内部思考阶段投入的计算量:低等级意味着模型快速给出直觉性答案,高等级则允许模型进行更长的推理链,反复验证和修正自己的思路。这与人类解题的过程类似——简单问题可以直接作答,复杂问题则需要在草稿纸上反复推演。
从 API 层面看,更高的推理等级会消耗更多的**"推理 token"(reasoning tokens)**,这些 token 虽然不直接展示给用户,但会计入费用和延迟。在 OpenAI 的定价体系中,推理 token 的价格通常与输出 token 相同,但由于高推理等级可能产生数千甚至数万个推理 token,不同等级之间的成本差异可能达到数倍。对于团队级使用场景,合理设置默认推理等级可以在保证代码质量的同时显著控制 API 支出——这是一个需要在工程实践中不断校准的平衡点。
如何选择合适的推理等级
核心原则是任务复杂度决定推理等级:
- 低推理等级的优势是响应速度快,但可能遗漏边界情况,结果可靠性较低
- 高推理等级会进行更充分的规划和思考,结果更可靠,但消耗的 token 也更多
- 对于简单任务,切勿选择高推理等级,这是不必要的资源浪费
教程作者建议将 Medium 作为日常默认选项,这在大多数任务中都能提供不错的平衡。只有在面对真正复杂的、需要大量逻辑推理的任务时,才值得将推理等级调到 High。
TODO注释自动转任务
从注释到实现的一键操作
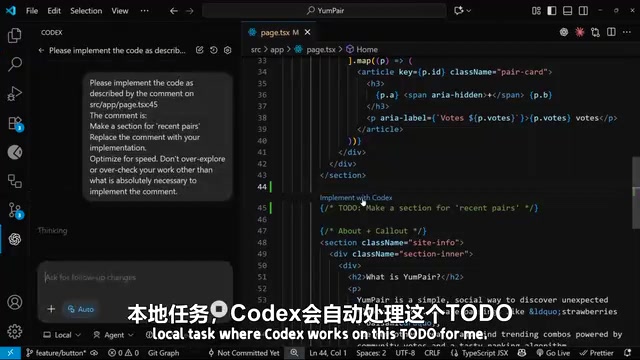
这是 Codex 扩展中一个非常贴心的功能。在实际开发中,我们经常会在代码中留下 // TODO 注释,标记需要后续完成的功能。安装 Codex 扩展后,每个 TODO 注释上方都会出现一个 "Implement with Codex" 的选项。
TODO 注释是软件开发中一种广泛使用的代码标记约定,属于**"技术债务"管理的一部分。除了 TODO 之外,常见的标记还包括 FIXME(需要修复的已知问题)、HACK(临时性的权宜之计)、XXX(需要特别注意的危险代码)等。在大型项目中,TODO 注释往往会随着时间积累而大量堆积,成为"被遗忘的承诺"。在企业级项目中,TODO 的管理已经形成了完整的工具链生态:todo-tree 等 VS Code 插件可以将分散在代码各处的 TODO 聚合为树状视图,SonarQube 等代码质量平台会将 TODO 数量纳入技术债务评估,CI/CD 流水线也可以统计 TODO 数量作为代码健康度指标。Codex 将 TODO 注释与 AI 实现能力直接打通,实际上提供了一种系统性消化技术债务的新途径**——开发者可以批量处理积压的 TODO 项,而不必逐一手动实现。
教程中的示例是在首页组件中有一条注释:
// TODO: add a recent pair section here
点击 "Implement with Codex" 后,扩展会自动启动一个新的聊天会话,生成包含该 TODO 内容的提示词,并指示 Codex 用实际实现替换这条注释。
实际效果展示
在演示中,Codex 自动完成了以下工作:
- 创建了「Recent Pairs」数据对象数组
- 编写了遍历数据并渲染模板的逻辑
- 生成了与已有「Popular Pairs」风格一致但背景不同的新区块
最终在浏览器中呈现的效果令人满意——新的「Recent Pairs」区块与已有的「Popular Pairs」区块风格统一,只是背景色有所区别。
这个功能的价值在于:开发者可以在编码过程中随手留下 TODO 标记,不必立即处理,等到合适的时机再让 Codex 逐一实现。这种工作模式非常符合实际开发节奏。
版本控制:AI编程时代的安全网
教程作者反复强调了版本控制的重要性,这绝非多余的提醒。在 AI 辅助编程场景下,版本控制的意义更加突出:
- 代码安全:没有版本控制,任何 AI 编码代理都可能在短时间内破坏你的代码库。及时 commit 和 push 是最基本的保护措施。
- Codex Cloud 依赖:如果你使用 Codex Cloud 远程运行任务,它依赖于一个最新的 GitHub 仓库。保持仓库同步是确保云端任务正常运行的前提。
传统开发中,版本控制(如 Git)主要用于团队协作和代码历史追溯。但在 AI 辅助编程场景下,版本控制承担了一个全新的角色:作为 AI 操作的"撤销机制"和"安全边界"。AI 编码代理(如 Codex、Devin、Cursor Agent)具备自主修改多个文件的能力,一次操作可能涉及数十个文件的变更。如果这些变更引入了隐蔽的 bug 或破坏了项目结构,没有版本控制就意味着无法回退。这一挑战类似于数据库领域中事务的 ACID 特性——我们需要确保每次 AI 操作是一个可独立回退的原子单元。
业界已经出现了一些最佳实践:在启动 AI 任务前创建专用分支、每次 AI 操作后自动创建检查点(checkpoint)、以及通过 PR(Pull Request)流程审查 AI 生成的代码。一些前沿工具已经实现了自动 checkpoint 机制,在每次 AI 修改前自动创建 git stash 或临时 commit。这些实践将版本控制从被动的历史记录工具,升级为主动的 AI 治理工具。
建议每完成一个功能或一轮 AI 辅助修改后,都进行一次提交,并在确认满意后推送到 GitHub。
总结
本文介绍的三个功能——上下文引用、推理等级调节和 TODO 转任务——代表了 Codex 扩展在开发者体验上的深度打磨。上下文功能让 AI 更精准地理解需求,推理等级让开发者在速度和质量之间灵活取舍,TODO 转任务则将 AI 无缝嵌入了日常编码习惯。掌握这些功能的合理搭配,是高效使用 AI 编程工具的关键。
核心要点
- 上下文注入是AI编程质量的基石:通过
@符号引用文件和图片上下文,精准控制模型的信息输入,但需注意上下文窗口的容量限制,有策略地选择引用内容 - 推理等级是成本与质量的调节旋钮:Medium 适合日常使用,High 留给复杂逻辑任务,Low 用于简单编辑——合理选择可以在保证质量的同时控制 token 消耗和响应延迟
- TODO 转任务重新定义了技术债务管理:将散落在代码中的 TODO 注释转化为可执行的 AI 任务,提供了系统性消化技术债务的新途径
- 版本控制是AI编程时代的必备安全网:在 AI 可能大规模修改代码的场景下,频繁 commit、创建专用分支、通过 diff 审查变更,是确保代码库安全的基本纪律
- 多模态能力打通了设计到代码的最后一公里:图片上下文让"所见即所得"成为可能,但需理解模型是语义级理解而非像素级复制,微调仍是必要步骤
相关推荐
AI Agent智能体系统学习路径:从零基础到独立开发
系统梳理AI Agent智能体的完整学习路径,涵盖基础原理、Prompt工程、RAG知识库、多Agent协作等核心技术,附带实战项目指南,帮助零基础学习者高效掌握Agent开发能力。
Kimi K2.7接入Hermes Agent实测:一句话生成完整应用
实测Kimi K2.7接入Hermes Agent智能体系统,展示一句话生成3D游戏、网页操作系统等完整应用的全流程,对比Claude 3.5基准测试数据,解析智能体团队协作与自纠错机制。
用Lovable一句话生成个人网站:零代码免费上线指南
详解如何用Lovable AI建站工具,通过一句话Prompt生成专业个人网站并免费发布上线。涵盖完整实操流程:编写Prompt、AI自动生成、对话式迭代微调到一键部署,零代码基础也能轻松搭建作品集展示页。