OpenTelemetry完全指南:可观测性三大支柱与DevOps实战

OpenTelemetry为分布式系统提供统一可观测性标准,结合AI实现智能运维
OpenTelemetry是CNCF旗下的开源项目,通过统一标准解决了日志、指标和链路追踪数据在不同工具间的碎片化问题。其核心架构包含插桩、收集器和后端三个环节,支持多语言和多平台。结合AI技术后,可观测性从被动监控走向主动预防,实现异常检测、预测性告警和自然语言查询,大幅提升DevOps效率。
引言:从咖啡店到机场的可观测性思维
想象你经营一家咖啡店,某天早晨客户开始抱怨订单太慢。问题出在哪里?是咖啡师?咖啡机?还是供应商延迟?要回答这个问题,你需要能够"看到"店内运营的每一个环节——这就是**可观测性(Observability)**的核心概念。
可观测性这一概念源自控制论,最早由匈牙利裔美国工程师Rudolf E. Kálmán在1960年提出,用于描述一个系统的内部状态能否通过其外部输出来推断。在软件工程领域,可观测性与传统监控(Monitoring)有本质区别:监控是预先定义你想知道的问题,然后设置告警;而可观测性则是让系统具备足够的信息输出能力,使你能够回答事先未曾预料到的问题。换言之,监控告诉你"系统是否正常",可观测性则帮助你回答"系统为什么不正常"。
在YouTube博主Itayesh的这期视频中,他以DevOps工程师的真实日常为切入点,系统性地讲解了OpenTelemetry的本质、它解决的问题以及AI如何改变运维监控的未来。本文将梳理其中的核心知识点,帮助你建立对OpenTelemetry的完整认知。
可观测性的三大支柱:日志、指标与链路追踪
现代软件系统的复杂度远超一家咖啡店——它更像一座巨型机场,有数百个航班、无数工作人员和多个子系统在同时运转。要监控这样的系统,你需要三大支柱:
日志(Logs):事件的详细记录
日志就像一本日记,每当应用中发生事件时就记录一笔。例如:"用户在15:00登录"、"支付在15:10完成"。它提供了事件发生的详细上下文,是排查问题时最基础的信息来源。
指标(Metrics):系统健康的数字仪表盘
指标类似汽车仪表盘上的数字——CPU使用率、内存占用、请求数量等。有些数字你一眼就能理解,有些则需要经验才能解读其含义。指标的优势在于它能快速反映系统整体状态。
链路追踪(Traces):请求的完整旅程
这是最关键的部分。Traces就像GPS轨迹,它展示了一个请求从进入系统到完成的完整旅程,跨越所有微服务节点。对于分布式系统而言,链路追踪是定位性能瓶颈的核心手段。
在分布式追踪的技术实现中,一个完整的请求旅程被称为Trace,而Trace由多个Span组成。每个Span代表一个独立的工作单元(如一次HTTP调用、一次数据库查询),包含操作名称、开始/结束时间、状态码、属性标签等信息。Span之间通过父子关系形成树状结构。要实现跨服务的追踪,关键技术是Context Propagation(上下文传播):当服务A调用服务B时,会在HTTP头中注入Trace ID和Span ID(遵循W3C Trace Context标准),服务B收到请求后提取这些信息并创建子Span,从而将整条调用链串联起来。这就是为什么在微服务架构中,即使请求经过十几个服务,我们仍能看到完整的调用链路。
OpenTelemetry解决了什么问题?

碎片化的监控困境
回到机场类比:假设每家航空公司都使用完全不同的行李追踪系统。当一件行李经过三家航空公司中转后丢失了,谁能追踪到它?答案是——没人能。因为这些系统之间无法互相通信。
这正是OpenTelemetry出现之前软件团队面临的真实困境:
- 公司用Datadog收集指标
- 用Jaeger追踪链路
- 用另一个工具管理日志
- 每个工具都需要专门的插桩库(instrumentation library)
- 前端团队和后端团队使用不同的采集和分析机制
这就像城市里每家医院都使用不同格式的病历记录——当患者转院时,新医生根本无法读取旧病历。整个行业需要一个统一的开放标准。
OpenTelemetry的诞生背景
OpenTelemetry(简称OTel)正是为此而生。它是CNCF(管理Kubernetes的同一组织)旗下的开源项目,为开发者提供了一种单一标准化方式来收集日志、指标和链路追踪数据,且与编程语言、云提供商和监控工具无关。
CNCF(Cloud Native Computing Foundation,云原生计算基金会)成立于2015年,隶属于Linux基金会,是云原生技术领域最重要的开源组织。除了管理Kubernetes这一容器编排事实标准外,CNCF还托管了Prometheus(监控)、Envoy(服务网格代理)、Helm(包管理)、etcd(分布式键值存储)等数百个项目。OpenTelemetry在CNCF的项目成熟度模型中已达到"Incubating"级别,拥有来自Google、Microsoft、Splunk、Lightstep等公司的核心贡献者。CNCF的背书意味着OpenTelemetry具备长期的社区支持和企业级可靠性。

视频中用了一个精妙的比喻:OpenTelemetry就像旅行时携带的万能电源适配器。不同国家有不同的插座形状,而万能适配器让你在任何地方都能充电。同样,你只需用OpenTelemetry标准对应用进行一次插桩,就能将数据发送到任何监控工具——无论是Datadog、Grafana、New Relic还是其他平台。
OpenTelemetry核心架构详解
OpenTelemetry的工作流程分为三个关键步骤:
第一步:插桩(Instrumentation)
将OpenTelemetry库添加到应用代码中。这些库会自动开始收集数据:每个函数的执行时间、发生的错误、进入的请求数量等关键信息。插桩是整个可观测性体系的起点。
在技术实现上,插桩分为两种主要方式:手动插桩和自动插桩。手动插桩要求开发者在代码中显式调用OpenTelemetry API来创建Span(追踪单元)、记录属性和事件,适用于需要精细控制的业务逻辑。自动插桩则利用语言运行时的特性(如Java的字节码注入、Python的猴子补丁、.NET的IL重写)在不修改业务代码的情况下自动捕获HTTP请求、数据库查询、消息队列操作等常见操作的遥测数据。例如在Java中,OpenTelemetry提供了一个Java Agent(-javaagent参数),只需在启动命令中添加即可自动为Spring Boot、gRPC、JDBC等框架生成追踪数据。
第二步:收集器(Collector)
数据流入OpenTelemetry Collector——可以把它想象成一个邮局,负责按邮编分拣信件。Collector是一个独立服务,运行在单独的服务器上(而非主服务器),这样即使应用宕机,数据收集也不会中断。它可以接收、过滤、转换数据,并导出到多个后端。
从架构设计上看,OpenTelemetry Collector采用了管道(Pipeline)架构,由三个核心组件构成:Receiver(接收器)、Processor(处理器)和Exporter(导出器)。Receiver负责接收来自应用的遥测数据,支持OTLP、Jaeger、Zipkin、Prometheus等多种格式;Processor负责数据的批处理、采样、过滤、属性修改等中间处理逻辑;Exporter则将处理后的数据发送到一个或多个后端。Collector有两种部署模式:Agent模式(作为Sidecar或DaemonSet部署在每个节点上)和Gateway模式(作为集中式服务部署)。这种解耦设计使得数据采集与数据消费完全独立,极大提升了系统的灵活性和可维护性。
第三步:后端(Backend)
Collector将数据发送到你选择的监控工具(如Grafana、Jaeger等),在这里你可以可视化仪表盘、设置告警、分析异常。
OpenTelemetry五大关键组件
| 组件 | 作用 |
|---|---|
| API | 定义规则和命令,告诉OTel需要测量什么 |
| SDK | API的实际实现,注入到代码中 |
| Auto Instrumentation | 自动收集数据,无需手动修改业务代码 |
| Collector | 独立的数据接收、过滤和转发服务 |
| OTLP | OpenTelemetry Protocol,组件间通信的标准协议 |
OTLP(OpenTelemetry Protocol)是OpenTelemetry定义的遥测数据传输协议,支持gRPC和HTTP/protobuf两种传输方式。相比早期的Zipkin格式或Jaeger的Thrift协议,OTLP的设计目标是高效、可靠且统一——它用同一种协议格式传输日志、指标和追踪三种数据类型。OTLP支持请求/响应模式,接收端会返回确认信息,确保数据不丢失。目前,几乎所有主流可观测性后端(Datadog、Grafana Tempo、Elastic APM、AWS X-Ray等)都已原生支持OTLP协议接入,这使得用户可以在不修改应用插桩代码的情况下自由切换后端平台。
实战案例:食品配送App崩溃排查
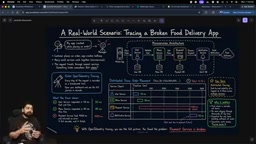
假设你在一家食品配送公司工作。客户下单时App崩溃了,经理打来电话要求尽快修复。
现代应用由多个微服务组成:登录服务、餐厅菜单服务、支付服务、通知服务等。这些微服务可能用不同语言编写(Python、Java、JavaScript),连接不同数据库。
当启用OpenTelemetry的链路追踪后,客户请求的每一步都会被记录:
- 用户服务响应:50ms ✓
- 菜单服务响应:80ms ✓
- 支付服务响应:400ms ⚠️ (瓶颈所在)
这种端到端的可见性就是**分布式追踪(Distributed Tracing)**的威力——你能立即定位到问题出在支付服务,而不是在几十个微服务中盲目排查。
AI如何革新DevOps监控
当OpenTelemetry收集的海量数据与AI结合,产生了质的飞跃:
AI与运维结合的领域被称为AIOps(Artificial Intelligence for IT Operations),这一概念由Gartner在2017年首次提出。AIOps平台通常整合大数据分析和机器学习技术,对海量运维数据进行实时分析。当前AIOps的核心能力包括:基于时间序列分析的异常检测(使用LSTM、Transformer等模型识别指标偏离)、基于因果推理的根因分析(通过服务依赖图和时间相关性定位故障源头)、基于历史模式的容量预测、以及基于大语言模型的智能问答。
异常检测(Anomaly Detection)
AI可以在十万次正常请求中发现那一次异常。传统方式下,DevOps工程师需要手动翻看图表寻找根因;现在只需点击按钮,AI就能给出可能的根因分析。
预测性告警(Predictive Alerts)
视频中展示了一个典型场景:磁盘利用率当前为85%,AI预测将在28天内达到100%。系统不仅给出告警,还提供:
- 可能影响:可能影响该服务器上托管的服务
- 建议操作:删除大文件或扩容
- 自动化工作流:可直接创建修复工单或分配给其他工程师
自然语言查询
你不再需要精通SQL或特定查询语言,可以直接用自然语言问:"为什么IO操作在这个时间点飙升?"AI会给出解释和建议,大幅降低了运维门槛。Datadog、Dynatrace、Splunk等平台已深度集成AI能力,而开源方案如Grafana也通过插件生态支持AI辅助分析。随着LLM的发展,自然语言驱动的可观测性查询正在成为行业标配。
DevOps工程师的真实日常工作
视频中展示了DevOps工程师每天面对的真实仪表盘:业务概览、服务器状态、存储配置、备份状态、网络流量、数据库健康度……这些都需要经过专业训练的眼睛来解读。
当某个指标突破阈值时,工程师需要:
- 点击告警查看详情
- 分析上下文(磁盘带宽、IO操作、网络出站流量等)
- 判断是否需要立即介入
- 执行修复或升级操作
正如视频作者所说:"从外面看,我们只是构建了一个应用。但当它到达DevOps工程师手中,这才是他们日复一日的真实工作。"
总结:从被动救火到主动预防
OpenTelemetry不是又一个监控工具,而是一个统一标准——它让不同团队、不同语言、不同工具之间能够无缝协作,共同守护系统的健康运行。结合AI的加持,现代可观测性正在从"被动救火"走向"主动预防",这对每一位软件工程师都意义重大。
无论你是刚入门的开发者还是资深的DevOps工程师,理解OpenTelemetry的核心理念和架构,都将帮助你在分布式系统时代更高效地定位和解决问题。
核心要点
- OpenTelemetry是CNCF旗下开源项目,为日志、指标和链路追踪提供统一采集标准,解决了多工具间数据孤岛问题
- 可观测性三大支柱为日志(Logs)、指标(Metrics)和链路追踪(Traces),其中分布式追踪能精确定位微服务架构中的性能瓶颈
- OpenTelemetry核心架构包含插桩(Instrumentation)、收集器(Collector)和后端(Backend)三个步骤,支持所有主流编程语言
- AI与OpenTelemetry结合后实现了异常自动检测、根因分析、预测性告警和自然语言查询,大幅减少DevOps工程师的人工排查工作
- 现代DevOps工程师日常面对复杂的监控仪表盘,需要同时关注服务器、存储、网络、数据库等多维度指标的健康状态
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。