Optimize Anything:一个API统一优化代码、提示词和Agent架构
统一框架将各领域优化问题转化为文本Artifact的LLM迭代优化,全面超越专用工具。
UC Berkeley与Stanford等团队提出Optimize Anything框架,核心思想是将CUDA内核、智能体架构、提示词等不同领域的优化问题统一转化为文本Artifact的优化。用户只需提供初始Artifact、评估器和可选数据集三个输入,系统通过辅助诊断信息(类似数值优化中的梯度)和基于Pareto前沿的搜索策略自动迭代改进。在编码智能体、ARC-AGI、云调度、AIME提示词、CUDA内核、圆排列六大领域均达到SOTA,证明了"评估+反馈+LLM迭代"可作为通用问题求解范式。
核心洞察:万物皆可文本化优化
来自UC Berkeley、Stanford等顶尖机构的联合团队发表了一篇极具突破性的论文——Optimize Anything,提出了一个通用的文本优化框架。其核心洞察出奇地简单:很多不同领域的问题,本质上都可以转化为文本Artifact的优化问题。
不管你要优化的是CUDA内核、云调度策略、智能体架构、SVG图片还是系统提示词,底层逻辑都是一样的——把目标对象序列化成字符串,评估它的效果,再让大语言模型根据诊断反馈提出改进方案。
此前,我们已经见证了LLM作为优化器的潜力:FunSearch能进化Python函数突破数学边界,AlphaEvolve能优化代码甚至改进了有五六年历史的矩阵乘法界。但这些工具都只能针对单一类型的任务,而且一次只能处理一个问题。Optimize Anything的目标,是用一个统一的API打破所有这些壁垒。
极简声明式API:三个输入搞定一切
基于上述洞察,团队设计了一个极其简洁的声明式API。用户只需要提供三个核心输入:
- 一个初始的种子Artifact(甚至可以不提供,系统从自然语言描述生成)
- 一个评估器,返回分数和可选的诊断反馈
- 可选的数据集
剩下的提示词构建、反思、候选生成、选择、搜索策略等复杂步骤,全部由系统自动处理。这个设计受到了DSPy"编程而非提示"原则的启发,最大优势是同一个API调用,不管优化LLM提示词、智能体架构还是图片,都能直接使用,不需要针对不同领域修改接口。
特别值得一提的是无种子模式:在一些很难提供初始Artifact的领域(比如3D建模),用户甚至不需要写初始版本,只需提供自然语言描述的目标,LLM会从零开始生成第一个候选方案。这大大降低了使用门槛。
三种优化模式的统一
Optimize Anything将三种优化模式统一在同一个接口下,切换完全由是否提供数据集和验证集决定:
单任务搜索
不需要提供数据集,候选本身就是解决方案,评估器直接打分。这是AlphaEvolve和OpenEvolve使用的模式。例如在圆排列问题中,Artifact就是排列算法,评估器返回排列分数和几何诊断信息。
多任务搜索
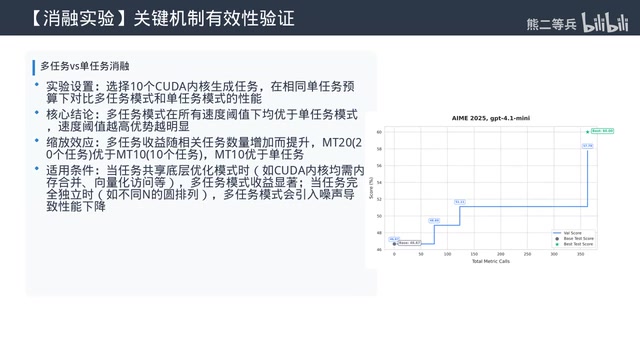
需要提供一批相关任务的数据集,解决一个任务得到的洞见可以帮助解决其他任务。这是之前所有LLM进化框架都不支持的模式。例如在CUDA内核生成场景中,每个任务是要加速的一个PyTorch操作,多任务模式能发现可跨问题迁移的优化模式。
泛化模式
需要同时提供训练集和验证集,优化后的Artifact需要在未见过的例子上表现良好。之前只有GEPA的提示词优化用这个模式,现在扩展到了任意文本Artifact。
核心区别在于:多任务搜索输出N个专用Artifact,泛化模式只输出一个全局通用Artifact。
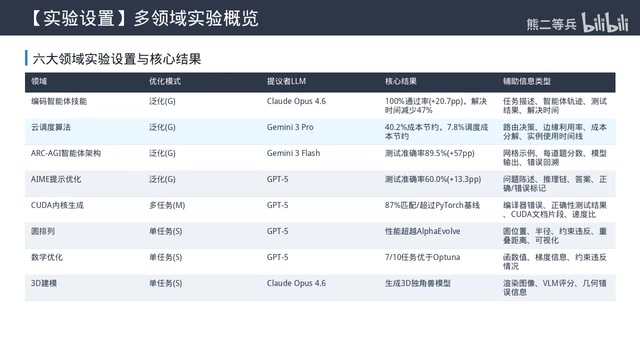
六大领域实验:全面SOTA
论文在六个完全不同的核心领域验证了效果,每个领域都达到或超过了专用工具的表现。
编码智能体技能优化(泛化模式)
优化特定代码库的自然语言使用说明和最佳实践。优化后的技能把Claude Code的通过率从79.3%提升到98.3%,Sonnet 4.5从94.88%提升到100%,解决时间减少47%。更重要的是,为一个模型发现的技能能直接迁移到另一个模型,证明了泛化模式能学习到模型无关的仓库知识。
ARC-AGI智能体架构优化(泛化模式)
系统从一个只有10行的简单初始智能体出发,迭代设计成了300多行的复杂系统,包含4个组件和完善的回退机制。测试准确率从32.5%提升到89.5%,提升了57个百分点——几乎是原来的三倍。
优化后的架构实现了4阶段流水线:模式分析归纳规则→代码生成与验证→多轮调试→结构化降级。系统自己发现了通常需要手动工程迭代才能得到的架构模式。
云调度算法优化(泛化模式)
CloudCast路由策略比最短路径算法节省了40.12%的成本;ComputeBlade调度策略节省了700%的成本。两个结果都登上了AD2S排行榜首位。
AIME提示词优化(泛化模式)
优化GPT-4o-mini在AIME数学问题上的系统提示词,测试准确率从46.67%提升到60.0%,超过MIProv2的51.33%。
CUDA内核生成(多任务搜索)
为31个PyTorch操作生成高性能CUDA内核,87.7%的生成内核能匹配或超过PyTorch基线,48%达到10%以上加速,25%达到25%以上加速。
圆排列问题(单任务搜索)
最终方案表现超过了AlphaEvolve发布的结果。
两大核心机制解析
辅助信息:文本优化的"梯度"
传统数值优化把所有诊断上下文压缩成一个标量。Optimize Anything将辅助信息提升为评估器契约的一等公民,支持多种类型的诊断反馈:
- 文本类:编译器错误、运行时异常、性能分析摘要
- 结构化数据类:每个测试用例结果、多目标子分数、执行轨迹
- 图片类:渲染SVG、3D模型截图、图表可视化
辅助信息之于文本优化,就像梯度之于数值优化——梯度告诉优化器往哪个方向走,辅助信息告诉LLM提案者候选为什么失败、怎么修复。消融实验显示,有辅助信息时收敛速度比只用分数反馈快4到6倍。
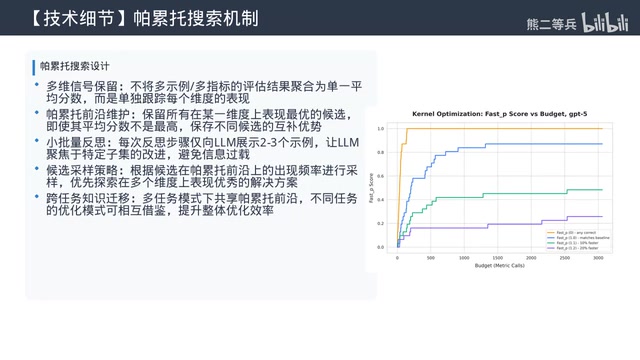
基于Pareto前沿的搜索策略
朴素的方法会把多个评估信号压缩成一个平均分数,永远选排名最高的候选,容易陷入停滞。Optimize Anything的做法更加精巧:
- 单独跟踪每个任务/指标的分数,维护Pareto前沿
- 任何在某个方面表现最好的候选都会被保留
- 每个反思步骤只给提案者看2-3个例子的小批次,针对性改进
- 迭代过程中前沿积累不同候选的互补优势
这个机制也支撑了多任务搜索——为一个问题发现的策略可以通过共享的Pareto前沿自动迁移到其他问题。
意义与展望
Optimize Anything的意义不仅是一个好用的工具,更在于它证明了**"评估+反馈+LLM迭代"的模式可以作为通用的问题求解范式**,打破了之前不同领域优化工具各自为战的局面。不管是程序员、研究人员还是缺乏编程经验的用户,都可以通过这个通用接口,用自然语言描述优化目标,让系统帮助得到高质量的结果。
从更宏观的视角看,这项工作揭示了一个重要趋势:随着LLM能力的持续提升,越来越多的工程优化问题将被重新定义为"文本生成+自动评估"的闭环。未来,这个框架还可以扩展更多优化后端、覆盖更多领域,成为AI时代的通用优化基础设施。
相关推荐
 前沿研究
前沿研究纽约中央公园发现新物种?城市昆虫猎捕计划揭秘
科学家在纽约中央公园和布鲁克林展望公园设置昆虫捕集器,试图在城市环境中发现未知物种。地球90%物种尚未被命名,城市生物多样性研究正成为生态学新趋势。
 前沿研究
前沿研究希格斯玻色子发现始末:亲历者讲述「上帝粒子」背后的故事
费米实验室物理学家亲历讲述希格斯玻色子发现全过程:费米实验室与CERN的跨大西洋竞赛、2012年历史性宣布的幕后细节、从发现到验证的14年科学历程,以及「上帝粒子」名号的真实由来。
 前沿研究
前沿研究SciMDR:7B小模型如何在科研推理上比肩GPT-5
耶鲁大学等机构推出SciMDR框架,通过两阶段数据合成流水线,让70亿参数小模型在科研文献阅读理解上达到接近GPT-5水平。本文详解其降维构建与升维重塑的核心技术原理及实验结果。