Pi AutoResearch:AI自动跑实验,性能优化不再手动试错

Pi AutoResearch让AI自主完成性能优化的实验闭环,替代人工反复试错。
Pi AutoResearch是Pi编程助手的扩展插件,灵感源自Karpathy的Auto Research项目。它将性能优化中重复的「提出方案→修改代码→跑测试→对比数据→决策迭代」流程完全自动化,开发者只需指定优化指标和执行命令,AI即可自主循环实验,适用于构建优化、测试加速、模型训练等可量化场景,实现"AI做实验,人类做决策"的协作模式。
性能优化之痛:改一行代码,折腾一下午
搞过性能优化的开发者都有体会:改一行代码就得跑一次测试,看一次数据,再决定保留还是回滚。来来回回折腾,一下午就没了。更痛苦的是,你可能试了 20 种方案,最后发现第三种才是最优的——前面十几轮实验全白费了。

这种重复性的「实验→测量→决策」循环,本质上是一个可以被自动化的流程。Pi AutoResearch 就是为解决这个问题而生的。
Pi AutoResearch 是什么?一句话理解核心思路
Pi AutoResearch 是 Pi 编程助手的一个扩展插件,灵感来自 Andrej Karpathy 的 Auto Research 项目(GitHub 上已获 1700+ Star)。它的核心逻辑非常直白:
想一个方案 → 跑一下 → 量一下 → 好的留下,差的丢掉 → 无限循环

说白了,就是把人类做性能优化时的思维模式完全自动化。AI 不再只是「给你建议」,而是一个能独立完成整个实验闭环的研究员——自己提出假设,自己验证,自己迭代。
工作流程详解:从启动到产出结果
一句话启动实验
使用体验非常丝滑,你只需要告诉它两件事:
- 优化什么指标:比如打包速度、打包体积、页面加载时间
- 跑什么命令:比如
pnpm build
剩下的全部交给 AI 自动完成。
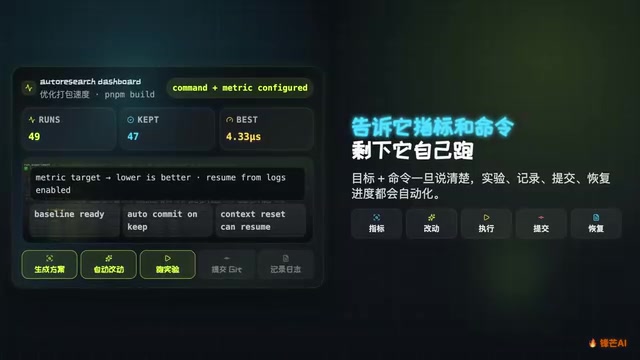
自动化实验闭环的五个步骤
Pi AutoResearch 的完整工作流程包含以下环节:
- 自动生成优化方案:AI 根据目标指标和代码上下文,提出具体的优化策略
- 自动修改代码:直接在项目中应用优化方案,不需要人工介入
- 自动跑测试:执行指定的构建或测试命令,收集性能数据
- 自动记录结果:每一轮实验自动提交到 Git,结果写入日志文件
- 自动决策迭代:对比前后数据,保留更优方案,回滚劣化方案,然后进入下一轮
断点续跑:不怕中断
一个很实用的设计细节:即使上下文重置了(比如关闭编辑器或会话超时),新的 AI 实例也能从日志文件中恢复进度,继续跑实验。你可以放心让它在后台长时间运行,不用担心进度丢失。
适用场景:哪些优化任务可以交给它?
Pi AutoResearch 几乎适用于所有可以用数值衡量的优化目标:
- 构建优化:Webpack/Vite 打包速度、打包体积压缩
- 测试优化:单元测试、集成测试的执行耗时
- 模型训练:训练损失值(loss)的下降幅度
- 前端性能:Lighthouse 评分、首屏加载时间等页面性能指标
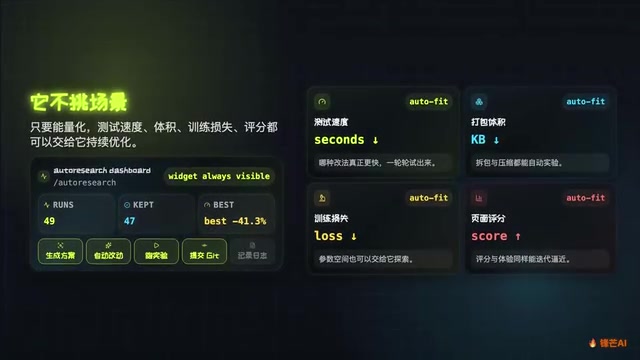
编辑器里还内置了实时看板,随时能看到跑了多少轮、当前最优值是多少,整个过程透明可控。
为什么这个思路值得关注?
从「AI 辅助编码」到「AI 自主实验」
传统的 AI 编程助手(Copilot、Cursor 等)主要是「建议型」的——给你代码片段,你来决定是否采纳。Pi AutoResearch 代表了一种更进阶的范式:AI 自主完成完整的实验循环。
这种模式特别适合性能优化场景,原因有三:
- 评判标准明确:性能指标是客观数值,不需要人类主观判断好坏
- 单次实验成本低:跑一次构建或测试只要几分钟,试错代价小
- 搜索空间大:优化方案的组合可能有成百上千种,人工逐一尝试效率太低
Karpathy Auto Research 理念的落地实践
这个项目的灵感来源——Karpathy 的 Auto Research——代表了 AI 辅助科研的一个重要方向。核心理念是让 AI 不仅仅充当工具,而是能够独立进行「假设→实验→验证」科学方法循环的智能体。
Pi AutoResearch 将这一理念从学术研究场景搬到了日常开发中,大幅降低了使用门槛。你不需要搭建复杂的实验框架,装个插件、写一句指令就能跑起来。
总结:AI 做实验,人类做决策
Pi AutoResearch 的核心价值,是把开发者从重复性的性能优化试错中解放出来。你不再需要手动尝试 20 种方案再挑出最优解,而是让 AI 替你完成这些「苦力实验」,你只管验收结果。
对于经常需要做性能调优的团队来说,这类自动化实验工具可以显著提升效率。当然,最终的优化方案是否合理、是否存在副作用,仍然需要开发者的专业判断来把关。
AI 做实验,人类做决策——这或许是当前阶段最务实的人机协作模式。
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。