苹果AI战略大转向:从拒绝聊天机器人到全面拥抱AI
苹果的态度逆转
苹果公司即将发布的AI相关公告中包含了重大的战略转向。据科技记者Mark Gurman透露,苹果高管们在去年还公开排斥聊天机器人的概念,并对AI在摄影领域的应用持否定态度。然而现在,这两项技术都即将成为苹果产品线的核心组成部分。
这一转变的速度之快,即便在科技行业也属罕见。从高管层面的公开否定到全面拥抱,苹果仅用了不到一年时间,这反映出AI竞赛的激烈程度已经超出了所有人的预期。
从"不做聊天机器人"到全面入局
聊天机器人的态度变化
苹果长期以来一直将Siri定位为语音助手而非聊天机器人,刻意与ChatGPT、Google Bard等产品保持距离。高管们曾多次在公开场合表示,苹果不认为对话式AI是正确的产品方向。这种立场在去年还被反复强调。
Siri于2011年随iPhone 4S发布,是首个被主流消费电子产品采用的语音助手。其技术架构基于传统的自然语言处理(NLP)管线:语音识别(ASR)→意图识别(Intent Classification)→槽位填充(Slot Filling)→对话管理→自然语言生成(NLG)。这种基于规则和浅层机器学习的架构虽然在特定任务(如设置闹钟、发送短信)上表现可靠,但在开放域对话、上下文理解和复杂推理方面存在根本性局限。相比之下,ChatGPT等基于大语言模型的系统采用端到端的生成式方法,能够处理几乎任何话题的自由对话,这种能力差距使得Siri在用户感知中逐渐落后。
然而,ChatGPT的爆发式增长和用户对智能对话能力的强烈需求,显然改变了苹果的判断。ChatGPT由OpenAI于2022年11月底发布,在短短两个月内用户数突破1亿,成为历史上增长最快的消费级应用。其背后的GPT系列大语言模型(LLM)基于Transformer架构,通过海量文本数据的预训练和人类反馈强化学习(RLHF)实现了接近人类水平的对话能力。Transformer架构由Google研究团队于2017年在论文《Attention Is All You Need》中提出,其核心创新——自注意力机制(Self-Attention)——允许模型在处理序列数据时同时关注输入的所有位置,从而捕捉长距离依赖关系。而RLHF则是在预训练基础上,通过人类标注员对模型输出进行排序评分,训练一个奖励模型,再用强化学习算法(如PPO)优化语言模型的输出质量,使其更符合人类偏好。这一产品的成功彻底改变了科技行业对AI商业化的认知,引发了一场被称为"AI军备竞赛"的全行业投入浪潮。当微软、Google等竞争对手纷纷推出强大的AI助手时,苹果不得不重新评估其战略定位。
AI摄影的立场逆转
在摄影领域,苹果此前一直强调其计算摄影的"真实性",暗示过度的AI处理会损害照片的真实感。这一立场曾是苹果与Android阵营(尤其是Google Pixel系列)差异化竞争的重要叙事。
所谓计算摄影(Computational Photography),是指利用软件算法和机器学习来增强或扩展传统光学摄影能力的技术,涵盖HDR合成、夜景模式、人像虚化、语义分割等功能。其本质是通过多帧合成、深度估计、场景识别等算法弥补手机小尺寸传感器在物理光学层面的先天不足。Google Pixel系列凭借其自研的Tensor芯片和先进的AI算法,在计算摄影领域长期领先,其"Magic Eraser"(魔术橡皮擦)利用生成式AI自动识别并移除照片中的干扰元素,"Best Take"(最佳表情)则能在合影中将不同时刻拍摄的最佳表情合成到同一张照片中——这些功能已经跨越了"增强现实"进入"生成现实"的领域。苹果此前虽然也使用计算摄影技术(如Deep Fusion多帧合成和Photonic Engine),但一直强调"所见即所得"的理念,刻意限制AI对照片的过度修改,将其定位为"帮助相机更好地捕捉现实"而非"创造新的现实"。
现在苹果也准备将AI深度融入摄影体验,这意味着公司已经认识到,在用户体验面前,之前的"纯粹主义"立场已经站不住脚。当竞争对手的AI摄影功能已经成为消费者购买决策的重要因素时,坚持"真实性"叙事的商业代价变得越来越高。
苹果AI战略转向背后的深层逻辑
市场压力不可忽视
苹果的转变并非突然发生。自2022年底ChatGPT发布以来,整个科技行业经历了一场AI革命。微软通过与OpenAI的合作在搜索和办公领域取得突破——Copilot已深度整合进Microsoft 365套件和Windows操作系统,Google全面重构产品线推出Gemini模型并将AI能力注入搜索、邮件、文档等全线产品,三星在手机端率先落地Galaxy AI。
三星于2024年1月随Galaxy S24系列推出了Galaxy AI功能套件,成为首个在旗舰手机上大规模部署生成式AI的主流厂商。其功能包括实时通话翻译(支持13种语言的双向实时口译)、AI摘要生成、圈选搜索(Circle to Search,与Google合作,用户只需在屏幕上画圈即可搜索任何内容)以及AI图片编辑(包括生成式填充和对象移动)等。三星的快速落地给苹果带来了直接的市场压力,因为消费者开始将AI功能视为购买手机的重要考量因素。市场调研机构的数据显示,AI功能已成为2024年消费者换机决策的前三大考虑因素之一。苹果如果继续坚持原有立场,将面临被边缘化的风险。
苹果在AI基础研究领域的积累
尽管苹果在产品层面的AI布局看似滞后,但其在基础研究方面并非毫无准备。苹果于2016年开始发表机器学习论文,2017年成立Apple Machine Learning Research部门,并在Core ML框架、Create ML工具链等开发者工具方面持续投入。2023年底,苹果发布了开源多模态模型Ferret和高效语言模型OpenELM,2024年初又推出了MLLM(多模态大语言模型)MM1系列论文,展示了其在模型架构设计和训练方法论方面的研究实力。此外,苹果在2023年以约10亿美元的年度预算推进AI研究,并从Google、Meta等公司大量招募AI人才,包括前Google AI负责人John Giannandrea(2018年加入苹果担任机器学习与AI战略高级副总裁)。这些积累为苹果的AI战略转向提供了技术基础,使其能够在决策层面一旦"开绿灯"后迅速推进产品落地。
苹果式的"后发制人"策略
有意思的是,苹果历史上多次采用"后发制人"策略——不做第一个,但做最好的一个。从iPod到iPhone,从iPad到Apple Watch,苹果习惯于等待技术成熟后再以更优的用户体验切入市场。
这一策略有着清晰的历史轨迹:2001年iPod并非第一款MP3播放器(Creative、Diamond Rio等产品早已存在),但凭借iTunes生态和标志性的滚轮交互重新定义了数字音乐;2007年iPhone发布时智能手机已存在多年(Nokia、BlackBerry、Palm等品牌主导市场),但多点触控交互和后来的App Store生态颠覆了整个行业;2015年Apple Watch进入已有Pebble、三星Gear等先行者的智能手表市场,最终凭借健康监测功能和iOS生态整合成为品类霸主,目前占据全球智能手表市场约50%的份额。这一策略的核心在于苹果拥有强大的软硬件垂直整合能力(从芯片设计到操作系统再到应用生态的全栈控制)和庞大的用户生态(超过22亿活跃设备形成的网络效应),能够在技术成熟后以更完善的体验后来居上。
但这次的不同之处在于,高管们此前的公开否定态度使得这次转向更像是一次被迫的战略调整,而非从容的布局。而且每次"等待"的时间窗口都在缩短——iPod等待了约3年,iPhone等待了约10年,但AI领域从ChatGPT发布到全行业落地仅用了一年多时间,竞争节奏前所未有地快。这或许说明AI的发展速度确实超出了苹果内部的预判,也暴露了苹果在基础AI研究领域相对于Google和Meta等公司的积累差距。
苹果拥抱AI对行业的启示
苹果的态度转变传递了一个明确信号:AI已经不再是可选项,而是必选项。即便是全球市值最高的科技公司,也无法在这场变革中独善其身。
对于消费者而言,苹果的加入意味着AI功能将以更加注重隐私和用户体验的方式呈现。考虑到苹果庞大的用户基数(全球活跃设备超过22亿台,涵盖iPhone、iPad、Mac、Apple Watch等产品线),这也将极大推动AI技术的普及化进程。历史经验表明,当苹果将某项技术纳入其生态时,往往会带动整个产业链的成熟——正如Touch ID推动了指纹识别的普及,Face ID加速了3D结构光的商用化。
接下来值得关注的是,苹果将如何在拥抱AI的同时,维护其一贯强调的隐私保护承诺——这或许才是真正的挑战所在。传统的云端AI模型需要将用户数据上传至服务器进行处理,这与苹果"数据留在设备端"的隐私理念存在根本冲突。为解决这一矛盾,苹果发展了端侧AI(On-device AI)技术,利用其自研的Apple Silicon芯片(包括专门设计的Neural Engine神经网络引擎,M4芯片的Neural Engine算力已达38 TOPS——每秒38万亿次运算)在本地完成推理计算,确保敏感数据无需离开用户设备。端侧推理的优势不仅在于隐私保护,还包括更低的延迟和离线可用性,但其挑战在于设备端的算力和内存限制了可运行模型的规模。
在设备端运行大语言模型面临严峻的工程挑战。当前主流的大语言模型参数量从数十亿到数千亿不等(如GPT-4据估计超过1万亿参数),而iPhone的内存通常仅为6-8GB。为解决这一矛盾,业界发展了多种模型压缩技术:量化(Quantization,将模型权重从32位浮点数压缩至4位或8位整数)、知识蒸馏(Knowledge Distillation,用大模型指导训练小模型)、剪枝(Pruning,移除对输出贡献较小的神经元连接)以及低秩分解(Low-Rank Factorization)等。苹果在2024年发表的研究中展示了其在高效模型设计方面的进展,包括针对Apple Silicon优化的推理引擎和自适应计算分配策略,能够根据任务复杂度动态决定在设备端处理还是调用云端资源。
同时,苹果还开发了"Private Cloud Compute"(私有云计算)架构,专门为需要超出设备端算力的复杂AI任务设计。该架构运行在苹果自研芯片的定制服务器上,采用端到端加密传输,服务器不保留任何用户数据,且代码经过独立安全审计。通过加密和匿名化技术确保用户数据不被存储或关联到个人身份,苹果试图在AI能力与隐私保护之间找到平衡点。这一技术路线能否真正兑现承诺,将是检验苹果AI战略成败的关键标尺——毕竟,隐私保护不仅是苹果的品牌承诺,更是其在监管日趋严格的全球市场中维持竞争优势的核心护城河。
全球AI监管环境的影响
苹果的隐私优先AI战略还受到全球监管环境的深刻影响。欧盟《人工智能法案》(AI Act)于2024年正式通过,对高风险AI系统提出了严格的透明度、数据治理和人类监督要求。美国虽尚未出台联邦层面的综合AI立法,但各州(如加州)正在推进相关法规。中国的《生成式人工智能服务管理暂行办法》则要求AI服务提供者确保训练数据的合法性和生成内容的真实性。在这一背景下,苹果的端侧处理和Private Cloud Compute架构不仅是技术选择,更是合规策略——通过最小化数据收集和跨境传输,苹果能够更灵活地适应不同司法管辖区的监管要求,这在数据主权意识日益增强的全球市场中构成了显著的竞争优势。这意味着苹果的"隐私即功能"定位在监管趋严的大环境下,可能从品牌差异化优势进一步升级为结构性竞争壁垒。
核心要点
- 态度逆转速度惊人:苹果从公开否定聊天机器人和AI摄影到全面拥抱,仅用不到一年时间
- 市场压力是核心驱动力:ChatGPT的爆发、微软Copilot的整合、三星Galaxy AI的率先落地,共同构成了苹果无法忽视的竞争压力
- 后发制人策略面临考验:AI领域的竞争节奏远快于此前任何技术周期,苹果的等待窗口大幅缩短
- 隐私与AI的平衡是关键:端侧AI + Private Cloud Compute的技术路线是苹果差异化竞争的核心,但能否兑现承诺仍待验证
- 行业信号明确:当苹果也不得不全面拥抱AI时,这项技术已从可选项变为必选项,将深刻改变消费电子行业的竞争格局
- 监管合规成为隐性优势:苹果的隐私优先架构在全球AI监管趋严的背景下,可能从品牌差异化升级为结构性竞争壁垒
相关推荐
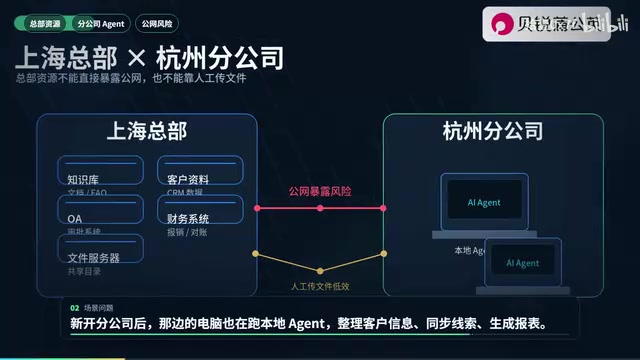
企业AI Agent异地互联:智能组网方案全解析
企业多地部署AI Agent面临网络互通难题。本文解析如何通过智能组网方案,低成本实现异地Agent统一接入总部知识库、OA系统等内部资源,保障Agent稳定高效运行。
AI大模型原理详解:Transformer架构与测试实战指南
深入解析AI大模型核心原理,从Transformer架构到概率推算本质,详解大语言模型在测试领域的应用场景、AI应用测试挑战及应对策略,帮助测试人员快速掌握AI工具与AI测试方法论。

Codex超级Agent完全指南:从安装到多任务并行实战
全面拆解OpenAI Codex桌面端应用的安装配置、Plugin外挂、Skill技能系统、Agent.md设置及多任务并行实战,帮助零编程基础用户快速上手这款超级AI Agent工具。