苹果高管秘密会议曝光:承认AI落后,WWDC反击计划浮出水面
一场没有库克的秘密会议
据彭博社记者Mark Gurman在其Power On专栏中披露,2025年初,苹果公司除CEO蒂姆·库克之外的高管团队召开了一次秘密会议。会议的核心议题只有一个:苹果在AI领域究竟落后了多少,以及如何规划反击的道路。
Mark Gurman是彭博社资深科技记者,被公认为苹果公司最可靠的信息源之一。他的Power On专栏自2021年创办以来,多次准确预测苹果产品发布和内部战略调整,其报道准确率在科技媒体中首屈一指。当他披露这样一则内部会议消息时,业界通常视为高度可信的情报。
这一消息的爆出本身就极具震撼力。作为全球市值最高的科技公司之一,苹果的高管们不得不在内部坦诚面对一个残酷的现实——他们在AI竞赛中已经明显掉队。
库克缺席背后的深层信号
这场会议最耐人寻味的细节是:蒂姆·库克并未参加。苹果除库克外的核心高管团队包括:负责软件工程的Craig Federighi、负责硬件工程的John Ternus、负责机器学习和AI战略的John Giannandrea、负责服务业务的Eddy Cue,以及CFO Kevan Parekh等。其中John Giannandrea于2018年从Google加入苹果,曾领导Google搜索和AI部门,他的存在本身就说明苹果早已意识到AI的重要性,但执行层面的进展显然未达预期。
这种安排可能传递出多重信号:
- 坦诚沟通的需要:没有CEO在场,高管们可能更愿意直面问题,不必顾虑措辞
- 执行层面的聚焦:这更像是一次技术和产品战略层面的务实讨论,而非公司治理层面的决策
- 危机意识的体现:当高管团队需要私下讨论"我们到底落后多少"时,说明内部对现状的焦虑已经到了需要集体面对的程度
苹果AI困境:竞争对手在狂飙,自己在掉队
回顾过去两年的AI竞赛,苹果的处境确实不容乐观。
竞争对手的全面领先
-
OpenAI的ChatGPT持续迭代,已深入数亿用户的日常生活。自2022年11月发布以来,ChatGPT经历了从GPT-3.5到GPT-4、GPT-4o再到GPT-4.5的快速迭代,周活跃用户已突破4亿,成为历史上增长最快的消费级应用之一。OpenAI还推出了具备深度推理能力的o系列模型,以及多模态交互能力,使AI助手从文本对话扩展到语音、图像和视频理解领域。
-
Google将Gemini全面整合进搜索、邮件、办公等核心产品。Gemini模型家族采用了从Ultra到Nano的多层级架构设计,分别对应云端重度计算和端侧轻量推理场景。Google将其深度嵌入Gmail、Google Docs、Google Search等月活数十亿的产品中,实现了AI能力的无缝渗透,用户几乎无需主动寻找AI功能,它已自然融入日常工作流。
-
微软通过Copilot将AI能力嵌入Windows和Office生态。微软的Copilot战略覆盖了从操作系统到办公套件再到开发工具的全栈场景。凭借对OpenAI超过130亿美元的投资,微软获得了GPT系列模型的优先商用权。GitHub Copilot已拥有超过190万付费用户,Microsoft 365 Copilot则瞄准全球数亿企业用户,将AI生产力工具的商业化推向了前所未有的规模。
-
Meta开源Llama系列模型,构建开发者生态。从Llama 1到Llama 3.1再到Llama 4,Meta采用了与OpenAI截然不同的开源路线。Llama模型的累计下载量已超过10亿次,通过降低行业AI门槛、建立技术标准影响力,Meta在AI基础设施层面获得了巨大的话语权。
Apple Intelligence落地不及预期
2024年WWDC上发布的Apple Intelligence虽然展示了苹果的AI愿景,但实际落地进度远低于预期。从技术架构来看,Apple Intelligence采用了混合计算方案:简单任务在设备端由Apple自研的神经引擎处理,复杂任务则通过Private Cloud Compute(私有云计算)在苹果自建的云端服务器上运行,承诺数据不会被存储或对苹果可见。此外,苹果还与OpenAI达成合作,在用户明确授权后可调用ChatGPT处理特定请求。
然而,Siri的智能化升级一再延迟,许多承诺的功能迟迟未能交付给用户。对于一家以"体验为王"著称的公司来说,这种落差尤为刺眼。
苹果面临的三大结构性挑战
苹果在AI领域面临的并非简单的技术差距,而是多重结构性难题:
隐私优先的路线约束:苹果长期将隐私作为核心卖点,这在一定程度上限制了其收集和利用大规模用户数据训练AI模型的能力。现代大语言模型的训练依赖海量数据,包括用户交互数据用于RLHF(基于人类反馈的强化学习)对齐优化。Google和Meta等公司可以利用数十亿用户的搜索记录、社交互动和内容消费数据来持续改进模型。苹果的差分隐私(Differential Privacy)技术虽然允许在不暴露个体数据的前提下进行统计学习,但其信息密度远低于直接使用原始数据。当竞争对手可以大量使用云端数据时,苹果的隐私承诺在赢得用户信任的同时,确实在数据飞轮效应上形成了结构性劣势。
端侧计算的物理限制:苹果倾向于在设备端运行AI模型,但端侧AI推理面临内存带宽和计算密度的物理瓶颈。以iPhone 16 Pro搭载的A18 Pro芯片为例,其神经引擎算力约为35 TOPS(每秒万亿次运算),内存为8GB。而云端单张NVIDIA H100 GPU就能提供约4000 TOPS的AI推理算力,配合数百GB的高带宽显存。这意味着端侧能运行的模型参数量通常限制在数十亿级别,而云端模型可达数千亿甚至万亿参数,两者在理解能力和生成质量上存在代际差距。iPhone和Mac的算力与大型数据中心相比仍有巨大鸿沟,这直接制约了模型的规模和能力上限。
组织文化的惯性:苹果擅长打磨硬件和封闭生态体验,但AI时代需要的是快速迭代、开放协作的研发模式,这与苹果一贯的保密文化存在天然矛盾。AI模型的进步高度依赖学术界的开放研究、开源社区的协作贡献,以及快速发布、快速迭代的"ship fast, break things"文化。苹果数十年来形成的产品保密传统和追求完美才发布的理念,在AI竞赛的速度要求面前显得格格不入。
WWDC 2025:苹果AI反击战即将打响
Gurman暗示,这场秘密会议的成果即将在WWDC 2025上公之于众。WWDC历史上多次成为苹果重大战略转向的舞台:2005年宣布从PowerPC转向Intel芯片、2014年发布Swift编程语言、2020年宣布从Intel转向Apple Silicon自研芯片。每一次转折都深刻重塑了苹果的技术路线和竞争格局。如果2025年WWDC确实承载了苹果AI反击战的使命,其历史意义可能不亚于上述任何一次转折。
苹果将如何回应AI落后的质疑?是激进追赶还是另辟蹊径?
可以预见的是,苹果不会简单复制竞争对手的路径。其优势仍然在于:超过20亿台活跃设备的庞大生态、深度整合的软硬件协同能力、以及用户对其品牌的长期信任。关键在于,苹果能否将这些独特优势转化为差异化的AI体验——例如利用设备端传感器数据实现真正个性化的AI助手,或通过硬件级优化让端侧模型在特定场景下超越通用云端方案。
这场没有库克的秘密会议,或许正是苹果AI战略真正觉醒的起点。接下来的WWDC,将是检验这场觉醒成色的关键时刻。
核心要点
相关推荐
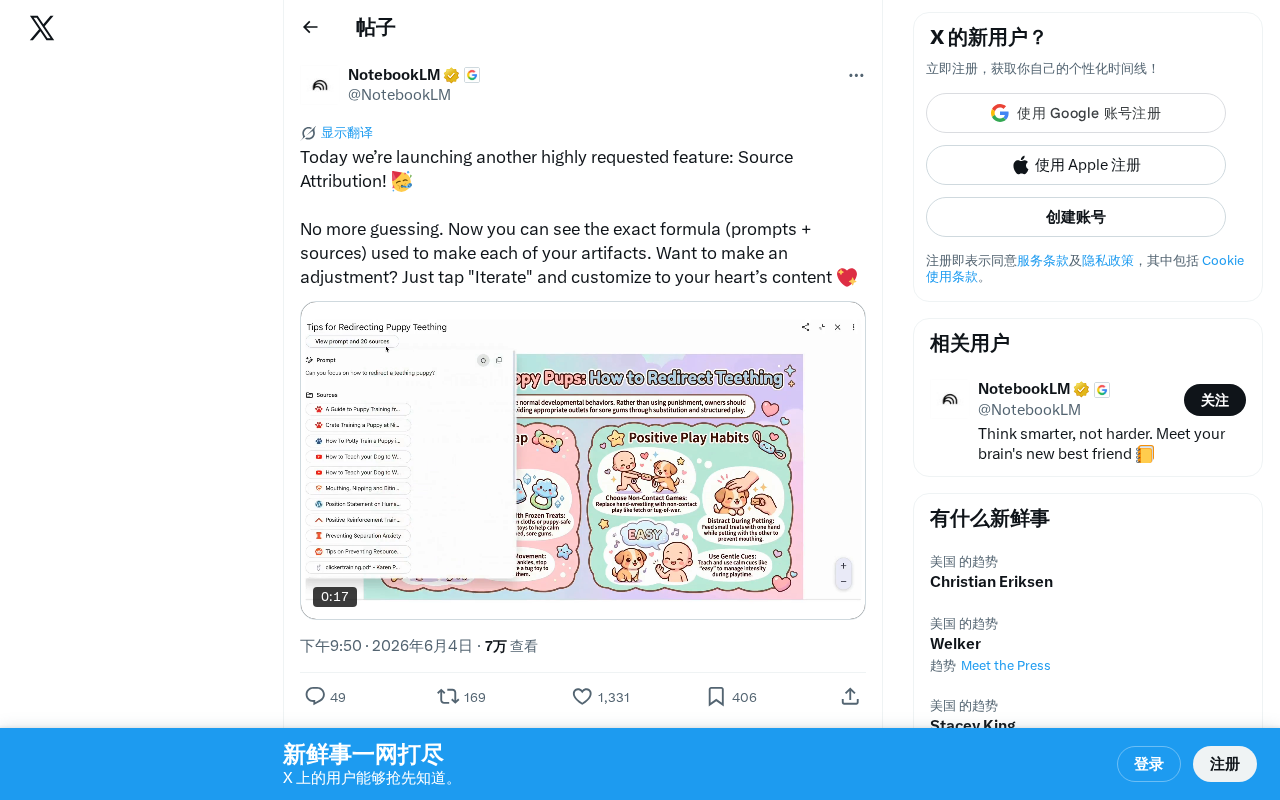
Exa推出Source Attribution功能:AI内容溯源透明化新标杆
Exa推出Source Attribution来源归因功能,用户可查看AI生成内容的提示词、引用来源等完整配方,并支持一键迭代优化。这一功能解决了AI透明度痛点,推动行业向可解释、可溯源方向发展。

前Anthropic工程师实测:为何弃用Claude Code转投Codex
前Anthropic工程师Pietro分享他弃用Claude Code转投Codex的深层原因,详解Codex高效工作流、模型切换策略、键盘文本替换技巧,以及AI Agent如何重塑软件行业和创业方法论。

大模型微调入门:用你的数据再教AI几招
详解大模型微调(Fine-tuning)的核心概念、三大特征与适用场景。了解如何用少量高质量数据,在预训练模型基础上训练出懂你业务的专用AI模型,以及微调与RAG、提示词工程的选型对比。