MARVIS项目:嵌入式AI Agent赋能太空自主探索全解析

MARVIS项目探索将大语言模型Agent部署到太空飞行器,实现自主科学探索。
MARVIS项目通过生成式AI和大语言模型Agent架构,赋予太空探测器自主科学分析与决策能力。POC验证表明,未经微调的小型量化模型通过提示词工程即可胜任行星科学分析,且与大型云端模型无显著性能差异。团队还对多种边缘硬件进行了推理性能实测,并规划了太空AI基准测试集和分布式多Agent协同探索系统。
在2026年飞行软件研讨会(FSW 2026)上,来自Armijo Innovations的George Williams分享了MARVIS项目的最新进展——探索如何将生成式AI和大语言模型Agent部署到太空飞行器中,赋予探测器自主科学发现的能力。这项工作横跨AI Agent架构设计、边缘硬件推理性能评估和太空通用智能基准测试三大领域,为未来深空自主探索勾勒出一条清晰的技术路线。
从卡尔·萨根的愿景到AI自主探索
演讲者以一段个人故事开场:他对太空自主探索的兴趣可以追溯到卡尔·萨根在《宇宙》中描绘的场景——未来的探测器应该"能够自主思考,装载精密的生物和化学仪器,漫游、嗅探、品尝、探索,每天自主选择自己的地平线"。在萨根的愿景中,人类在整个任务过程中基本上是被动的观察者。

从火星车的遥控操作到逐步增强的自主导航能力,过去几十年太空探索已经取得了长足进步。但真正意义上的科学自主探索,要求飞行器具备以下关键能力:
- 扎实的基础科学知识与天生的探索好奇心
- 自主设计和执行实验的能力
- 风险与收益的综合评估能力
- 识别危险并自主呼叫地球的应急能力
- 控制仪器和与导航系统交互的执行能力
这正是MARVIS项目的出发点——借助生成式AI和大语言模型,尝试赋予太空探测器上述属性。
MARVIS项目的AI Agent架构与POC验证
数据集构建与大语言模型选型
团队精心策划了一组模拟行星探测器可能遇到的典型或挑战性场景图像数据集,涵盖地面和空中获取的地质结构、大气天气系统,以及可能的生命迹象。
在模型选型上,团队对比了两类方案:
- GPT-4o Mini:超过100亿参数,需要多块服务器级GPU,适合云端部署
- Gemma(Google):40亿参数,权重高度量化至4位,可在多种边缘计算设备上运行
两者均支持多模态推理,能够对图像进行科学分析,为后续的边缘部署对比提供了基础。
简洁高效的Agent架构设计
MARVIS采用了一个极其简洁的AI Agent架构。自上而下,传感器数据(图像)首先提交给科学分析Agent,由特定系统提示词指导其进行科学评估;分析结果随后传递给分诊Agent,由它根据科学分析结论决定任务下一步行动——继续探索还是发出危险警报。
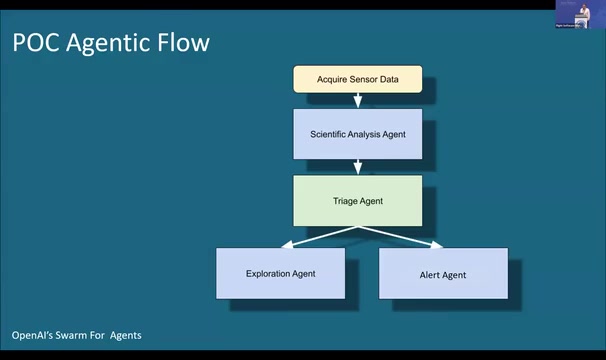
说个细节,所有Agent都通过自然语言提示词进行"编程",彼此之间也通过自然语言通信。唯一的传统代码是大约半页的Python脚手架,用于创建Agent的有向无环图(DAG)。团队使用了OpenAI开源的Swarm框架进行Agent编排,同时指出AutoGen、CrewAI、LangChain等框架同样适用。
在叶子节点,Agent被要求输出结构化数据(JSON格式),利用语言模型的工具调用能力——因为在真实航天系统中,模型需要与只有结构化接口(如软件API或库调用)的仪器和设备交互。
关键点:团队没有对模型进行任何与任务相关的训练或微调,仅通过系统提示词赋予每个Agent角色定义,这大幅降低了部署门槛。
POC测试结果:科学分析与自主决策能力验证
在层状沉积岩图像测试中,科学分析Agent准确识别出"层状沉积岩地层,可能代表古代河床或湖泊沉积物,明显的色带表明矿物成分的变化"。分诊Agent则正确建议继续探索,认为这是值得深入调查的重点区域。
在沙尘暴图像测试中,系统不仅准确检测到沙尘暴,还自动发出安全警报,指出"显著的大气扰动对飞行器运行构成潜在危险"——而团队从未明确指示Agent在看到云层时发出警报,仅仅是让它检测对飞行器的危险状况。这种涌现式的安全判断能力令人印象深刻。

专家评估与边缘硬件推理性能对比
人类专家对AI Agent输出质量的评估
为了系统验证AI分析的质量,团队对88名受访者进行了调查,使用李克特量表分别评估Agent的科学分析和任务决策表现:
- 非航天领域专家:给出了"好到优秀"的评分
- 航天领域专家(有任务工程或规划经验):评分下降约一个等级,但仍接近"好"的范围
一个关键发现是:大型云端模型与小型边缘模型之间没有统计学上的显著差异。这意味着在太空场景下,经过量化的小模型完全有能力胜任科学分析任务,为嵌入式AI的边缘部署提供了有力支撑。
边缘硬件Token生成速率实测对比
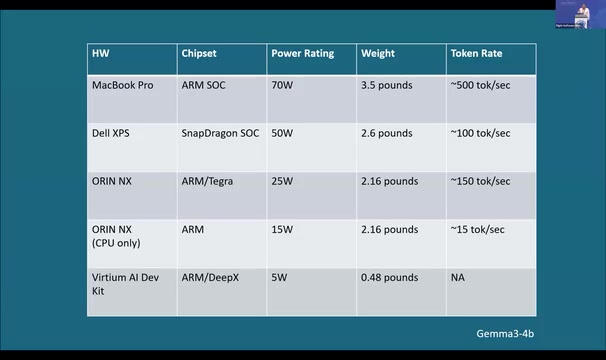
团队认为硬件厂商常用的MAC速率或TOPS指标并不能准确预测大语言模型的实际推理性能,因此直接测量了各平台的Token生成速率:
| 硬件平台 | 功耗 | 推理运行时 | 表现概述 |
|---|---|---|---|
| MacBook Pro | 70W | MLX on Metal | 作为参考基准,Token速率最高 |
| Snapdragon X Elite | — | Qualcomm Neural Network SDK | 表现尚可,Qualcomm认为还有优化空间 |
| Jetson Orin NX | — | llama.cpp / TensorRT-LLM | 充分利用Tegra GPU时表现良好 |
| Vertium AI Dev Kit(DeepX芯片) | 5W | DeepX专有库 | 超低功耗却拥有先进AI推理芯片 |
团队还特别指出一个容易被忽视的问题:同一模型在不同硬件上可能产生不同推理结果,甚至同一硬件上重复运行也可能出现微小差异。再加上大语言模型固有的幻觉问题,建立系统化的准确性评估体系对于航天飞控场景至关重要。
未来规划:太空通用智能基准与自主实验设计
MMMUSGI:面向太空场景的AI基准测试集
团队正在策划一个专门面向太空领域的语言模型Agent通用智能评估数据集——MMMUSGI,灵感来源于跨模态基础模型评估数据集MMU。该数据集包含两大核心测试维度:
- 真实火星直升机导航相机图像:用于测试地质识别和异常检测能力
- 人工生成的结构损伤图像:用于测试视觉结构损伤检测能力
这一基准测试集的建立,将为太空嵌入式AI Agent的能力评估提供统一标准。
分布式协同探索原型系统
团队正在设计一个分布式协同探索原型系统,计划与加州和亚利桑那州的大学合作,将现有架构扩展为巡视车和无人机协同探索的多Agent系统。系统将配备:
- 便携式显微镜和便携式气相色谱仪
- 便携式质谱仪
- 低成本机械臂(约150美元的Hugging Face机器人臂),由视觉-语言-动作模型(VLA)控制
项目最核心的目标是:开发一个能够利用可用仪器自主设计实验的AI Agent。 理想情况下,Agent仅需获得仪器的功能描述,就能自行推断出可以完成的科学研究——这正是萨根数十年前描绘的那个"自主思考、自主探索"的愿景在AI时代的工程实现路径。
从POC到太空自主探索的工程路径
MARVIS项目揭示了一个重要的技术趋势:将前沿AI能力——生成式AI、大语言模型、多Agent架构——从数据中心推向极端边缘环境,即太空飞行器。POC阶段的结果表明,即使是未经微调的小型语言模型,通过精心设计的Agent架构和提示词工程,也能在行星科学分析和任务决策方面展现出令人满意的能力。
随着边缘AI硬件的持续进步和模型量化技术的日趋成熟,将AI Agent嵌入航天飞控系统不再是科幻想象,而是一条正在被逐步验证的工程路径。从MARVIS的实践来看,太空自主探索的技术基础已经初步具备,接下来的挑战在于可靠性验证、基准测试标准化以及分布式多Agent系统的工程落地。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。