RAG检索核心原理:Top-K粗召回与Rerank精排序完整流程详解
通俗讲解RAG检索底层逻辑:Top-K召回、Rerank精排与上下文压缩
本文用通俗语言讲解了RAG(检索增强生成)系统的底层检索逻辑。RAG的核心是先从知识库检索相关资料,再让大模型基于资料生成答案。文章重点阐述了工程化RAG的三步流程:Top-K粗召回(用Bi-Encoder快速筛选候选片段)、Rerank精排序(用Cross-Encoder深度评分挑出高相关内容)、去重压缩(精简证据后交给大模型),并解释了K值设置的权衡问题及各环节的技术原理。
很多人在学习AI应用开发时,调用大模型接口并不难,但一碰到RAG知识库问答就开始犯懵——向量检索、Top-K、召回、Rerank,这些概念听起来很高级,却搞不清它们在系统中各自扮演什么角色。这篇文章用最通俗的方式,帮你彻底理清RAG检索的底层逻辑。
RAG的本质:先找证据,再回答问题
RAG(Retrieval-Augmented Generation,检索增强生成)的核心思想可以用一句话概括:不是让大模型凭空回答,而是先帮大模型把资料找出来,再基于资料生成答案。
举个简单的例子:用户问"公司的出差住宿标准是多少?"如果知识库里有几千份制度、合同、通知、手册,系统不可能把所有资料都塞给大模型。就像你去图书馆问管理员一个问题,他不会把整栋楼的书搬到你面前——靠谱的管理员会先判断答案可能在哪几本书、哪几页、哪几个段落里。
RAG系统的工作方式完全一样:用户提问之后,第一步不是生成答案,而是先从知识库里把最可能相关的资料片段捞出来,这个动作叫做"检索召回"。
知识库构建是RAG的隐形地基
RAG系统的效果不仅取决于检索算法,还高度依赖知识库的构建质量。文档在入库前需要经过**分块(Chunking)**处理——将长文档切割成适合检索的片段。分块策略直接影响召回质量:块太小会丢失上下文,块太大会引入噪声。常见策略包括固定长度分块、按句子/段落分块、递归字符分块等,部分高级实现还会采用"父子块"策略——用小块检索、大块喂给模型。此外,元数据过滤(如按文档类型、时间范围预筛选)也是提升检索精度的重要手段,可以在向量检索前先缩小候选文档范围。
Top-K:检索召回的第一道筛网
什么是Top-K?
Top-K的含义非常直白:从一大堆资料里,先挑出最像答案的前K个片段。
具体流程是这样的:
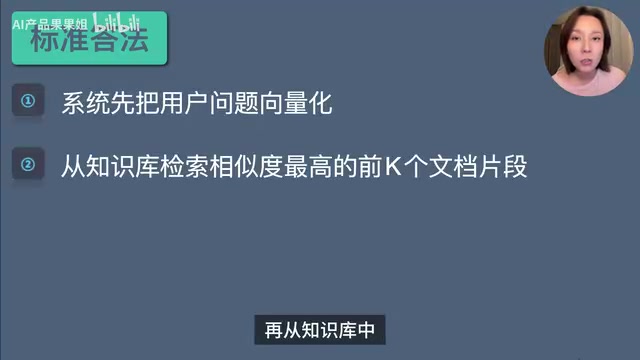
- 系统先把用户问题转成向量(Embedding)
- 去向量数据库里做相似度匹配
- 取相似度最高的前K个片段作为候选内容
Embedding与向量数据库:Top-K的技术底座
Embedding(嵌入)是将文本转换为高维数值向量的技术,是RAG系统的底层基础。其核心原理是:语义相近的文本在向量空间中距离更近。主流的Embedding模型包括OpenAI的text-embedding-ada-002、开源的BGE系列(BAAI/bge-large-zh)等,向量维度通常在768到3072之间,维度越高表达能力越强,但计算成本也越高。
向量数据库(如Faiss、Milvus、Qdrant、Weaviate)专门为高效的向量相似度检索而设计,支持余弦相似度、欧氏距离等多种距离度量方式,能在毫秒级完成百万级向量的近似最近邻(ANN)搜索。正是这种"用空间距离衡量语义相似度"的能力,让Top-K检索既快速又具备语义理解能力,远超传统关键词匹配。
比如用户问出差住宿标准,系统可能召回"差旅制度""住宿标准""报销流程""发票要求"等相关片段,而不会把"年会通知""食堂公告""员工生日福利"这些无关内容塞进来。
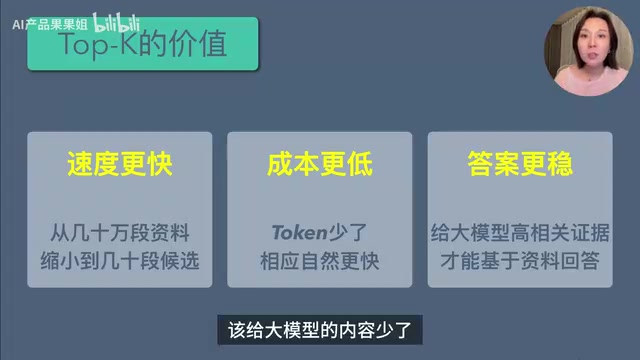
Top-K带来的三重价值
这一步看似简单,实际上解决了三个关键问题:
- 检索速度更快:从几十万段资料缩小到几十段候选内容,检索效率大幅提升
- Token成本更低:塞给大模型的内容少了,Token消耗降低,响应速度更快
- 生成答案更稳:给大模型高相关的证据,它才能基于资料回答;给一堆杂音,答案就容易跑偏
K值设置的两难困境
但Top-K并不是K越大越好,这里存在一个经典的权衡问题:
- K太小会漏掉关键信息:如果真正的答案排在第6位,而你只取了前3个,就直接错过了
- K太大会引入噪声:如果取前50个,里面混进大量无关资料,大模型就像被一群人围着七嘴八舌,最终答案反而跑偏
这就引出了RAG工程化的核心问题——仅靠Top-K粗召回是不够的,还需要后续的Rerank精排和上下文压缩环节。
工程化RAG的三步流程:粗召回 → 精排序 → 压缩去重
真正好用的RAG系统,不会在Top-K取完后就直接丢给大模型。更稳健的工程化做法通常分为三步:
第一步:Top-K粗召回——先撒大网
在这一步,系统会设置一个相对较大的K值(比如Top-30或Top-50),目的是保证关键资料不被遗漏。宁可多捞一些,也不能让真正的答案在第一轮就被过滤掉。这是一个典型的"宽进"策略。
第二步:Rerank精排序——挑出好鱼
Rerank(重排序)是粗召回之后的关键环节。它使用专门的重排模型(如Cross-Encoder),对Top-K召回的候选片段重新打分排序,判断每个片段与用户问题的真实相关度。
为什么需要Rerank?因为向量相似度匹配虽然快,但精度有限——它是基于语义空间的"粗略距离"来判断的。而Rerank模型会把问题和每个候选片段放在一起做深度语义理解,相当于让一个更专业的评审重新审核一遍,筛选出真正高相关的内容。
Bi-Encoder vs Cross-Encoder:为什么Rerank更精准?
Rerank阶段使用的Cross-Encoder与Embedding阶段使用的Bi-Encoder在架构上有本质区别。Bi-Encoder将问题和文档分别独立编码成向量再计算相似度,速度极快,适合在百万级文档中粗筛;Cross-Encoder则将问题和候选文档拼接后一起输入模型,通过注意力机制让两者充分交互,输出一个精确的相关性分数。
这种深度交互使Cross-Encoder的精度远高于Bi-Encoder,但计算成本也更高——对每个候选片段都需要单独推理一次。因此工程上通常先用Bi-Encoder快速粗召回,再用Cross-Encoder对少量候选结果精排,形成"粗排+精排"的两阶段架构。常用的Rerank模型包括Cohere Rerank、BGE-Reranker、bce-reranker-base等,其中BGE-Reranker对中文支持尤为友好。

第三步:去重与压缩——精简证据
经过Rerank之后,还需要对结果做最后的清理:
- 去重:多个片段可能包含重复信息,合并去除冗余
- 压缩:删掉过长或无用的内容,只保留能直接支撑答案的核心证据
- 拼接上下文:将精选后的片段组织成结构化的上下文,交给大模型生成最终答案
用一句话总结这三步的关系:Top-K是先撒网,Rerank是挑好鱼,压缩是去杂质,最后才端给大模型。
面试实战:如何回答Top-K在RAG中的应用
如果面试官问:"如何把Top-K算法应用到RAG检索环节,提升召回效率?"你可以这样回答:
在RAG系统中,Top-K主要用在检索召回阶段。系统会先把用户问题向量化(通过Embedding模型转为高维向量),再从向量数据库中检索相似度最高的前K个文档片段,作为候选上下文。这样可以快速缩小检索范围,减少无关内容,降低Token成本,提高响应速度。但K值不能盲目设大,实际项目里通常会先做Top-K粗召回(用Bi-Encoder快速筛选),再结合Rerank精排序(用Cross-Encoder深度评分)和上下文压缩,把最终高质量的片段交给大模型生成答案。
这样回答的关键在于:不仅说清了Top-K是什么,还展示了你对整个RAG检索链路的理解——从粗召回到精排序再到最终生成,体现的是系统性思维而非概念堆砌。
总结
学习RAG不要一上来就背术语,先把底层逻辑吃透:
- RAG的本质是"先找证据,再基于证据回答
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。