RAG系统全流程解析:从向量索引到生产优化
RAG技术如何让大模型在企业应用中精准可靠地工作
文章系统讲解了RAG(检索增强生成)技术的完整体系。RAG通过只检索最相关的文档片段来克服大模型无法获取私有数据、成本高、易产生幻觉三大局限。核心流程包括:文档分片与向量化索引、向量相似度与关键词混合召回、重排精选,以及最终生成回答。生产环境中还需通过问题澄清、多语种衍生与问题拆解、问题分类器三大优化技巧提升系统效果。
为什么企业应用离不开RAG
在当前AI应用落地的浪潮中,RAG(检索增强生成)已经成为几乎每一个企业级AI应用的标配技术。无论是电商客服、企业知识库,还是专业文档问答系统,RAG都是让大模型从"聪明但不可靠"变为"精准且可用"的关键桥梁。
大模型本身存在三个核心局限:第一,它无法获取企业私有数据和实时变动的信息;第二,将整篇文档塞入上下文窗口会导致成本暴涨且推理速度极慢;第三,面对海量信息时容易产生幻觉,生成不准确甚至虚假的内容。
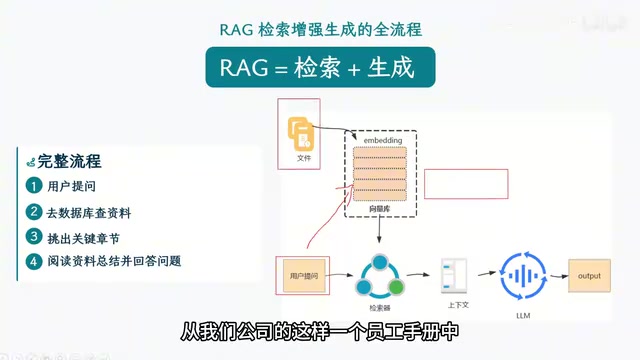
RAG的核心思路非常简洁——只查找最相关的片段。假设整本员工手册有一万条数据,当用户询问年假政策时,系统只需检索出与休假相关的十条信息交给大模型,而非让模型阅读全部内容。这样做的好处是三重的:节省token成本、提升响应速度、降低90%以上的幻觉率。
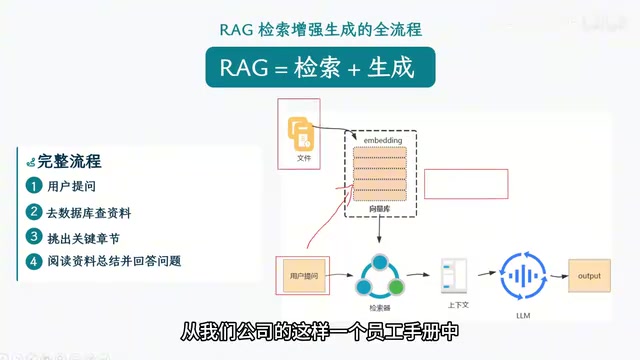
向量与索引:RAG的基础设施
什么是向量嵌入
向量在AI应用中不同于高中数学里的二维三维概念,它通常是几百维到几千维的高维数据。维度越高,承载的语义信息越丰富。
其核心原理可以这样理解:将高维向量简化为三维空间来观察,你会发现描述相似主题的文本(如运动员相关内容)转化为向量后,在空间中的位置是聚集的;而描述不同主题的文本(如小动物相关内容)则分布在另一个区域。语义相近的文本,在向量空间中距离也相近——这就是向量检索的数学基础。
当用户提出问题时,系统将问题同样转化为向量,然后在向量空间中寻找距离最近的文本片段,这些片段就是与用户问题最相关的知识内容。
分片策略的选择
索引流程的第一步是将企业文档切割成合适大小的片段。如果不做分片,直接将整篇文档转化为一个向量,那和把文档直接丢给大模型没有本质区别。
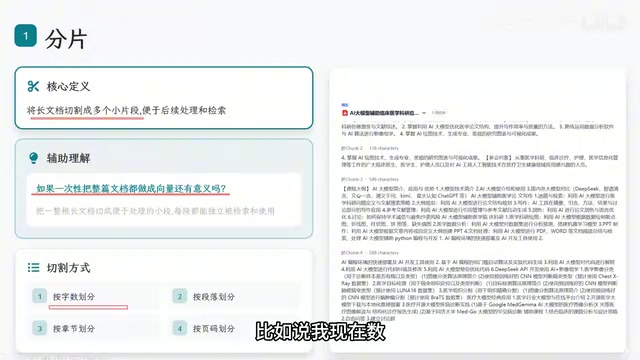
常见的分片方式有四种:
- 按字数划分:每300字切一刀,简单但容易切断语义完整性
- 按段落划分:以换行为界,保证段落内语义完整
- 按章节划分:适合结构化文档,如技术手册按章节切分
- 按页码划分:适合PDF等有明确分页的文档
选择哪种方式没有标准答案,关键在于根据实际业务场景来决定。医学文献适合按章节,客服FAQ适合按段落,合同文件可能适合按页码。
召回与重排:精准度的关键
召回策略
将文本片段存入向量数据库后,当用户提问时,系统需要从海量片段中找回相关内容。主要有两种召回方式:
- 向量相似度计算:使用余弦相似度或欧式距离,找出与用户问题向量距离最近的片段
- 关键词匹配:传统的文本匹配方法,只要文档中出现关键词就纳入候选
实际生产中,通常会结合两种方式(混合检索),然后返回Top-N结果,比如相似度最高的前10个片段。
为什么重排不可或缺
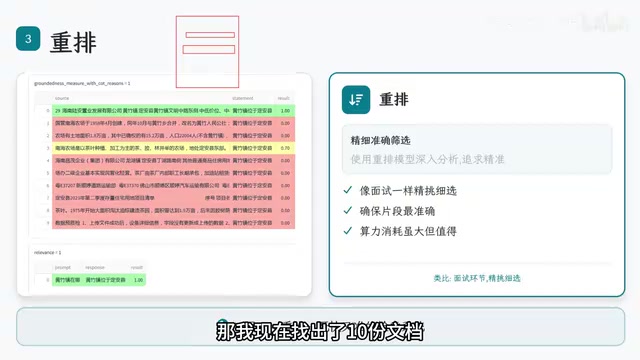
召回阶段是"宁可多找,不可遗漏"的粗筛过程,返回的结果中必然存在大量干扰信息。以"黄竹镇位于哪里"这个问题为例,召回的10份文档中可能混杂了各种仅仅提到"黄竹"但与地理位置无关的内容。
重排(Reranking)就是对召回结果进行精细化打分和排序的过程。它通过更精确的算法(通常是交叉编码器)对每个片段与用户问题的相关性重新评估,确保最终交给大模型的是分数最高、最相关的片段。
这一步虽然消耗额外算力,但完全值得——如果跳过重排,大模型面对一堆混乱信息,整个RAG系统的努力将前功尽弃。
生产环境的三大优化技巧
优化一:澄清提问
现实中用户的问题往往模糊不清。比如用户说"我想编写一个技术文档",系统无法判断具体是哪篇文档。此时应该让大模型先进行问题澄清,追问"您希望编写哪篇技术文档?",获取足够信息后再进入检索流程。
优化二:问题衍生
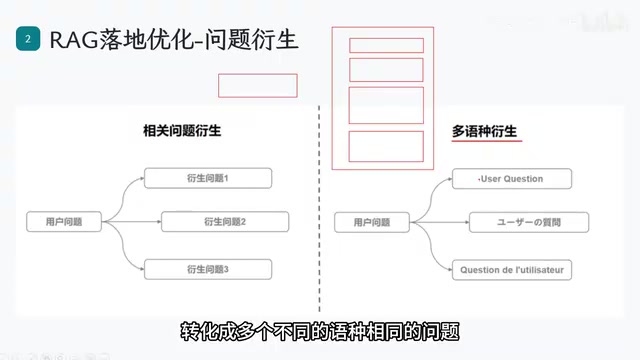
问题衍生包含两个维度:
多语种衍生:当知识库中同时存在中文、英文、日语等多语言文档时,将用户问题翻译成多种语言分别检索,可以大幅提升召回率。
问题拆解:当用户提出复杂问题(如"金融报表文档应该怎么编写")时,系统将其拆解为多个子问题——格式要求是什么?有无特殊条件?必备元素有哪些?分别检索后汇总,避免单一复杂查询无法获取充足资料。
优化三:问题分类器
当企业拥有多个知识库(人事、财务、ERP等)时,问题分类器可以先判断用户问题属于哪个领域,再定向到对应知识库检索。这不仅提升了检索精度,更重要的是在高并发场景下(如千人同时使用)大幅降低系统负载。
总结:构建可靠RAG的核心要素
一个完整的RAG系统包含以下关键环节:
- 输入处理:澄清、衍生、分类
- 索引构建:合理分片 + 向量化存储
- 检索召回:向量相似度 + 关键词混合检索
- 重排精选:交叉编码器精细打分
- 生成回答:选择合适的大模型基于事实生成
掌握这些核心环节,无论是搭建电商客服系统还是企业专属知识库,都能让AI真正做到基于事实、准确可靠地服务用户。RAG不是一个一劳永逸的方案,而是需要根据业务场景持续调优的系统工程。
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。