SAM3深度解析:Meta开源视觉分割模型如何用自然语言理解现实世界

Meta开源SAM3实现自然语言驱动的通用视觉分割,零样本性能提升超26%
Meta发布的SAM3将视觉分割从手动点选进化为自然语言驱动,通过零样本学习能力解决了传统视觉AI需要针对新类别重新训练的核心痛点。在SA-V基准测试中零样本分割得分48.8,较此前最佳提升超26%,视频追踪准确率达人类标注水平的80%。SAM3.1进一步提升多目标追踪速度,推动视觉AI从专用模型走向通用基础设施。
从手动点选到自然语言驱动:视觉分割的范式转变
Meta开源的SAM3(Segment Anything Model 3)正在重新定义视觉分割的交互方式。过去使用SAM追踪篮球比赛中的某个球员,你需要手动点击目标人物,模型才能开始跟踪;换一个人就要再点一次,出现新目标就要再次标注。

而现在,SAM3支持直接输入"白色球衣"这样的文字描述,模型就能自动匹配到所有符合条件的目标。即便存在遮挡、快速运动、镜头切换等复杂场景,追踪依然保持稳定。这意味着视觉分割从"逐一指认"进化到了"一句话搞定"的阶段。
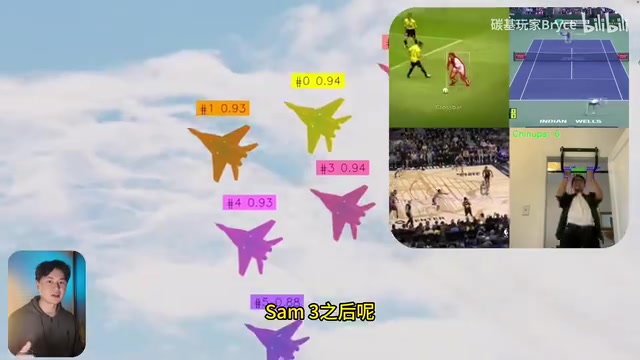
要理解这一突破的意义,需要了解视觉分割技术的演进脉络。视觉分割是计算机视觉的核心任务之一,目标是将图像或视频中的每个像素归类到特定对象或区域。这一领域经历了从语义分割(按类别划分像素)、实例分割(区分同类别的不同个体)到全景分割(兼顾前景与背景)的技术演进。2023年Meta发布的SAM初代版本是一个里程碑——它通过在超过10亿个掩码的SA-1B数据集上训练,首次实现了"提示驱动"的通用分割能力。SAM3是这一系列的第三代产品,核心突破在于将分割能力从静态图像延伸到动态视频,并引入了更强的自然语言理解能力。
SAM3解决了视觉AI落地的哪些核心痛点
开放世界识别的工程死结
长期以来,视觉AI在实际部署中面临一个根本性矛盾:现实世界中需要处理的概念是开放的、无限的,但传统模型能识别的类别却是固定的、有限的。
具体表现在多个行业场景中:
- 物流系统:每出现一种新产品,就需要重新收集数据、重新训练模型
- 体育分析:追踪新的战术配合需要重新标注大量视频
- 视频剪辑:处理特定视觉元素需要逐帧手动操作
SAM3的通用化解决方案
SAM3从根本上改变了这个局面——部署一次之后,只需输入文字描述就能直接覆盖新场景,不需要针对每个新类别重新训练。这将视觉AI从"专用模型"推向了"通用基础设施"的定位。
这种能力的技术基础是零样本学习(Zero-Shot Learning)。传统的监督学习模型本质上基于"封闭世界假设"——只能识别训练集中出现过的类别,遇到新类别就会失效。零样本能力的实现依赖于语义嵌入空间的构建:模型学习的不是"某个具体类别的外观",而是"视觉特征与语义描述之间的对应关系"。SAM3通过大规模视觉-语言对齐训练,使模型能够理解"白色球衣"这类自然语言描述所对应的视觉特征,从而在未见过的场景中直接泛化,无需任何额外的样本示例。
SAM3性能数据:零样本分割提升超26%
SAM3在多个基准测试中展现了显著的性能提升:
- 零样本分割能力:在SA-V(Segment Anything Video)基准的零样本分割测试中,SAM3拿到了48.8分,而此前的最佳成绩仅为38.5分,提升幅度超过26%。这个指标衡量的是模型在从未见过的类别上能否直接识别并精准分割。
- 视频追踪准确率:达到人类标注水平的80%,意味着在大多数场景下SAM3的追踪质量已经接近人工标注。

值得注意的是,视频目标追踪面临的技术挑战远比静态图像分割复杂。首先是时序一致性问题:同一目标在不同帧之间可能因光照变化、运动模糊、视角变化而呈现出截然不同的外观。其次是遮挡处理:目标被其他物体遮挡后重新出现时,模型需要维持对该目标的"记忆"。第三是多目标混淆:当多个相似目标(如同队球员)交叉运动时,模型容易发生身份混淆(ID Switch)。传统追踪方法如SORT、DeepSORT依赖卡尔曼滤波和外观特征匹配,而SAM3采用了基于Transformer的时序建模架构,通过跨帧注意力机制(Cross-frame Attention)在整个视频序列中维持目标的语义一致性——这正是其在复杂运动场景下保持稳定追踪的技术基础,也是48.8分这一成绩背后的核心支撑。
SAM3应用场景与当前局限性
潜在的高价值应用方向
基于SAM3的能力特征,以下几个方向有望产生实质性的效率提升:
- 体育科技:实时追踪球员、分析战术跑位,无需预先标注
- 视频制作:自动分割特定元素,大幅减少后期工作量
- 工业检测:快速适应新产品线的质检需求
- 数据标注:半自动化标注流程,降低人工成本
现阶段的局限性
需要客观指出的是,SAM3目前的文字提示能力仍有限制——只能处理简单的名词短语,复杂的语义描述还无法有效理解。例如你可以说"白色球衣",但很难用一段复杂的条件描述来精确定位目标。这一限制本质上源于当前视觉-语言对齐模型在组合语义理解(Compositional Semantic Understanding)方面的不足,即模型处理多个条件叠加的复杂指令时,准确率会显著下降。这也是下一代模型需要重点突破的方向。
SAM3.1更新:迈向通用视觉基础设施
2024年3月,Meta更新发布了SAM3.1,在多目标追踪速度上又提升了一个档次。SAM3.1的核心目标是将视觉理解从专用模型变成通用基础设施——一个模型、自然语言驱动、覆盖大多数场景。

SAM3.1所代表的"通用视觉基础设施"概念,与自然语言处理领域GPT系列模型的演进路径高度相似。在NLP领域,预训练大模型的出现使得开发者无需从头训练模型,只需通过提示工程或少量微调就能适配各种下游任务。视觉基础模型正在复制这一范式:一个在海量数据上预训练的通用模型,通过自然语言接口覆盖绝大多数视觉理解需求。这对行业的深远影响在于,计算机视觉应用的开发成本将从"数据收集+模型训练+部署维护"的重资产模式,转变为"API调用+提示设计
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。