Cursor Skills原理深度解析:从Function Call到实战
从Function Call到MCP再到Skill,解析AI工具调用的演进原理与实践
本文从底层Function Call机制出发,逐步拆解MCP协议和Skill的技术本质。Function Call解决大模型"怎么调用"外部工具的问题,MCP协议统一了"调哪里"的标准,而Skill作为按需加载的Markdown文件(Sub-Agent),解决了复杂任务高效编排的问题,避免了Workflow Agent提示词膨胀的痛点。文章还通过Spring AI Alibaba实战展示了如何对接任意大模型实现Skill功能。
引言
在AI编程工具快速迭代的今天,Cursor的Skills功能成为了开发者关注的焦点。很多人知道怎么用,却不清楚它背后的运作原理。本文将从底层的Function Call(Tools)出发,逐步拆解MCP协议、Workflow Agent,最终深入Skill的本质,并通过Spring AI Alibaba的实战案例,展示如何对接任意大模型来实现Skill功能。
从Tools说起:大模型如何调用外部能力
Function Call的核心机制
要理解Skill,首先必须理解它的基石——Function Call(也称为Tools)。
Function Call最早由OpenAI在2023年6月的GPT-3.5/GPT-4 API更新中正式引入,随后迅速成为大模型与外部世界交互的事实标准。其核心思想源自编程语言中的RPC(远程过程调用)概念,但做了一层关键抽象:大模型不直接执行代码,而是通过生成符合JSON Schema规范的结构化输出来"描述"它想要调用的函数及参数。这种设计巧妙地将大模型的自然语言理解能力与确定性的程序执行解耦,避免了让大模型直接生成和运行代码带来的安全风险和不确定性。
当我们让大模型查询"北京的天气"时,大模型本身并不具备实时信息获取能力。它的做法是:经过推理后发现有一个专门用于查询天气的Tool,然后返回一段结构化的JSON信息,其中包含Tool对应的方法名称以及所需参数(如查询位置"北京")。
应用程序识别到这段JSON后,通过反射机制找到对应方法并执行调用。这里的反射机制(Reflection)是Java等编程语言中在运行时动态发现和调用方法的能力——应用程序利用反射根据大模型返回的方法名字符串定位到实际的函数实现并传入参数执行。所以,Tools的本质是将非结构化的自然语言转化为可处理的结构化JSON信息,让大模型间接调用应用程序中的方法。
Tools解决的是"怎么调用"的问题,但紧接着会面临"调哪里"的问题。
MCP协议:统一的外部调用标准
当我们需要大模型查询第三方服务(如博客内容、地图位置等)时,为每个第三方服务都声明一个Tools方法,实现成本极高。更麻烦的是,如果有多个AI应用程序,每个应用都需要重复实现这些Tools方法——因为它们无法共享。
MCP(Model Context Protocol,模型上下文协议)正是为解决这个问题而生的。 它由Anthropic于2024年11月正式发布并开源,旨在成为AI应用连接外部数据源和工具的"USB-C接口"。在MCP出现之前,每个AI应用与每个外部服务之间都需要定制化的集成方案,形成M×N的复杂度问题。MCP将其简化为M+N:服务提供方只需实现一次MCP Server,所有支持MCP的AI应用(MCP Client)都能直接调用。
MCP提供了两种统一的调用方式:
- STDIO方式:标准输入输出。MCP Server作为子进程运行,通过标准输入输出流交换JSON-RPC消息,延迟极低但仅限本机使用,适用于本地进程间通信场景。
- HTTP方式:包括SSE和Streamable两种变体。SSE(Server-Sent Events)基于HTTP长连接,支持服务端向客户端推送实时数据流,适合远程调用场景。Streamable HTTP是后续引入的改进方案,解决了SSE在某些网络环境下的兼容性问题,支持更灵活的请求-响应模式。
通过MCP协议,第三方服务可以自行声明和暴露Tools方法,大模型以统一协议远程调用这些外部工具。但需要注意的是,MCP本质上依然离不开Function Call——对大模型而言,它不区分内部Tools还是外部Tools,所有的都只是"工具"。
Skill的诞生:从Workflow到按需加载
Workflow Agent的痛点
大模型的调用场景越来越复杂,往往不是调用单个Tool就能完成的。比如:
- 让大模型打开浏览器,请求百度搜索特定信息
- 让大模型获取桌面上的文件信息并进行分类
这就是所谓的Workflow模式下的Agent。Workflow Agent(工作流智能体)是当前AI Agent领域的主流架构之一,典型的实现框架包括LangChain的Agent模块、AutoGPT、以及微软的AutoGen等。我们需要通过大量提示词告诉大模型:针对不同任务如何拆分步骤、每一步如何处理。例如"搜索网络信息"需要拆分为:打开浏览器→输入搜索关键词→获取网页内容→推理返回结果。
这种方式的问题在于:提示词极其庞大,需要一次性全部发给大模型,效率低且难以维护。在传统Workflow模式下,所有可能的任务处理逻辑都需要以System Prompt(系统提示词)的形式预先注入大模型的上下文窗口。随着能力的增加,这些提示词可能膨胀到数万甚至数十万Token,不仅消耗大量的上下文窗口资源(即使是Claude 3.5的200K上下文窗口也会捉襟见肘),还会导致大模型的注意力分散,降低对当前任务的推理精度——这就是所谓的"Lost in the Middle"问题,即大模型对超长上下文中间部分的信息关注度显著下降。
Skill的设计哲学
Anthropic(Claude大模型的开发商)意识到这个问题后,推出了Skill机制。Anthropic成立于2021年,由前OpenAI研究副总裁Dario Amodei和Daniela Amodei兄妹联合创立,是目前AI领域最具影响力的公司之一,其旗舰产品Claude系列模型以安全性和长上下文处理能力著称。
Skill机制的设计深受软件工程中"关注点分离"(Separation of Concerns)和"延迟加载"(Lazy Loading)思想的影响。Skill本质上是一个Markdown文件,包含两个核心部分:
- 元数据(Metadata):描述当前Skill的作用,如"网络搜索"、"文件处理"等
- 指令(Instructions):详细编排每一步的执行逻辑,包括调用哪些Tool、执行哪些脚本(Python/JS)等
选择Markdown作为Skill的载体格式颇具深意:Markdown是大模型训练语料中最常见的结构化文本格式之一,大模型对其解析和理解能力极强;同时Markdown的可读性好、编辑门槛低,普通开发者甚至非技术人员都能编写和维护Skill文件。
Skill的核心优势在于按需加载。完整的工作流程如下:
- 系统将所有Skill的元数据(仅描述信息)发送给大模型
- 大模型根据用户请求推理,选择匹配的Skill,返回一段JSON(包含
callSkill方法和Skill名称) - 应用程序根据Skill名称读取对应的Markdown文件
- 将该Skill的完整指令发送给大模型
- 大模型根据指令逐步执行
与Workflow Agent的关键区别是:不需要把所有处理能力的提示词一次性发给大模型,只需发送当前所需能力的Skill指令即可。这也是为什么Skill也被称为Sub-Agent——它只是大智能体中的一个子环节。Sub-Agent(子智能体)的概念来源于多智能体系统(Multi-Agent System),每个Sub-Agent专注于特定领域的任务,由一个主智能体(Orchestrator)根据需要动态调度,这种架构在复杂任务处理中展现出远超单一智能体的灵活性和可扩展性。
Skill的本质仍是Function Call
理解到这里,你会发现Skill依然沿用的是Function Call这套机制。它内部提供了一个内置的Function Call(如callSkill方法),用于读取对应的Skill文本,然后返回给大模型进行推理和执行。因此,必须有支持Function Call的大模型才能使用Skill。
实战:Spring AI Alibaba对接任意大模型实现Skill
虽然Skill最初由Claude模型推出,但既然我们理解了原理,就可以通过Spring AI Alibaba结合Tools来对接任意大模型实现相同功能。
代码结构解析
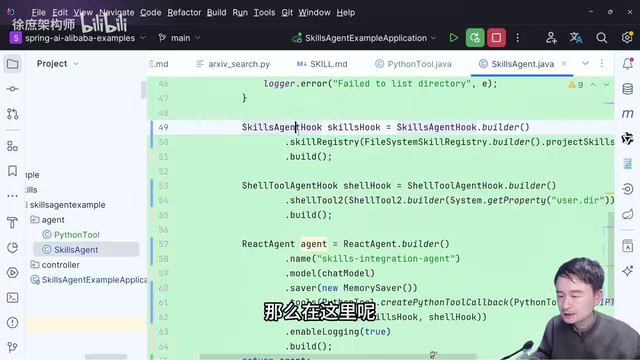
Spring AI Alibaba是阿里巴巴基于Spring AI框架开发的扩展项目,旨在为Java生态提供与国内大模型(如通义千问Qwen系列)的无缝集成能力。Spring AI本身是Spring官方于2023年推出的AI应用开发框架,提供了统一的API抽象层,使开发者可以用相同的代码接口对接不同的大模型提供商(OpenAI、Anthropic、Ollama等),类似于Spring Data对不同数据库的抽象。
在Spring AI Alibaba最新版本中,核心实现非常简洁:
- 定义Skill Agent:框架已内置封装,只需提供Skill文件的根目录路径,框架会自动读取所有Skill的Markdown文件
- Shell命令执行能力:因为Skill可能需要执行Python等脚本语言,需要通过CMD命令方式执行
- Python工具支持:依靠GraalVM提供的第三方库来执行Python代码。GraalVM是Oracle开发的高性能多语言虚拟机,其Polyglot(多语言互操作)特性允许在JVM中直接执行Python、JavaScript、Ruby等语言的代码,无需启动独立的解释器进程,既避免了跨进程通信的开销,又提供了沙箱级别的安全隔离。
开发者真正需要做的只有两件事:提供Skill的Markdown文件和对应的Python脚本。
实际运行效果
以"搜索蛋白质折叠预测的最新论文"为例:
系统的执行过程展现了Skill的智能编排能力:
- 大模型读取对应的Skill Markdown文件
- 发现需要执行Python脚本,先检测Python环境是否就绪
- 确认环境后运行Python脚本,访问arXiv网站搜索论文
- 首次搜索结果不理想,大模型自动推理可能的问题原因
- 检查脚本逻辑、重新运行、调整搜索策略(如使用分类搜索)
- 最终成功获取五篇相关论文
整个过程中,大模型会根据Skill描述文件自动决定每一步的执行方式,包括错误处理和策略调整,充分体现了Agent的自主推理能力。这种"遇到问题→分析原因→调整策略→重试"的闭环正是Agent区别于简单API调用的核心特征,也是ReAct(Reasoning + Acting)范式在实际场景中的生动体现。
Skill生态与资源
目前已有丰富的现成Skill可供使用。通过 skills.sh 网站可以搜索到超过4万个社区贡献的Skill,涵盖网络搜索、文件处理、代码分析等各类场景,开发者可以按需选用。
skills.sh的运作模式类似于npm之于JavaScript、PyPI之于Python——为AI Skill提供了一个集中的发现、分享和分发渠道。这些Skill覆盖的场景从简单的文件操作、网络请求,到复杂的数据库管理、CI/CD流水线操作、Kubernetes集群管理等DevOps场景,形成了一个日益丰富的能力生态。Skill的Markdown文件通常只有几KB到几十KB大小,相比传统的插件系统(需要编译、打包、安装),其分发和更新的成本几乎为零,这种轻量级特性也是Skill生态能够快速增长的重要原因。
Skill的Markdown文件格式天然适合传输和共享,这也是其相比传统Workflow Agent的一大优势。
总结
从Function Call到MCP,再到Skill,AI工具调用的演进路径非常清晰:
- Function Call解决了"怎么调用"的问题
- MCP协议解决了"调哪里"的问题(统一外部调用协议)
- Skill解决了"复杂任务如何高效编排"的问题(按需加载的Sub-Agent)
三者并非替代关系,而是层层递进的能力叠加。理解了这条技术脉络,无论是使用Cursor还是自研AI应用,都能做到知其然更知其所以然。值得注意的是,这条演进路径也暗合了软件架构从单体到微服务再到Serverless的发展趋势——从紧耦合走向松耦合,从静态配置走向动态编排,最终实现按需加载、弹性伸缩的能力供给模式。
核心要点
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。