什么是大模型?一文讲透参数、模型与AI大模型的本质

从模型、参数到训练数据,系统解析AI大模型的本质与核心概念。
本文从基础概念出发,解释了AI大模型的本质。模型是对复杂世界的简化表示,通过高维向量映射现实信息;参数(权重和偏置量)决定了模型的表达能力。大模型的"大"体现在参数规模大、训练数据大、计算量大三个层面。文章还介绍了Transformer架构、SFT与RLHF对齐技术,并为开发者提供了模型选择的实用建议。
很多人天天把大模型挂在嘴边,却很少有人能给它下一个清晰的定义。什么是大模型?要回答这个问题,我们需要先拆解"大模型"中的"模型"和"大"分别意味着什么。本文从最基础的概念出发,帮你真正理解AI大模型的本质。
什么是模型?——对复杂世界的简化表示
要理解大模型,首先得搞清楚"模型"这个概念。其实我们生活中处处都有模型:
- 汽车模型是对真实汽车的缩小复制
- 神话故事是对自然现象的概念化解释(比如"龙王发怒"解释洪水)
- 数学公式
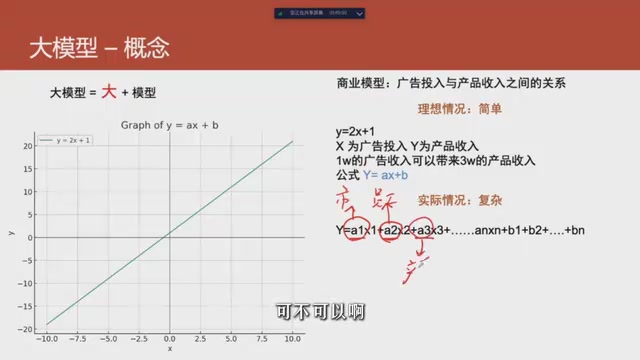
y = 2x + 1是对广告投入与产品收入关系的抽象描述
这些看似毫不相关的事物,其实有一个共同的本质:模型是客观事物的简化表示。

为什么需要简化?因为现实世界太复杂了。光是描述一个"人",就涉及性别、年龄、身高、学历、长相、声音等无数维度,甚至可以细化到毛孔数量、指甲长短。要把这些复杂信息映射到计算机世界,就需要一种简化的表示方式——在深度学习领域,这种表示通常以高维向量的形式存在。
所谓高维向量,简单来说就是一组有序的数字列表,比如 [0.2, -0.5, 0.8, 0.1]。"高维"意味着这个列表非常长,可能有几百甚至上万个数字。在自然语言处理领域,这种技术被称为词嵌入(Word Embedding),由 Google 在 2013 年发布的 Word2Vec 模型首次大规模普及。词嵌入的核心思想是:语义相近的词在向量空间中距离也相近。例如,"国王"和"王后"的向量距离会比"国王"和"苹果"更近。更神奇的是,向量之间还能做运算——经典的例子是"国王 - 男人 + 女人 ≈ 王后"。这种将离散的文字转化为连续数值空间的方法,让计算机第一次真正能够"理解"语义关系。
参数:描述复杂世界的关键
从简单公式到海量参数
回到广告投入与产品收入的例子。理想情况下,y = ax + b(其中 a=2, b=1)就能描述两者的关系,只需要两个参数。但现实远比这复杂——产品收入不仅取决于广告投入,还受天气、市场环境、员工积极性、产品受欢迎程度、地理位置等多种因素影响。
两个参数显然不够用。于是我们引入更多参数:
- a1、a2、a3... 对应不同维度的权重(weight)
- b1、b2、b3... 作为偏置量(bias),保证结果不受噪音干扰
不管是权重还是偏置量,统称为参数(parameters)。参数越多,模型能捕捉到的现实世界的细节就越丰富。
从数学直觉上理解,权重决定了输入信号的重要程度——权重越大,对应的输入因素对最终结果的影响越大。偏置量则类似于一个"基准线",它让模型在所有输入都为零时仍能输出一个非零值,从而提高模型的灵活性。在神经网络中,每一层的每个神经元都有自己的权重和偏置量。以一个简单的三层神经网络为例,如果输入层有 100 个节点、隐藏层有 200 个节点、输出层有 10 个节点,仅第一层到第二层之间就有 100×200=20000 个权重参数,再加上 200 个偏置量。当网络层数加深、每层节点数增多时,参数量就会急剧膨胀,这也是深度学习模型参数量动辄数十亿的根本原因。
参数多少决定了模型的表达能力
有人可能会问:参数越多越好吗?这里有一个很形象的比喻——炒一盘宫保鸡丁,如果只放盐和油,当然也能吃;但如果加上花椒、干辣椒、酱油、醋、糖、蒜末、姜末,口味就丰富得多。
参数的作用类似于这些调料,它们共同表达客观世界的复杂性。以"猫"这个字为例,在向量表示中,它的每一个维度都描述不同的含义:
- 第一个位置可能表示"是动物"
- 另一个位置表示"与狗的关系"
- 还有位置可能表示"猫腰(动词)"或"某个品牌"
不同模型的向量维度差异很大:
| 模型 | 向量维度 |
|---|---|
| GPT-3.5 | 12288 维 |
| OpenAI Embedding 模型 | 约 1288 维 |
| 千帆平台 | 648 或 684 维 |
维度越长,表达能力越强,但计算成本也越高。
"大"模型到底大在哪里?
参数规模的指数级增长
理解了参数的概念,"大模型"的"大"就很好理解了——大,首先是参数量大。来看 GPT 系列的参数增长趋势:
| 模型 | 参数量 |
|---|---|
| GPT-1 | 1.1 亿(0.11B) |
| GPT-2 | 15 亿(1.5B) |
| GPT-3 | 1750 亿(175B) |
从 1.1 亿到 1750 亿,参数量呈指数级增长。开源模型中,LLaMA 系列最大的版本达到 70B(700 亿参数),同样是相当可观的规模。
GPT 系列模型的底层架构是 Transformer,这是 Google 团队在 2017 年发表的里程碑式论文《Attention Is All You Need》中提出的。Transformer 的核心创新是自注意力机制(Self-Attention),它允许模型在处理一个词时同时关注句子中所有其他词的信息,而不像之前的循环神经网络(RNN)那样必须逐词顺序处理。这种并行化的设计不仅大幅提升了训练效率,还让模型能够捕捉长距离的语义依赖关系。GPT(Generative Pre-trained Transformer)采用的是 Transformer 的解码器部分,通过"预测下一个词"的方式进行预训练。从 GPT-1 到 GPT-3,模型架构本身并没有发生根本性变化,主要的提升来自于参数规模的扩大和训练数据的增加——这也印证了**规模定律(Scaling Law)**的发现:在一定范围内,模型性能会随参数量和数据量的增加而持续提升。
一个关键数字值得记住:GPT-3 拥有 1750 亿(175B)参数。 这个数字在行业交流中经常被提及,是衡量大模型规模的重要参考基准。

参数多 ≠ 大模型的全部
但仅仅参数多就够了吗?答案是否定的。参数多只能提供表达复杂世界的能力,但模型还必须学习足够多的知识才能真正理解这个复杂的世界。
这就涉及到训练数据的规模和质量。大模型的训练数据通常来自互联网上的公开文本,包括网页、书籍、论文、代码仓库、维基百科等。以 GPT-3 为例,其训练数据集包含约 4990 亿个 token(可以粗略理解为单词或词片段),数据来源涵盖 Common Crawl(经过过滤的网页数据)、WebText2、Books1、Books2 和英文维基百科。在计算量方面,训练 GPT-3 消耗了约 3640 PetaFLOP/s-day 的算力,使用了数千块 NVIDIA V100 GPU,训练成本估计在 460 万到 1200 万美元之间。这也是为什么大模型的研发门槛极高——不仅需要顶尖的算法团队,还需要巨额的硬件投入和电力消耗。OpenAI 的 CEO Sam Altman 曾透露,GPT-4 的训练成本超过 1 亿美元。
所以大模型的"大"实际上包含三层含义:
- 参数规模大——模型有足够的容量
- 训练数据大——模型有足够的知识来源
- 计算量大——训练过程需要巨大的算力支撑
三者缺一不可,共同构成了我们今天所说的"大模型"。
大模型的"聪明"与"学坏"
一个有趣的现象是:参数越多,模型越聪明,但学好容易,学坏也容易。
大模型在训练过程中学习了互联网上几乎所有公开的知识——好的、坏的,全部都知道。我们通过 Prompt(提示词) 做的事情,本质上不是在"教"模型新东西,而是在唤醒它对已有知识的记忆。模型本身并不知道该说什么、不该说什么。
这也是为什么 GitHub 上能找到各种把 GPT "调教"成不当角色的案例。对于开源模型的使用,建议选择 SFT(Supervised Fine-Tuning)版本,即经过监督微调的版本。这类模型在特定领域经过调优,输出更加稳定和可靠。
值得深入了解的是,SFT 只是让大模型变得"可控"的第一步。OpenAI 在 ChatGPT 中还引入了 RLHF(Reinforcement Learning from Human Feedback,基于人类反馈的强化学习)。RLHF 的流程是:先让模型对同一个问题生成多个回答,然后由人工标注员对这些回答进行排序,再用这些排序数据训练一个"奖励模型",最后通过强化学习算法(如 PPO)让大模型学会生成人类更偏好的回答。正是 SFT + RLHF 的组合,让 ChatGPT 实现了从"能力强但不可控"到"既聪明又听话"的质变,这也被称为对齐(Alignment)——让模型的行为与人类的价值观和意图对齐。
开发者实用建议:如何选择合适的大模型
对于普通开发者来说,使用开源模型时不一定要追求最大参数量。以 LLaMA 为例,7B 版本在大多数常见任务中已经表现不错,性价比极高。选择模型时的核心原则:
- 任务匹配优先:根据实际应用场景选择合适的参数规模
- 优先选择微调版本:SFT 版本比基座模型在实际使用中更稳定
- 平衡性能与成本:参数越大,推理成本越高,不必一味追求规模
理解了"模型是对复杂世界的简化表示"和"大是参数规模的量级跃升"这两个核心概念,你就抓住了大模型最本质的含义。后续在学习 RAG、LangChain、AI Agent 等进阶内容时,这些基础认知将帮助你更好地理解整个AI技术体系。
简单来说,这三者的关系可以这样理解:大模型是"大脑",RAG 是"参考书",LangChain 是"开发工具箱",AI Agent 是"能自主行动的完整个体"。 RAG(Retrieval-Augmented Generation,检索增强生成)通过在生成回答前先从外部知识库中检索相关文档,解决了大模型知识过时和"幻觉"(编造事实)的问题。LangChain 是一个开源的大模型应用开发框架,它将 Prompt 管理、链式调用、记忆管理、工具集成等常见需求封装成标准化组件,大幅降低了开发门槛。AI Agent(智能体)则让大模型不仅能"说",还能"做":通过规划、推理和调用外部工具(如搜索引擎、代码执行器、API 接口),自主完成复杂任务。掌握了本文的基础概念,你就为深入探索这些前沿方向打下了坚实的基础。
核心要点
- 模型的本质是对客观事物的简化表示,通过高维向量将复杂现实映射到计算机世界
- 大模型的'大'首先体现在参数规模上,GPT-3拥有1750亿参数,参数越多表达复杂世界的能力越强
- 权重和偏置量统称为参数,类似于炒菜的调料,越丰富则对现实世界的描述越精确
- Prompt的本质是唤醒大模型已有的知识记忆,而非教授新知识
- 使用开源模型建议选择SFT监督微调版本,7B参数量级即可满足大多数常见任务需求
相关推荐
 深度解读
深度解读OpenClaw开源小龙虾AI Agent运作原理深度解析
深度解析OpenClaw(开源小龙虾)AI Agent的底层运作原理,涵盖System Prompt、工具调用、SubAgent分身、Skill系统、记忆机制与Context Engineering等核心概念,帮你彻底理解AI Agent与普通语言模型的本质区别。
 深度解读
深度解读Transformer本质解析:一个被拆解的文字接龙函数
用文字接龙的视角理解Transformer本质。将复杂的语言生成任务拆解为Embedding、Transformer Block、概率输出三大模块,帮助深度学习初学者快速建立直觉。
 深度解读
深度解读Claude Code与普通AI对话的五大核心差异
详细对比Claude Code与普通AI对话工具在交互方式、上下文理解、执行力、记忆能力和工具调用五个维度的核心差异,帮你理解AI编程助手的真正价值。