Sonar实测53个大模型代码质量:Claude安全漏洞最多,GPT-5代码量暴增5倍

AI生成代码的信任危机
根据Pragmatic Engineer的调查数据,目前55%的代码由AI Agent生成,75%的开发者已经在日常工作中使用AI编程工具。从VS Code、JetBrains到Cursor、Windsurf,再到Codex、Claude Code、Gemini CLI等Agent编码平台,软件开发正在经历范式转变。
这些工具代表了AI辅助编程的三代演进:第一代是IDE内嵌的代码补全插件(如GitHub Copilot集成到VS Code和JetBrains),主要提供行级或函数级的自动补全;第二代是以Cursor、Windsurf为代表的AI-native IDE,将AI能力深度融入编辑器的每个交互环节,支持多文件编辑和上下文感知的代码生成;第三代则是Codex、Claude Code、Gemini CLI等Agent编码平台,它们不再局限于编辑器内的辅助,而是能够自主规划任务、读写文件系统、执行终端命令、运行测试,形成完整的自主编码循环。这种演进意味着AI在软件开发中的角色正从"副驾驶"转变为"自动驾驶",对代码质量管控的要求也随之指数级提升。
但一个核心问题摆在所有人面前:你信任AI生成的代码吗?它安全吗?可维护吗?可读吗?
代码质量管理公司Sonar用4,444个Java编程任务对53+个大模型进行了系统评估,结果令人深思——那些在基准测试中表现亮眼的模型,在企业级代码质量标准下暴露了严重问题。

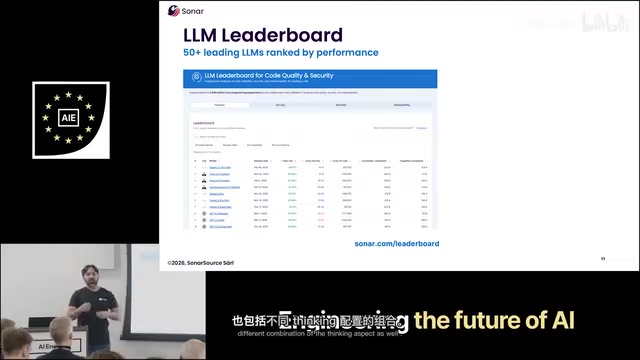
评估框架:超越功能正确性
各大LLM厂商热衷展示的HumanEval、MBPP、SWE-bench等基准测试,衡量的本质是功能正确性——代码能否通过测试用例。但企业级开发关心的远不止于此。
这些基准各有侧重:HumanEval是OpenAI在2021年发布的代码生成基准,包含164个Python编程问题,通过pass@k指标衡量模型生成正确代码的概率;MBPP(Mostly Basic Python Problems)由Google提出,包含约1000个入门级编程任务;SWE-bench则从真实GitHub仓库中提取issue和对应的pull request,要求模型在完整代码库上下文中解决实际软件工程问题,难度远高于前两者。这些基准的共同局限在于:它们只验证功能正确性,而不评估代码的安全性、可读性、可维护性等工程质量属性。
企业级开发真正关心的维度包括:
- 安全性:是否存在漏洞和安全隐患
- 可维护性:技术债务和代码复杂度
- 工程规范:架构合理性和编码纪律
- 可靠性:边界条件和异常处理
Sonar的评估框架使用SonarQube Enterprise对4,444+个独立Java编程任务的生成代码进行静态分析,覆盖bug检测、安全漏洞扫描、代码复杂度计算等多个维度。静态分析是一种不执行代码就能发现潜在问题的技术,通过解析源代码的抽象语法树(AST)、控制流图和数据流来检测bug、安全漏洞和代码异味。现代静态分析引擎综合运用了多种程序分析技术:抽象解释(Abstract Interpretation)通过在抽象域上模拟程序执行来推断变量的可能取值范围;污点分析(Taint Analysis)追踪不可信数据从输入源到敏感操作的传播路径,是检测注入类漏洞的核心技术;符号执行(Symbolic Execution)则用符号值替代具体输入来探索程序的所有可能执行路径。SonarQube在这些技术基础上构建了跨过程、跨文件的分析能力,内置数千条规则覆盖数十种编程语言,能够在代码运行之前就暴露潜在风险,包括单个函数内部分析无法发现的深层问题。
五大模型实测数据对比
Gemini 3.1 Pro High:准确率之王
- SWE-bench通过率:84.17%(排名第一)
- 代码量:307,000行
- 圈复杂度:234
- Bug密度:614个/百万行代码
- 安全问题:210个/百万行代码
Gemini表现最为均衡,代码简洁度较好,是目前综合质量最优的选择。
这里需要解释一个关键指标:圈复杂度(Cyclomatic Complexity)由Thomas McCabe在1976年提出,通过计算代码中独立执行路径的数量来量化程序复杂度——每个if、for、while、case分支都会增加复杂度值。一般认为圈复杂度超过10的函数就需要重构,超过20则几乎不可测试。Gemini的整体圈复杂度为234,分摊到4,444个任务中意味着平均每个任务的复杂度控制得相当好。
Claude Sonnet 4.6:安全风险最高
- 安全问题:300个/百万行代码(所有模型中最高)
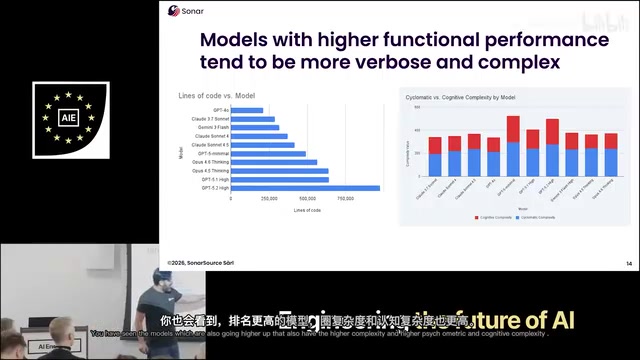
- 代码量:627,000行(高度冗余)
Claude在安全维度的表现令人担忧,同时代码膨胀严重,生成的代码量是Gemini的两倍多。
GPT-5.4 / GPT-5.4 Pro High:代码量爆炸
- 代码量:120万行(4,400个任务就产生了惊人的代码膨胀)
- 相比GPT-4.0时代的25万行,增长了近5倍
这揭示了一个反直觉的趋势:模型越新越大,生成的代码反而越臃肿。这一现象与大模型的训练策略密切相关。新一代模型通常采用更长的思维链(Chain-of-Thought)推理和更详尽的代码生成策略,倾向于生成更多的防御性代码、注释、类型检查和异常处理分支。此外,RLHF(基于人类反馈的强化学习)训练中,人类评估者往往偏好更"完整"和"详细"的回答,这种偏好被模型内化后,在代码生成场景中就表现为过度工程化(over-engineering)。代码膨胀不仅增加了维护成本,还扩大了攻击面——更多的代码意味着更多潜在的bug和安全漏洞藏身之处。
关于Bug密度指标的行业参照:Bug密度(Defect Density)是软件质量度量的核心指标之一,通常以每千行代码(KLOC)或每百万行代码的缺陷数来表示。根据行业经验数据,成熟的商业软件bug密度通常在1-25个/KLOC之间,而NASA等关键任务系统要求低于0.1个/KLOC。报告中Gemini的614个/百万行(即0.614个/KLOC)看似处于行业正常范围,但考虑到这是自动生成代码在未经人工审查前的原始质量,且这些bug可能包含安全漏洞和逻辑错误,在生产环境中的影响可能被显著放大。
四大根因分析
1. 训练数据的混合质量
训练集包含大量开源代码,其中既有高质量示例,也有大量不规范甚至有缺陷的代码。模型无法区分好坏,统统学习了进去。据估计,GitHub上公开代码中有相当比例存在已知的安全漏洞或不符合最佳实践的写法,而大模型在预训练阶段对这些代码的学习是无差别的。
2. 内置的安全缺陷
训练数据中存在已知的不安全编码模式,模型在学习功能实现的同时,也学会了这些有漏洞的写法。例如SQL注入、路径遍历、不安全的反序列化等OWASP Top 10中的经典漏洞模式,在开源代码中广泛存在,模型很容易在生成代码时复现这些反模式。OWASP(开放式Web应用安全项目)Top 10是Web应用安全领域最权威的风险清单,2021年版本涵盖了注入攻击、失效的身份认证、敏感数据暴露、XML外部实体攻击、失效的访问控制、安全配置错误、跨站脚本(XSS)、不安全的反序列化、使用含有已知漏洞的组件、以及不足的日志记录与监控等十大风险类别。AI模型在生成涉及数据库操作、用户输入处理、文件系统访问等场景的代码时,特别容易复现这些经典漏洞模式,因为训练数据中大量的教程代码和早期开源项目为了简洁性而省略了安全防护措施。
3. 隐藏的逻辑错误
训练池中存在细微的逻辑错误,导致模型在某些场景下产生看似正确实则有问题的代码——这类bug对人工审查来说极难发现。例如off-by-one错误、竞态条件、资源泄漏等问题,在代码表面看起来完全合理,只有在特定输入或并发场景下才会触发。
4. LLM的本质局限
- 概率性:同一prompt今天和明天生成不同代码
- 有限上下文:无法理解企业架构和内部代码库
- 不可解释:出错时难以诊断和改进
这些局限源于大语言模型的根本工作原理——它们本质上是基于统计概率的下一个token预测器,而非真正理解代码语义和执行逻辑的推理系统。即使是最先进的模型,也无法像人类开发者那样在脑中模拟代码执行、追踪状态变化。
LLM的概率性本质意味着即使使用完全相同的prompt,由于采样温度(temperature)、top-p截断等解码参数的影响,以及模型推理过程中的浮点运算精度差异,每次生成的代码都可能不同。这在工程实践中带来了可复现性危机:同一个bug修复请求可能产生截然不同的解决方案,使得代码审查、回归测试和问题追溯变得极其困难。一些团队尝试通过固定随机种子(seed)来获得确定性输出,但这并非所有API都支持,且在Agent多轮交互场景中几乎不可行。
趋势洞察:新模型更精细的风险
一个值得关注的发现是:随着模型迭代,总体安全漏洞数量在下降,说明厂商的强化学习确实在修复已知问题。但同时,新模型产生的bug和漏洞变得更加精细和隐蔽,属于不同类型的风险。
换言之,大模型正在从"明显的烂代码"进化为"看起来很好但藏着细微陷阱的代码"——这对人工审查提出了更高要求。这种演变类似于网络安全领域的攻防升级:当简单的攻击手段被防御后,攻击者转向更隐蔽的高级持续性威胁(APT)。在代码质量领域,这意味着传统的代码审查方式可能不再足够,需要更专业的自动化工具来辅助发现这些"高级"缺陷。
Sonar的ACDC解决方案
Sonar提出了Agent-Centric Development Cycle(ACDC)框架,包含三个阶段:
Guide阶段:治理训练数据
- Sonar Sweep:清洗和治理用于训练的数据源
- Context Augmentation:将完整代码库上下文注入LLM
技术债务(Technical Debt)这一概念由Ward Cunningham在1992年提出,用金融隐喻来描述为了短期交付速度而牺牲代码质量所积累的长期成本。SonarQube将技术债务量化为"修复时间"——即将代码恢复到合规状态所需的预估工时。在AI大规模生成代码的时代,技术债务的积累速度可能远超人工编码时期,因为AI倾向于生成冗余代码且缺乏对项目整体架构的理解,这使得Guide阶段的数据治理变得尤为关键。
Verify阶段:实时代码检测
- SonarQube Agentic Analysis:通过MCP协议集成到Claude/Codex/Gemini CLI中
- 在commit之前1-5秒内完成分析(对比CI的1-5分钟)
- 发现问题后自动推回Agent修复,再提交
MCP(Model Context Protocol)是Anthropic在2024年底开源的协议标准,旨在为AI模型提供与外部工具和数据源交互的统一接口。它采用客户端-服务器架构,允许AI Agent通过标准化的方式调用代码分析、数据库查询、文件操作等外部能力。在Sonar的应用场景中,MCP使得SonarQube的分析能力可以被Claude Code、OpenAI Codex、Gemini CLI等Agent编码工具直接调用,实现"生成-检测-修复"的闭环,而无需开发者手动切换工具或等待CI流水线。这种集成方式将质量检测从传统的"事后审查"前移到了"生成时刻",大幅缩短了反馈循环。
质量门禁(Quality Gate)是SonarQube的核心概念之一,它定义了一组代码必须满足的质量条件——例如新代码的bug数为零、安全漏洞数为零、代码覆盖率不低于80%、重复率不超过3%等。只有通过所有条件,代码才被允许合并到主分支。在传统CI/CD流水线中,质量门禁通常在代码提交后的构建阶段执行,反馈周期为分钟级。而Sonar的ACDC框架将这一检测前移到Agent生成代码的瞬间,实现了秒级反馈,这种"左移"(Shift Left)策略能够在问题产生的第一时间就将其拦截,避免缺陷在开发流程中扩散和放大。
Solve阶段:自动修复技术债
- Remediation Agent:自动修复PR中的问题,或批量处理历史技术债
- 内置验证循环:修复后重新分析+编译,确保不引入回归
对开发者的启示
- 不要盲信基准分数:84%的pass rate不代表代码可以直接用于生产
- 代码审查不可省略:AI生成代码的隐蔽bug需要更专业的工具辅助
- 选择模型要看全貌:安全性、代码量、复杂度都是关键指标
- 建立质量门禁:在AI编程流程中嵌入自动化检测环节
- 关注Sonar Leaderboard(sonar.com/leaderboard):53+模型的持续评估数据公开可查
核心要点
AI代码生成正在重塑软件开发,但"能跑通"和"能上线"之间存在巨大鸿沟。功能正确性只是代码质量的冰山一角,安全性、可维护性、工程规范才是决定代码能否在生产环境中长期运行的关键因素。开发者需要建立新的质量意识:AI是强大的编码助手,但绝不是可以免除工程纪律的银弹。在这个AI编程的新时代,自动化的质量门禁和持续的代码健康监控,将成为每个工程团队的必备基础设施。
相关推荐
UE5.8接入MCP Server完整教程:Codex插件配置详解
详细讲解Unreal Engine 5.8接入MCP Server的完整流程,涵盖UE5.8安装注意事项、VS Code Codex插件配置、API密钥设置、MCP插件启用与Server启动,帮助开发者快速搭建AI辅助开发环境。
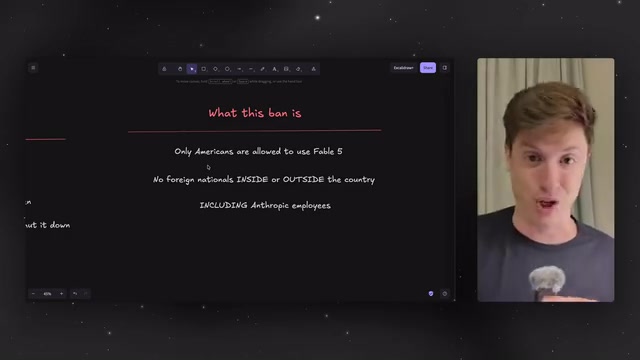
Claude Fable 5全球封禁:AI经济链条断裂危机深度解析
Claude Fable 5发布三天即遭美国政府封禁,仅限美国公民使用。深度分析越狱争议背后的真实动机、全球AI供应链断裂风险、Anthropic恐惧营销反噬,以及普通用户应对策略与本地AI部署方案。
Claude Fable 5实测:Token翻倍值不值?Rust编程对比Opus 4.8
通过Rust模拟项目实测对比Claude Fable 5与Opus 4.8的编程能力。Fable 5消耗两倍Token,输出质量仅略有提升,且存在稳定性问题。详细分析两款模型的规划、编译、功能完整性差异,帮助开发者做出合理的模型选择。