Step 3.7 Flash:198B稀疏MoE多模态模型深度解析
StepFun AI发布198B参数稀疏MoE视觉语言模型Step 3.7 Flash,专为Agent工作负载设计。
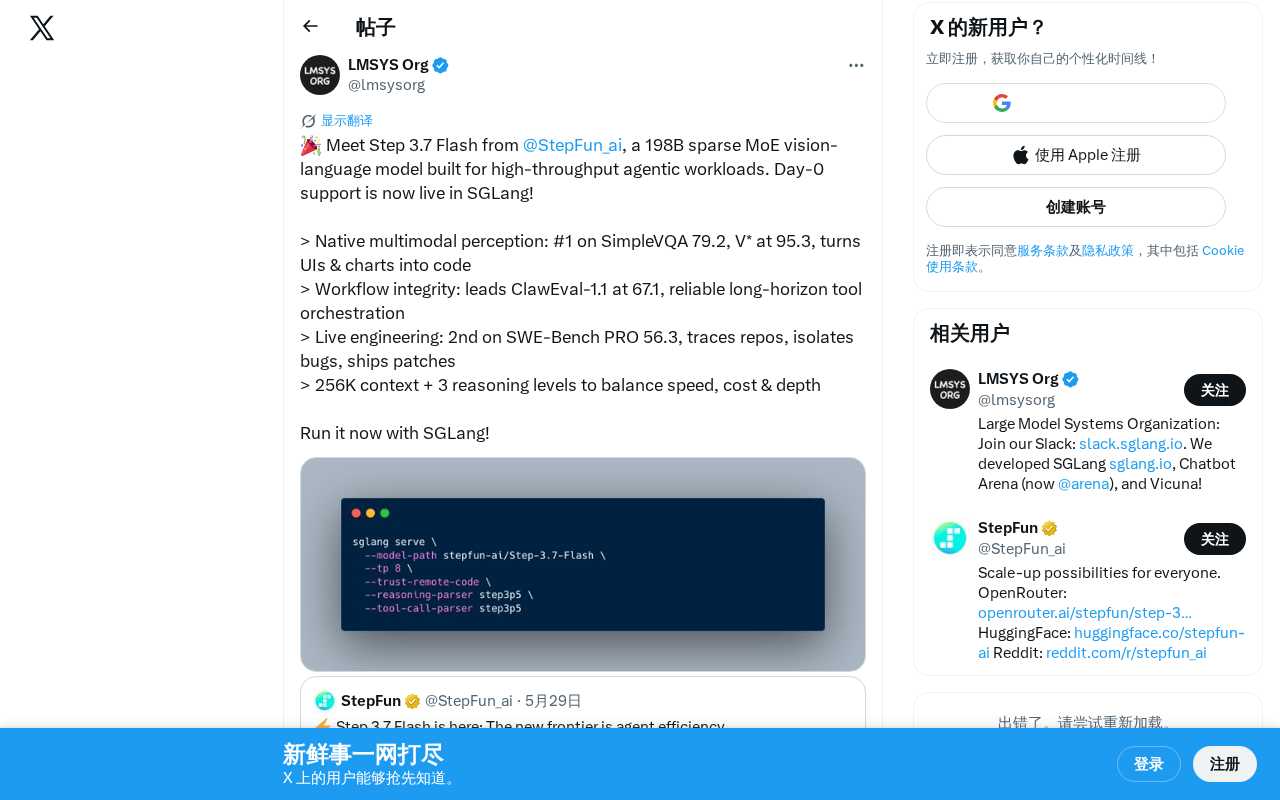
StepFun AI发布Step 3.7 Flash,一款198B参数的稀疏MoE视觉语言模型,专为高吞吐量Agent工作负载设计。该模型在多模态理解(SimpleVQA第一、V* 95.3分)、工具编排(ClawEval-1.1领先)和软件工程(SWE-Bench PRO第二)三个维度均达顶尖水平,支持256K上下文窗口和三级推理机制,已获SGLang框架首日支持。
概述
StepFun AI 正式发布了 Step 3.7 Flash,这是一款拥有 198B 参数的稀疏混合专家(Sparse MoE)视觉语言模型,专为高吞吐量的智能体(Agentic)工作负载而设计。该模型已在 SGLang 框架上获得首日支持,开发者可以立即部署使用。
核心能力解析
原生多模态感知能力
Step 3.7 Flash 在多模态理解方面表现出色。在 SimpleVQA 基准测试中以 79.2 分拿下第一,在 V* 测试中更是达到了 95.3 的高分。
关于这两项基准测试:SimpleVQA 是视觉问答(Visual Question Answering)领域的标准化测试集,评估模型对图像内容的精准理解能力,涵盖物体识别、场景理解、空间关系推断等多个维度;V* 基准则专注于视觉定位与细粒度感知,测试模型在复杂视觉场景中的精确识别能力,对多模态模型的底层视觉编码器质量要求极高。在这两项测试中同时达到顶尖水平,意味着 Step 3.7 Flash 具备从宏观场景理解到微观细节识别的全面视觉感知能力。
这意味着该模型能够精准理解图像内容,并将 UI 界面和图表直接转化为代码——这对于自动化工作流和智能体应用来说至关重要。将视觉信息直接转化为可执行代码的能力,让 Step 3.7 Flash 在前端开发辅助、数据可视化逆向工程等场景中具备明显优势。
工作流完整性与工具编排
在复杂工作流执行方面,Step 3.7 Flash 在 ClawEval-1.1 基准测试中以 67.1 分领先,展现了可靠的长程工具编排能力。
ClawEval 的评测逻辑:ClawEval 是专为 AI Agent 设计的工具调用评估框架,模拟真实的多步骤任务执行场景,重点考察模型在工具链编排中的可靠性和错误恢复能力。与简单的单次工具调用测试不同,ClawEval 要求模型在动态变化的任务环境中持续做出正确决策——包括何时调用哪个工具、如何处理工具返回的异常结果、以及如何在多个并行子任务之间协调资源。这一指标衡量的是模型在多步骤、多工具调用场景下的执行可靠性,对于构建生产级 AI Agent 来说是核心考量。
长程工具编排意味着模型能够在复杂任务中保持上下文一致性,按照正确的顺序调用不同工具,并在出现异常时进行合理的错误处理。这也是当前 AI Agent 领域最具挑战性的能力之一。
实时软件工程能力
在 SWE-Bench PRO 基准测试中,Step 3.7 Flash 以 56.3 分排名第二,展现了扎实的实际工程能力。
SWE-Bench PRO 的行业地位:SWE-Bench PRO 是软件工程领域最权威的评测基准之一,基于真实 GitHub Issue 和开源代码仓库构建,要求模型完成端到端的 Bug 定位与修复全流程——从理解问题描述、检索相关代码文件,到生成可通过单元测试的修复补丁。与合成数据集不同,SWE-Bench PRO 中的每一个任务都来自真实的软件开发场景,被业界视为衡量 AI 编程助手实际工程能力的黄金标准。56.3 分的成绩意味着模型能够独立解决超过一半的真实软件缺陷,这在当前技术水平下已属顶尖水准。
它能够追踪代码仓库结构、定位 Bug 并生成修复补丁,使其成为软件开发领域中极具竞争力的 AI 编程助手。
架构设计亮点
稀疏MoE架构的效率优势
198B 的总参数量采用稀疏混合专家架构,推理时只有部分专家被激活,从而在保持模型容量的同时大幅降低计算成本。
稀疏 MoE 的技术原理:稀疏混合专家(Sparse Mixture of Experts)架构源自 2017 年 Google Brain 的开创性论文,其核心思想是将模型分割为多个独立的"专家"子网络,并通过一个轻量级的门控网络(Gating Network)动态决定每个输入 token 应激活哪些专家。在推理时,通常只有 Top-K 个专家(如 Top-2)被激活,使得实际计算量远小于总参数量——对于 198B 总参数的模型,实际激活参数量可能仅为 20-40B 量级。这一架构已被 Mistral 的 Mixtral 系列、Google 的 Gemini 1.5 以及 DeepSeek-V2 等顶尖模型广泛验证,成为大规模语言模型兼顾能力与效率的主流技术路线。
这种设计特别适合高吞吐量场景,能够在有限的计算资源下服务更多并发请求。与同等参数规模的稠密模型相比,稀疏 MoE 架构在推理延迟和显存占用方面都有显著优势,这也是 Step 3.7 Flash 名称中 "Flash" 的由来——追求速度与效率的平衡。
256K上下文窗口与三级推理
Step 3.7 Flash 支持 256K 的超长上下文窗口,能够处理大规模文档和完整代码库。
超长上下文的技术意义:传统 Transformer 架构的注意力机制计算复杂度为 O(n²),随序列长度增加显存消耗急剧膨胀,这使得早期模型的上下文窗口普遍限制在 4K-8K token。为突破这一瓶颈,业界发展出 RoPE 位置编码外推、滑动窗口注意力、FlashAttention 等多项关键技术。256K 上下文窗口(约等于 20 万汉字或 50 万英文单词)意味着模型可以一次性处理完整的中型代码库、数百页技术文档或长达数小时的对话历史,这对于需要全局代码理解的软件工程任务和需要持续记忆的 Agent 应用场景具有决定性意义。
更值得关注的是其三级推理(3 reasoning levels)设计,允许用户根据任务复杂度在速度、成本和推理深度之间灵活权衡。这种分级推理机制在实际部署中非常实用:简单查询使用轻量级推理获得最快响应,复杂任务则启用深度推理确保准确性。对于需要控制推理成本的团队来说,这一特性提供了精细化的资源管理手段。
部署与生态支持
SGLang 作为高性能 LLM 推理框架,已提供对 Step 3.7 Flash 的首日原生支持。
SGLang 框架的技术优势:SGLang(Structured Generation Language)是由加州大学伯克利分校研究团队开发的高性能 LLM 推理框架,专为结构化生成和复杂推理任务优化。相比 vLLM 等主流推理框架,SGLang 引入了 RadixAttention 技术,通过 KV 缓存的前缀共享机制大幅提升多轮对话和 Agent 场景下的吞吐量,在某些基准测试中推理速度可提升 2-5 倍。SGLang 还原生支持函数调用、JSON 结构化输出和多模态输入,使其特别适合构建生产级 AI Agent 系统。首日支持意味着模型发布与框架适配同步完成,开发者无需等待社区适配即可在生产环境中使用。
开发者可以直接通过 SGLang 部署和调用该模型,享受其优化的推理性能和灵活的调度能力。对于已经在使用 SGLang 的团队,集成成本极低。
竞争格局分析
Step 3.7 Flash 的发布进一步加剧了大模型领域的竞争。在多模态理解、代码生成和 Agent 工具调用三个维度上同时达到顶尖水平,使其成为 GPT-4o、Claude Sonnet 等模型的有力竞争者。
AI Agent 赛道的竞争背景:AI Agent 工作负载是当前大模型应用落地的核心范式,指能够自主规划、调用外部工具并完成多步骤复杂任务的 AI 系统。与传统的单次问答不同,Agent 工作负载具有工具调用密集、长程依赖强、并发需求高三个显著特征,对模型的推理速度、工具调用准确性和长上下文处理能力提出了远高于普通对话场景的要求。目前,OpenAI、Anthropic、Google 等头部厂商均在 Agent 能力上持续投入,这一细分赛道已成为大模型商业化竞争的核心战场。Step 3.7 Flash 专门针对 Agent 工作负载进行架构优化,有望在这一高价值场景中建立差异化竞争优势。
对于需要构建复杂 AI Agent 系统的开发者而言,Step 3.7 Flash 提供了一个兼具多模态理解、长上下文处理和可靠工具调用的统一解决方案,值得重点关注和评估。
核心要点
- Step 3.7 Flash 是 198B 参数的稀疏 MoE 视觉语言模型,专为高吞吐量 Agent 工作负载设计
- 在 SimpleVQA(79.2 分第一)、V*(95.3 分)等多模态基准测试中表现顶尖
- ClawEval-1.1 以 67.1 分领先,展现可靠的长程工具编排能力
- SWE-Bench PRO 排名第二(56.3 分),具备追踪代码库、定位 Bug 和生成补丁的工程能力
- 支持 256K 上下文窗口和三级推理机制,可灵活平衡速度、成本与推理深度
- 已获 SGLang 框架首日原生支持,具备开箱即用的生产部署能力
相关推荐
 科技前沿
科技前沿GitHub Agent HQ发布:AI编程工具进入平台化竞争时代
GitHub Universe大会发布Agent HQ平台,统一管理编码Agent,Copilot升级支持多模型集成。同期OpenAI完成重组,Anthropic新模型测试,NVIDIA开源系列AI模型,AI编程工具格局加速整合。
 科技前沿
科技前沿Gemini 3.5 Flash在GDPval基准上实现巨大飞跃
Google Gemini 3.5 Flash在GDPval基准测试中超越Gemini 3.1 Pro,轻量级Flash模型借助后训练技术逼近前沿水平,重新定义性能与成本的平衡点,为AI应用开发者带来重大利好。
 科技前沿
科技前沿Google Gemini Antigravity周配额三倍提升,AI编程不再受限
Google Gemini团队再次将Antigravity周配额提升至三倍,继日配额提升后再次加码。本文解析此次配额调整对开发者的实际影响,以及在AI编程助手竞争格局中的战略意义。