VSCode中为Copilot接入DeepSeek V4 API:两种方法详细教程
为什么要给Copilot接入自定义API?
GitHub Copilot作为VSCode中默认的AI编程助手,使用体验一直不错。但近期Copilot调整了套餐策略,大幅削减了各模型的token限额,这让不少开发者感到不满。
GitHub Copilot自2022年正式发布以来,经历了从单一模型到多模型支持的演进。2024年底至2025年初,GitHub对Copilot的订阅体系进行了重大调整,推出了Free、Pro、Pro+和Enterprise等多个层级。其中争议最大的是对高级模型(如Claude 3.5 Sonnet、GPT-4o等)施加了严格的每日/每月请求次数和token用量限制。Pro用户每月仅有有限的高级模型配额,超出后会自动降级到基础模型。这一变化促使许多开发者寻找替代方案,通过接入第三方API来绕过这些限制。
这一定价策略的调整并非孤立事件,它反映了AI编程工具市场从增长期进入变现期的行业趋势。2024年,GitHub母公司微软的财报显示Copilot的运营成本远高于订阅收入,单用户月均推理成本一度超过80美元,而个人订阅仅为10美元/月。这种成本倒挂促使GitHub不得不通过分层限额来控制开支。类似的趋势也出现在Cursor、Windsurf等竞品中,基于用量的分级定价正在成为行业常态。
话说回来,DeepSeek V4 Pro凭借强大的代码能力和高达100万token的上下文窗口,成为许多开发者的首选模型。DeepSeek V4是深度求索(DeepSeek)于2025年推出的新一代大语言模型,其Pro版本采用了混合专家架构(MoE),在代码生成、数学推理和长文本理解方面表现突出。
所谓混合专家架构,是指将模型分为多个"专家"子网络,每次推理只激活其中一小部分(通常10-20%)。这意味着模型可以拥有数万亿级别的总参数量来存储知识,但单次推理的计算成本仅相当于一个小得多的模型。DeepSeek V4 Pro据报道总参数量超过6000亿,但激活参数仅约370亿,这使其在保持顶级性能的同时将推理成本降至GPT-4级别模型的数分之一——这也是DeepSeek API定价远低于OpenAI的技术基础。
100万token的上下文窗口意味着模型可以一次性处理约75万个英文单词或约50万个中文字符的内容,足以覆盖大多数中大型软件项目的完整代码库。在实际编程场景中,一个典型的中型Python项目(如Django Web应用)可能包含200-500个文件,总代码量在10万-50万行之间,折算约需200K-1M token。128K的上下文窗口大约能容纳4万行代码,对于分析跨模块的依赖关系往往捉襟见肘。而100万token的窗口则能覆盖绝大多数项目的完整代码库,使模型能够进行真正的全局代码理解和重构建议。相比之下,GPT-4o的上下文窗口为128K,Claude 3.5为200K,DeepSeek V4的百万级上下文在处理跨文件依赖分析、大规模代码重构等场景时具有显著优势。
那么问题来了:能不能继续使用熟悉的Copilot界面,同时接入DeepSeek V4的API呢?答案是肯定的。下面介绍两种方法,帮你在VSCode中为GitHub Copilot接入DeepSeek V4以及任意主流模型的API。
准备工作:获取DeepSeek API Key
无论使用哪种方法,第一步都是获取DeepSeek的API Key。登录DeepSeek开放平台,在API管理页面创建一个新的Key即可。
注意事项:
- API Key属于敏感信息,切勿分享给他人
- 创建后请立即复制保存,部分平台只显示一次
- DeepSeek的API费用相对低廉,充值少量即可开始使用
方法一:DeepSeek for Copilot插件(2分钟快速配置)
这是最简单快捷的方案,适合不需要太多自定义配置的用户。
安装与配置步骤
- 打开VSCode的插件市场,搜索"DeepSeek",找到DeepSeek for Copilot插件并安装
- 安装完成后,按下快捷键
Ctrl+Shift+P,在命令面板中按提示输入你的API Key - 在Copilot的模型选择中,点击"其他模型" → "管理模型",即可找到DeepSeek V4 Pro和Flash版本
可调参数
该插件仅提供两个可调参数:
- Thinking Effort:思维深度,可选High或Max
- Temperature:温度参数,控制输出的随机性
方法一的局限性
这个插件最大的缺点是上下文窗口仅为128K(约13万token),而DeepSeek V4 Pro原生支持100万token的上下文。128K与100万之间差了约7.5倍,对于需要处理大型项目的开发者来说,这个限制相当致命。
如果你需要充分利用DeepSeek V4的百万级上下文能力,建议使用方法二。
方法二:OAI插件(完全自定义配置)
OAI插件提供了丰富的个性化配置选项,支持自定义上下文长度、思考深度等参数,是更推荐的方案。
安装OAI插件
在VSCode插件市场搜索"OAI",找到对应插件并安装。插件的README文件为英文,可以点击其中的Quick Start链接跳转到浏览器查看,配合翻译插件阅读更方便。
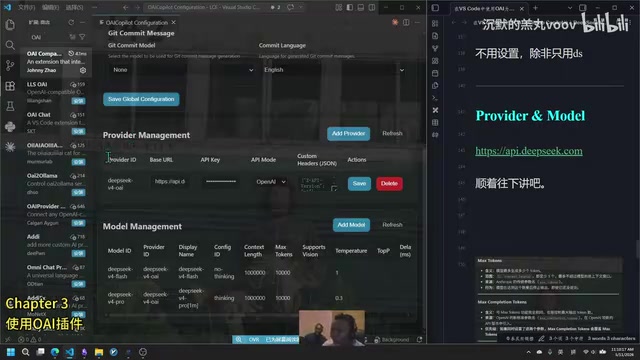
配置Provider(API供应商)
在VSCode命令面板中输入OAI configuration,进入配置界面。
全局设置部分:
- Global Base URL:可以填写
https://api.deepseek.com,但如果你将来还想接入其他模型的API,建议留空 - 允许重试:建议开启,最大尝试次数设为3
- 其他全局设置保持默认即可
新建Provider:
- 创建一个新的Provider,输入ID(如"DS-TEST")
- URL填写:
https://api.deepseek.com - 粘贴你的API Key
- API Mode选择OpenAI
- 保存
这里的API Mode选择"OpenAI",指的是采用OpenAI定义的Chat Completions API标准格式进行通信。这一格式已成为大模型API的事实标准,包括DeepSeek、Moonshot、通义千问等国内外众多模型提供商都兼容这一接口规范。其核心是通过HTTP POST请求向/v1/chat/completions端点发送JSON格式的消息数组(包含system、user、assistant等角色),服务端返回模型生成的回复。
这一标准之所以能获得如此广泛的采用,与OpenAI的先发优势和开发者生态密切相关。自2023年GPT-3.5 API发布以来,数以万计的应用、框架和工具都基于这一格式构建。LangChain、LlamaIndex等主流AI开发框架默认支持该格式,使得任何兼容此标准的模型都能即插即用地接入现有生态。这种网络效应反过来又迫使后来的模型提供商主动兼容,形成了正向循环。对开发者而言,这种标准化意味着只要模型提供商兼容OpenAI格式,你就可以通过修改Base URL和API Key来无缝切换不同的模型服务,无需更改客户端代码逻辑。
配置Model(模型参数)
新建一个Model,选择刚才创建的Provider,然后进行以下关键参数配置:
上下文长度: 默认128K,可以直接改为1000000(100万),充分发挥DeepSeek V4的能力。
最大输出Token数: 这里有两个选项需要注意:
max_tokens:Anthropic旧版API的参数格式max_completion_tokens:OpenAI新标准参数格式
两者只需设置一个即可。如果两个都设置了,系统会优先使用max_completion_tokens。建议设置为10000左右,DeepSeek V4最大支持384K输出。
这两个参数的区别源于API规范的演进历史。max_tokens是早期OpenAI和Anthropic API中用于限制模型单次回复最大长度的参数。随着推理模型(如o1、o3)的出现,模型的输出包含了"思考过程"(reasoning tokens)和"最终回复"两部分。OpenAI在2024年引入了max_completion_tokens参数,它涵盖了思考token和回复token的总和,更准确地反映了实际的token消耗。对于支持深度思考的模型如DeepSeek V4,使用max_completion_tokens能更精确地控制总输出量,避免因思考过程过长而导致最终回复被截断。
Temperature(温度参数): 这是一个容易被忽略但非常重要的参数。
| 温度值 | 特点 | 适用场景 |
|---|---|---|
| 低(0~0.5) | 确定性高,输出稳定 | 代码修改、精确计划 |
| 中(0.5~1.0) | 平衡创造性与准确性 | 通用任务 |
| 高(1.0~2.0) | 创造性强,输出多样 | 文学创作、头脑风暴 |
简单理解:温度越高,模型越"奔放",输出的不确定性和创造性越强;温度越低,输出越"稳重",确定性越高。编程场景建议设置较低值。
从技术层面来看,Temperature参数直接影响模型输出概率分布的"锐度"。大语言模型在生成每个token时,会为词表中所有可能的下一个token计算一个logit分数,然后通过softmax函数将其转换为概率分布。Temperature作为softmax函数的除数:当T=1时,使用原始概率分布;当T<1时,概率分布变得更"尖锐",高概率token的优势被放大,模型倾向于选择最可能的token;当T>1时,分布变得更"平坦",低概率token也有更多机会被选中。在编程场景中,T=0或接近0意味着模型几乎总是选择最高概率的token,生成的代码更符合常见模式和最佳实践,但也可能缺乏针对特定场景的创新性解法。
高级设置
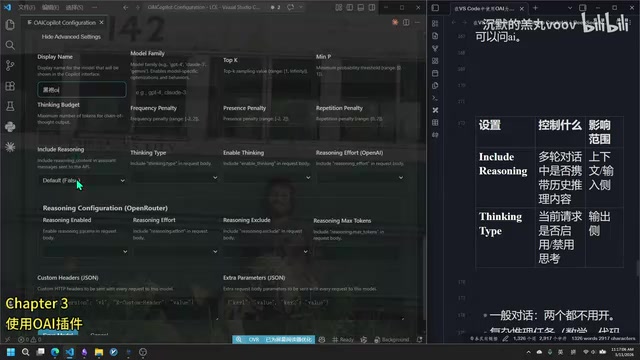
进入模型的进一步设置:
- Display Name:显示名称,不要使用中文,否则可能出现兼容性问题
- Configure ID:配置备注,如"thinking"或"no-thinking",方便区分不同配置
- Include Reasoning:建议开启,可以携带历史推理内容回传给API
- Enable Thinking:是否允许模型进行深度思考,写代码时强烈建议开启
- Reasoning Effort:思考深度,可选minimal/low/medium/high/max,推荐选择high
Enable Thinking(深度思考)功能源自Chain-of-Thought(思维链)推理技术。当开启此功能时,模型在生成最终答案之前,会先进行一段内部推理过程——分析问题、拆解步骤、考虑边界情况、验证逻辑。这段推理内容通常会以特殊标记返回给用户(在界面上显示为可折叠的"思考过程")。对于编程任务,思考模式能显著提升代码的正确性和完整性,因为模型会在生成代码前先理清算法逻辑、考虑异常处理、规划代码结构。
Reasoning Effort参数则控制模型投入多少计算资源进行思考——high级别会进行更深入的多步推理,适合复杂的架构设计和算法实现;而minimal级别则快速给出答案,适合简单的代码补全。值得注意的是,更高的思考深度意味着更多的token消耗和更长的响应时间,这是一个质量与效率之间的权衡。在实际使用中,你可以为同一个模型创建多个配置(如"thinking-high"和"no-thinking"),在不同任务场景间灵活切换。
最后选择Model ID为deepseek-v4的Pro或Flash版本,点击Save Model即可。
验证配置是否成功
配置完成后,在Copilot的模型选择中找到你刚才设置的Display Name对应的模型。发送一条消息测试,确认Agent显示为GitHub Copilot、Model显示为你配置的名称,即表示配置成功。
两种方法对比总结
| 对比项 | 方法一(DeepSeek for Copilot) | 方法二(OAI插件) |
|---|---|---|
| 配置时间 | 约2分钟 | 约5分钟 |
| 上下文窗口 | 128K(固定) | 最高100万(可自定义) |
| 可调参数 | 2个 | 丰富(温度、思考深度等) |
| 多模型支持 | 仅DeepSeek | 任意OpenAI兼容API |
| 推荐场景 | 快速体验 | 日常开发使用 |
对于日常编程开发,方法二的OAI插件无疑是更优选择。100万token的上下文窗口意味着你可以让模型理解整个项目的代码结构,而丰富的参数配置则能让你针对不同任务场景进行精细调优。
注意事项
- 设置参数时不要超过DeepSeek官方文档标注的上限(如上下文最大100万、输出最大384K),否则可能报错
- Display Name避免使用中文字符,以免出现兼容性问题
- 建议参考DeepSeek官方API文档确认各参数的有效范围
- 使用自己的API Key意味着费用由你自己承担,但DeepSeek的定价相当亲民
核心要点
本文介绍了在VSCode中为GitHub Copilot接入DeepSeek V4自定义API的两种方法。方法一通过DeepSeek for Copilot插件实现2分钟快速配置,但上下文窗口被限制在128K。方法二通过OAI插件提供完全自定义的配置能力,支持100万token上下文、可调温度参数、深度思考模式等高级功能,是日常开发的推荐选择。无论选择哪种方法,核心思路都是利用OpenAI兼容的API标准格式,将第三方模型无缝接入Copilot的交互界面。
相关推荐

DeepSeek研究员总结AI智能体使用十大法则
DeepSeek研究员基于AI研究和自主编程实战经验,总结AI智能体(AI Agent)使用的10条通用法则,涵盖角色转变、判断力瓶颈、记忆文件系统、人机协作边界等关键洞察,帮助你高效驾驭AI工具而非被工具掌控。
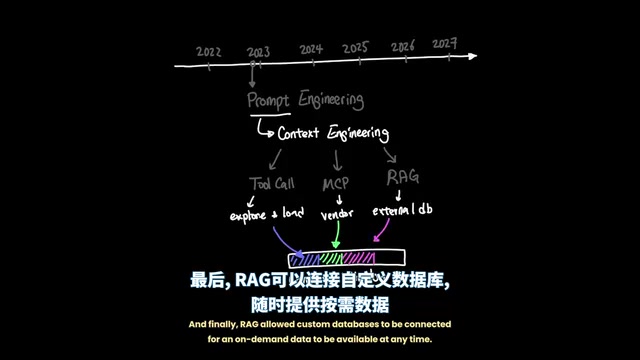
Agent Harness:从提示词工程到执行环境编排的AI代理新范式
深入解析Agent Harness Engineering的核心理念,了解它如何通过循环执行与上下文隔离突破传统提示词工程和上下文工程的瓶颈,以及在Cursor等现代编程代理中的实践应用。
DeepSeek V4 Flash免费使用教程:Cherry Studio与CC Switch配置指南
DeepSeek V4 Flash限时免费,输入输出token零计费。本文详解OpenModel平台注册流程,以及在Cherry Studio和CC Switch中的完整配置方法,附模型映射与使用场景推荐。