Vue3+SpringBoot实战:AI旅游推荐助手全栈项目详解
项目概述:一个适合入门的AI全栈实战项目
随着AI技术的快速渗透,企业对"全栈+AI"复合型人才的需求持续增长。这一趋势源于两个方向的交汇:一是前后端分离架构的成熟使得全栈开发成为中小团队的刚需,二是大模型API的平民化(如OpenAI、百度文心、阿里通义等提供标准化API)使得AI能力集成的门槛大幅降低。据多家招聘平台数据显示,2024年标注"AI"关键词的全栈岗位薪资溢价约20%-40%。这意味着开发者不再需要深入理解模型训练和微调,只需掌握API对接、Prompt设计和工程化集成能力,就能在简历上体现AI项目经验。
B站UP主Alan老师分享了一个面向零基础学习者的全栈实战项目——旅游景点智能推荐助手,采用 Vue3 + Java SpringBoot 技术栈,结合AI大模型能力,打造了一个具备智能行程规划和AI对话功能的H5应用。
这个项目的定位非常明确:帮助前端开发者学习Java转全栈,或后端开发者学习前端转全栈,同时积累AI项目经验。对于正在寻找简历项目的同学来说,这是一个值得参考的实战案例。
核心功能解析:智能推荐与AI对话
智能旅游行程规划
项目首页是一个旅游智能助手界面,用户输入目的地城市、旅行天数和预算等参数后,系统将这些信息传递给后端AI大模型进行处理,自动生成详细的旅游行程安排。
举个例子,用户选择"北京"作为目的地,AI会根据天数和预算约束,规划出每天的景点路线、餐饮建议和时间安排。这个功能背后涉及前端表单交互、后端API设计以及AI大模型的Prompt工程,是一个很好的端到端学习案例。
这里值得深入了解的是 Prompt工程(Prompt Engineering)的核心原理。Prompt工程是指通过精心设计输入给大语言模型的提示词,来引导模型生成高质量、符合预期的输出。在旅游行程规划场景中,一个好的 Prompt 需要包含明确的角色设定(如"你是一位专业的旅游规划师")、结构化的输入参数(目的地、天数、预算)、输出格式要求(如 JSON 格式或分天列表)以及约束条件(如预算限制、景点开放时间)。常见的 Prompt 技巧包括 Few-shot Learning(提供几个示例让模型学习输出模式)、Chain of Thought(引导模型逐步推理)、以及 System Prompt 与 User Prompt 的分层设计。Prompt 的质量直接决定了 AI 功能的用户体验,微小的措辞调整可能导致输出结果的巨大差异,因此 Prompt 调优是 AI 应用开发中不可忽视的核心环节。
AI对话交互功能
项目的第二个核心功能是AI对话页面,用户可以像使用ChatGPT一样,直接向AI提问旅游相关的问题。比如输入"北京有哪些必去的景点",AI大模型会返回结构化的推荐内容。
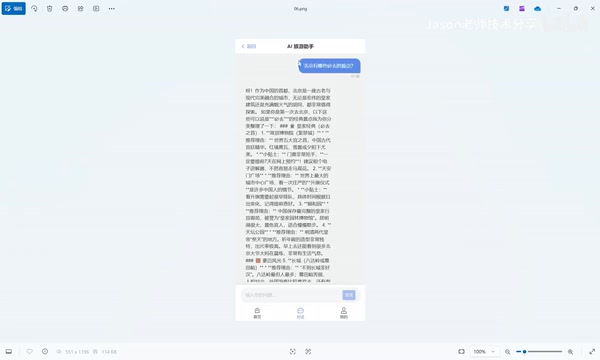
这个功能的实现涉及前后端的实时通信、大模型API的对接调用,以及对话上下文的管理。在实时通信技术的选择上,AI对话场景有其特殊性:传统的HTTP轮询效率低下,WebSocket虽然提供全双工通信但实现成本较高,而 Server-Sent Events(SSE) 是单向服务端推送协议,实现成本低且天然支持HTTP/2,特别适合大模型流式输出这种"用户发送一条消息,服务端持续返回生成内容"的单向流模式。大多数AI对话应用(包括ChatGPT)正是采用SSE方案来实现打字机效果。
对话上下文管理也是一个关键的技术挑战。大语言模型本身是无状态的——每次API调用都是独立的,模型并不"记住"之前的对话。实现多轮对话的常见做法是将历史对话记录(包括用户消息和AI回复)作为messages数组完整传入每次API请求。但这带来了Token消耗快速增长的问题:以GPT-4的128K Token上下文窗口为例,每次请求都需要重传全部历史。工程上的优化策略包括:滑动窗口(只保留最近N轮对话)、摘要压缩(用模型将历史对话压缩为摘要)、以及关键信息提取(只保留与当前话题相关的历史片段)。
对于想了解 AI Agent 开发模式的同学来说,这是一个非常直观的入门场景。
AI Agent(智能体)是当前大模型应用开发的核心范式之一,它超越了简单的"输入-输出"问答模式。一个 Agent 通常由大语言模型作为"大脑",配合感知模块(接收用户输入)、规划模块(分解任务步骤)、记忆模块(维护对话历史和上下文)以及工具调用模块(如搜索引擎、数据库查询、API 调用)组成。在本项目中,旅游推荐助手可以视为一个轻量级 Agent:它接收用户的旅行需求,调用大模型进行行程规划(规划能力),并在对话中保持上下文连贯性(记忆能力)。更复杂的 Agent 架构如 ReAct(Reasoning + Acting)模式,允许模型在推理过程中主动调用外部工具获取实时信息,例如查询实时天气、景点门票价格等,从而生成更准确、更实用的推荐结果。
个人中心模块
项目还包含一个"我的"页面,用于用户信息管理。虽然功能相对简单,但它完善了整个应用的用户体系,让项目更接近真实的企业级产品形态。
技术栈与架构详解
前端技术:Vue3生态
前端采用 Vue3 框架开发,这是目前国内前端开发的主流选择。Vue3 相比 Vue2 在性能、TypeScript支持和 Composition API 等方面都有显著提升,也是企业招聘中高频要求的技能点。整个项目以H5移动端页面为主,适合快速上手移动端开发。
选择H5移动端页面而非原生App开发,体现了当前轻量级应用的主流趋势。H5应用基于Web技术栈,具备跨平台、免安装、易分发的优势,特别适合工具类和内容类产品的MVP验证。在移动端H5开发中,还需要关注视口适配(viewport meta标签配置)、rem/vw等响应式单位、移动端触摸事件处理、以及iOS/Android浏览器的兼容性差异等问题。
深入来看,Vue3 的 Composition API 是相对于 Vue2 Options API 的一次重大范式转变。Options API 按照 data、methods、computed 等选项组织代码,当组件逻辑复杂时,同一功能的代码会分散在不同选项中,维护困难。Composition API 允许开发者按照逻辑关注点组织代码,通过 setup() 函数或 <script setup> 语法糖,将相关的响应式状态、计算属性和方法聚合在一起,极大提升了代码的可读性和复用性。此外,Vue3 底层采用 Proxy 替代 Vue2 的 Object.defineProperty 实现响应式系统,解决了无法检测对象属性新增/删除、数组索引变化等历史痛点,性能也有显著提升。配合 Vite 构建工具的即时热更新能力,开发体验得到了质的飞跃。
Vite 是 Vue3 官方推荐的构建工具,由 Vue 作者尤雨溪开发。它在开发模式下利用浏览器原生 ES Module 支持,无需像 Webpack 那样在启动时打包整个项目,而是按需编译请求的模块,实现毫秒级的冷启动。在生产构建时,Vite 底层使用 Rollup 进行高效的 Tree-shaking 和代码分割。相比 Webpack 动辄数十秒的启动时间,Vite 的即时启动和热更新能力将开发反馈循环缩短到几乎无感知的程度,这对全栈开发者同时调试前后端代码尤为重要。
后端技术:Java SpringBoot
Java SpringBoot 作为后端框架,负责API接口开发、业务逻辑处理以及与AI大模型的对接。SpringBoot 的自动配置和快速启动特性降低了后端开发的门槛,非常适合全栈项目的后端部分。
SpringBoot 的核心设计哲学是 "约定优于配置"(Convention over Configuration)。它通过 @EnableAutoConfiguration 注解和 spring.factories 机制,在应用启动时自动扫描 classpath 下的依赖库,根据条件注解(如 @ConditionalOnClass、@ConditionalOnMissingBean)智能决定哪些 Bean 需要自动创建和注入。例如,当检测到 classpath 中存在 H2 数据库驱动时,SpringBoot 会自动配置内存数据库连接,无需手动编写 XML 配置文件。这种机制将传统 Spring 项目中大量的样板配置代码压缩到几乎为零,开发者只需在 application.yml 中做少量自定义配置即可启动一个功能完备的 Web 服务。对于全栈项目而言,这意味着后端开发者可以将更多精力放在业务逻辑和 AI 集成上,而非基础设施搭建。
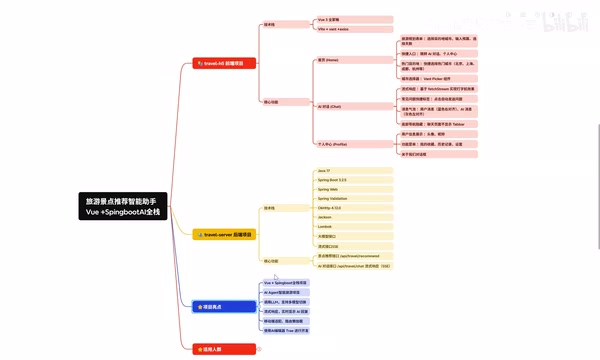
AI大模型集成方案
项目的最大亮点在于AI Agent的集成。通过后端与大模型API的对接,实现了智能推荐和对话两大AI功能。这种"传统全栈+AI能力"的技术组合,正是当前市场上比较紧缺的技术方向。
在大模型 API 的对接中,流式响应(Streaming Response)是提升用户体验的关键技术。传统的 HTTP 请求-响应模式需要等待大模型完整生成所有内容后才返回,用户可能需要等待数秒甚至十几秒才能看到结果。流式响应基于 Server-Sent Events(SSE)或 WebSocket 协议,允许服务端将大模型逐 Token 生成的内容实时推送给前端,用户可以看到文字像打字机一样逐步显示,这正是 ChatGPT 的交互体验。在技术实现上,前端需要使用 EventSource API 或 fetch 的 ReadableStream 来处理流式数据,后端则需要将大模型 SDK 的流式回调转发为 SSE 事件流。Token 管理也是重要考量——每次 API 调用都会消耗 Token(大模型的计费单位,通常1个Token约等于0.75个英文单词或0.5个中文字符),需要在后端实现 Token 用量统计、速率限制和成本控制机制。
适合人群与学习价值分析

三类目标学习者
- 零基础入门者:刚学完一门编程语言基础,想通过完整项目巩固知识并接触AI开发
- 前端转全栈开发者:有Vue等前端经验,想学习Java后端开发,补齐全栈能力
- 后端转全栈开发者:有Java后端经验,想学习Vue3前端开发,实现全栈覆盖
为什么说这个项目能给简历加分
从项目经验的角度来看,这个项目至少覆盖了三个面试加分点:
- 全栈开发能力:Vue3 + SpringBoot 前后端技术栈
- AI项目经验:大模型对接与Agent开发实践
- 完整的产品思维:从需求分析到功能实现的完整闭环
在当前就业市场中,AI相关项目经验已经成为越来越多岗位的加分甚至必备条件。
项目配套资源说明
该项目提供了完整的开发文档,涵盖项目描述、环境配置、前后端技术栈说明,以及重点代码的详细讲解。整个教学过程采用手把手的方式,有效降低了学习曲线。
总结:快速入门全栈+AI开发的高性价比项目
这个AI旅游推荐助手项目虽然功能体量不大,但"麻雀虽小,五脏俱全"。它覆盖了全栈开发的核心链路:
前端页面交互 → 后端API处理 → AI大模型调用 → 结果渲染展示
对于想快速入门全栈+AI开发的同学来说,是一个投入产出比很高的学习项目。
不过需要注意的是,企业级AI项目通常还涉及更复杂的架构设计,比如流式响应、Token管理、多轮对话记忆、向量数据库检索等。
其中,向量数据库检索是 RAG(Retrieval-Augmented Generation,检索增强生成)架构的核心组件,值得进一步了解。大语言模型的知识截止于训练数据的时间点,且无法直接访问企业私有数据。RAG 通过在模型推理前,先从外部知识库中检索与用户问题相关的文档片段,将其作为上下文注入 Prompt,从而让模型基于最新、最相关的信息生成回答。向量数据库(如 Milvus、Pinecone、ChromaDB)的作用是存储文本经过 Embedding 模型转化后的高维向量表示,并支持高效的相似度检索。
从技术原理来看,Embedding 模型(如 OpenAI 的 text-embedding-ada-002、BGE 等)将文本转化为高维浮点数向量(通常768或1536维),语义相近的文本在向量空间中距离更近。相似度检索通常使用余弦相似度(Cosine Similarity)或内积(Inner Product)作为度量标准。向量数据库通过 HNSW(Hierarchical Navigable Small World)、IVF(Inverted File Index)等近似最近邻(ANN)算法,在百万甚至亿级向量中实现毫秒级检索。这种语义检索能力远超传统关键词匹配——例如用户搜索"适合带小孩玩的地方",即使文档中没有完全匹配的关键词,只要语义相关(如"亲子乐园""儿童友好景区"),也能被准确检索到。
在旅游场景中,可以将景点介绍、用户评价、实时攻略等数据向量化存入数据库,当用户提问时,系统先检索最相关的信息片段,再交给大模型生成个性化推荐,显著提升回答的准确性和时效性。
建议在完成本项目后,可以进一步深入这些方向,提升项目的技术深度和简历的竞争力。
相关推荐
一句话提示词生成10款网页游戏:Claude Code实战体验
资深开发者用Claude Code命令行工具,仅凭一句话自然语言提示词,在一小时内生成2048、五子棋、俄罗斯方块等10款可玩网页游戏并部署上线。深度解析AI编程的真实能力与局限。

测试人必备的Cursor Skills五大技能包详解
详解测试工程师必备的五大Cursor Skills技能包,覆盖PRD需求分析、用例生成、JMeter脚本自动化、压测报告一键输出、Web自动化测试全流程,助你从执行者升级为质量架构师。
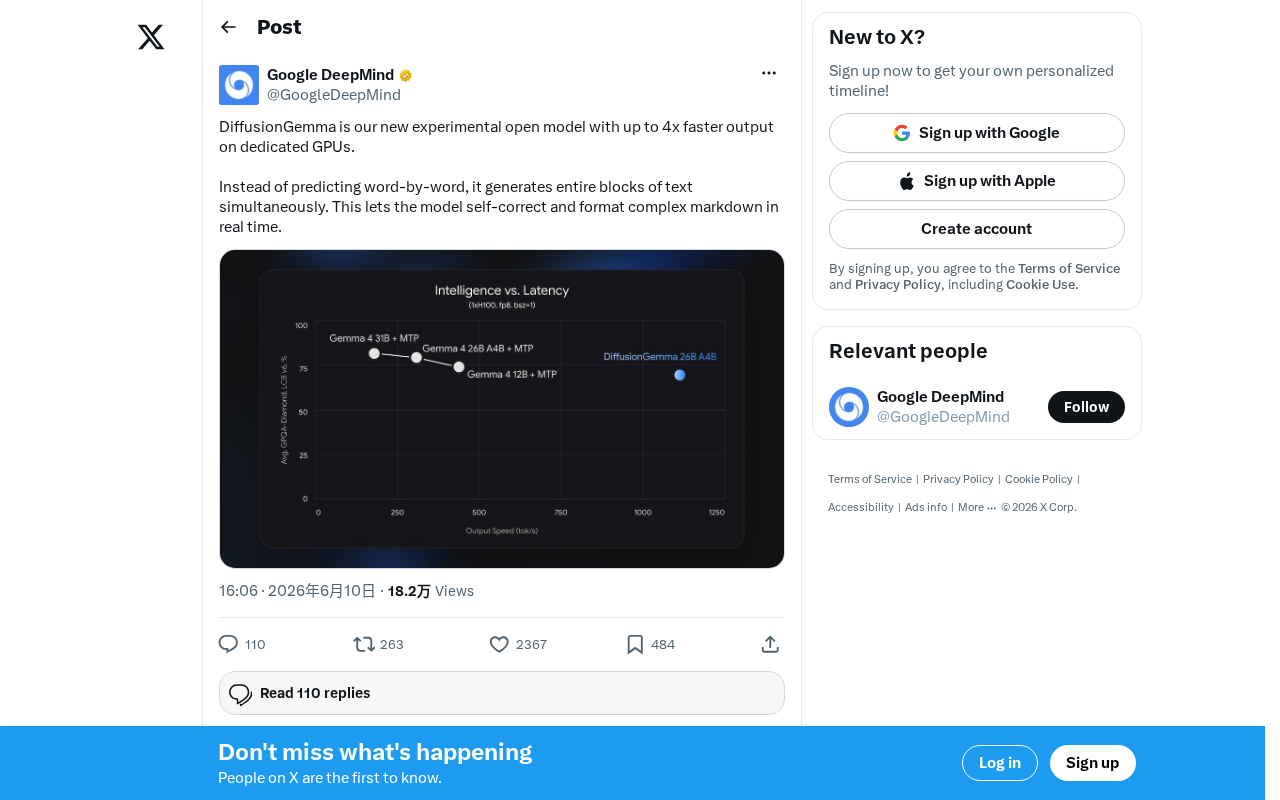
DiffusionGemma:谷歌开源扩散式语言模型,推理速度提升4倍
谷歌发布开源扩散式语言模型DiffusionGemma,将扩散模型思路引入文本生成,实现最高4倍速度提升与实时自我纠错能力。本文详解其核心技术原理、与传统自回归模型的差异及行业影响。