一个BaseURL接入所有AI模型:API聚合方案深度解析

多模型开发的痛点
随着AI编程工具的爆发式增长,开发者手头的模型选择越来越多——Claude Code、OpenAI Codex、Gemini,每一个都有独到之处。但现实问题也随之而来:每个模型一套接口、一个密钥、一种计费方式,管理成本直线上升。
更让人头疼的是稳定性问题。高峰期限流、突发接口故障、响应中断……这些在实际项目中都不是小事。尤其对团队开发而言,一次API中断可能意味着整条CI/CD流水线的停摆。CI/CD(持续集成/持续部署)是现代软件工程的核心实践,指代码从提交到自动测试、构建、部署的完整自动化流水线。当AI编程工具被集成到CI/CD流程中——例如在代码合并前自动调用Claude进行代码审查,或在部署前用Codex生成单元测试——API的可用性就直接关系到整条流水线能否正常运转。当前主流的AI集成模式已经渗透到流水线的多个阶段:Pre-commit Hook阶段调用AI进行代码风格检查和安全漏洞扫描,Pull Request阶段调用AI生成代码审查意见,Post-merge阶段调用AI自动生成变更日志和文档更新。这些集成点的增加意味着流水线对外部API的依赖从传统的包管理器、容器镜像仓库扩展到了AI模型服务,使得API可用性成为DevOps可靠性工程的新维度。一次API中断不仅意味着当前任务失败,还可能触发流水线阻塞,导致后续所有待部署的代码变更排队等待,在大型团队中这种级联效应尤为严重。值得注意的是,现代CI/CD系统(如GitHub Actions、GitLab CI、Jenkins)通常采用有向无环图(DAG)来编排任务依赖关系,当图中某个节点因API超时而失败时,所有下游节点都会被标记为跳过或失败,这在单体仓库(Monorepo)架构中影响尤为广泛——一个仓库中可能有数十个微服务的流水线共享同一套AI代码审查步骤,单点故障会扩散为全局阻塞。
API聚合平台的核心思路
针对这些痛点,以NovrAPI为代表的一类API聚合服务提出了一个直截了当的方案:用一个统一的BaseURL,接入所有主流AI模型的能力。
统一接口层的核心机制
这类平台的技术逻辑并不复杂,但确实解决了实际问题:
- 统一接口层:开发者只需对接一个API端点,后端自动路由到Anthropic、OpenAI、Google等不同厂商的服务
- 单密钥管理:告别为每个模型单独申请、维护API Key的繁琐流程
- 模型自由切换:在代码中更换模型只需修改一个参数,无需重构接口调用逻辑
从技术实现来看,统一接口层的核心是API网关(API Gateway)模式,这是微服务架构中的经典设计模式。其工作原理是:开发者的请求首先到达聚合平台的网关层,网关解析请求中的模型参数(如model字段),然后将请求转换为对应厂商的原生API格式并转发。由于OpenAI、Anthropic、Google等厂商的API在请求体结构、认证方式、响应格式上各不相同,网关层需要维护一套协议适配器(Protocol Adapter),负责在统一格式与各厂商私有格式之间做双向转换。例如,OpenAI使用messages数组中的role/content结构,而Anthropic的Claude API则将系统提示词单独作为顶层system字段传递;Google的Gemini API使用contents数组并采用parts嵌套结构。协议适配器需要处理这些差异,同时还要统一流式响应(Server-Sent Events)的格式——各厂商的SSE数据块结构和结束标记各不相同。
在代码生成场景中,流式输出(Streaming)的处理尤为关键——开发者期望看到代码逐行生成而非等待完整响应返回。然而各厂商的SSE实现差异显著:OpenAI的流式响应以data: [DONE]标记结束,Anthropic使用event: message_stop事件类型,而Google Gemini则通过HTTP/2的流式传输机制实现。聚合网关需要在毫秒级延迟内完成格式转换,同时维护长连接的稳定性——一个流式响应可能持续数十秒,期间网关需要持续占用内存缓冲区并维护TCP连接状态,这对网关的内存管理、连接池设计和并发处理能力提出了很高要求。当数千个开发者同时发起流式请求时,网关的背压(Backpressure)控制机制——即当下游消费速度慢于上游生产速度时如何优雅地调节流量——直接决定了系统的稳定性上限。
这种模式在支付网关(如Stripe聚合多家银行接口)、云服务聚合(如Terraform统一多云API)等领域已有成熟实践。
这意味着,开发者可以在同一个项目中灵活调用Claude做代码审查、用Codex做代码生成、用Gemini做长文本分析,而接口层面完全无感切换。
智能调度与故障容灾
相比简单的API转发,更值得关注的是其调度层设计:
- 自动线路优选:根据延迟和负载情况,动态选择最优的请求路径
- 故障自动切换:当官方接口出现异常时,系统自动切换到备用线路,避免业务中断
- 限流缓冲:在高峰期提供一定程度的请求排队和重试机制
这套容灾逻辑对于生产环境尤为重要。直接调用官方API时,一旦遇到429(限流)或500(服务端错误),开发者需要自己编写重试逻辑和降级策略。HTTP 429状态码(Too Many Requests)是API限流的标准响应,各大模型厂商都设有严格的速率限制(Rate Limit)。例如OpenAI对不同等级用户设定了每分钟请求数(RPM)和每分钟Token数(TPM)的上限——免费层用户可能仅有3 RPM,而Tier 5用户可达10,000 RPM。Anthropic同样按模型和用户等级设置差异化限额,且对并发连接数也有约束。当触发限流时,响应头中通常包含Retry-After字段,指示客户端应等待的秒数。工程实践中,开发者需要实现指数退避(Exponential Backoff)重试策略——即第一次等待1秒、第二次等待2秒、第三次等待4秒,以此类推,同时加入随机抖动(Jitter)避免多个客户端同时重试造成"惊群效应"(Thundering Herd Problem)。惊群效应是分布式系统中的经典问题:当大量客户端在同一时刻被限流后,如果都按固定间隔重试,会在同一时刻再次涌入,形成周期性的流量尖峰,反而加剧限流。随机抖动通过在退避时间上叠加一个随机偏移量来打散重试时间点。这套逻辑看似简单,但要在生产环境中做到健壮可靠,需要处理超时、幂等性(确保重试不会导致重复执行)、死信队列(将多次重试仍失败的请求转入人工处理通道)等诸多边界情况。聚合平台将这些能力内置,降低了工程复杂度。
团队协作与企业落地场景
对于个人开发者,API聚合的价值主要体现在便捷性上。但对团队和企业用户,它还解决了另一层问题——可观测性与成本管控。
数据透明化与用量监控
一个成熟的API聚合平台通常会提供完整的后台管理能力:
- Token消耗追踪:每次调用消耗了多少Token,一目了然
- 订单与计费记录:支持按团队成员、按项目维度查看费用明细
- 渠道状态监控:各模型接口的延迟、成功率等指标实时可视化
Token是大语言模型处理文本的基本计量单位,并非简单等同于一个字或一个词。大多数现代LLM使用BPE(Byte Pair Encoding,字节对编码)或类似的子词分词算法将文本切分为Token。对于英文文本,一个Token大约对应4个字符或0.75个单词——常见单词如"the"是一个Token,而较长或罕见的单词如"counterintuitive"可能被拆分为多个Token。对于中文文本,一个汉字通常消耗1.5到2个Token,这是因为中文字符在UTF-8编码中占3个字节,而BPE词表中中文的覆盖密度低于英文。模型的计费通常按输入Token和输出Token分别定价,且价格差异显著——例如Claude 3.5 Sonnet的输入价格为每百万Token 3美元,输出价格为每百万Token 15美元,输出价格高达输入的5倍,这反映了生成文本比理解文本需要更多的计算资源(生成过程中模型需要逐Token进行自回归推理,每生成一个Token都需要一次完整的前向传播计算,而输入Token可以通过并行处理一次性编码)。在实际项目中,系统提示词(System Prompt)、对话历史上下文、Few-shot示例都会计入输入Token,这意味着一个看似简短的用户请求,加上2000 Token的系统提示词和5000 Token的对话历史,实际输入Token消耗可能达到7000以上。精确的Token追踪能帮助团队识别哪些调用模式在"烧钱"——例如发现某个Agent循环调用导致上下文窗口不断膨胀,或者某段冗余的系统提示词在每次请求中重复传输——从而优化提示词设计、引入摘要压缩机制或调整上下文窗口策略。
这些能力在企业场景下几乎是刚需。当团队规模超过5人,如果没有统一的用量监控,API费用很容易失控。
适用场景与选型考量
当然,API聚合方案并非万能。以下几点值得开发者在选型时考量:
- 延迟敏感场景:中间多了一层转发,理论上会增加数毫秒到数十毫秒的延迟,对实时性要求极高的场景需实测评估
- 数据安全合规:请求经过第三方平台中转,涉及敏感数据的企业需要评估合规风险
- 成本对比:聚合平台通常会在官方价格基础上加一定服务费,需与自建方案做成本比较
在数据安全合规方面,当API请求经过第三方聚合平台中转时,涉及多个层面的考量。首先是数据传输安全,请求内容是否全程TLS 1.3加密、平台是否会缓存或存储请求/响应数据——部分平台为了实现请求日志和用量统计,可能会在服务端短暂存储请求体,这对包含用户隐私数据或商业机密的请求构成风险。其次是数据驻留(Data Residency)问题,某些行业法规(如欧盟GDPR要求数据处理需有合法基础且数据主体有被遗忘权、中国《数据安全法》和《个人信息保护法》对跨境数据传输设有安全评估要求)规定数据不得跨境传输或必须存储在指定区域,如果聚合平台的服务器部署在海外,而用户数据涉及中国公民个人信息,则可能触发跨境数据传输的合规审查。第三是审计与溯源能力,企业需要确认平台是否提供完整的访问日志(包括请求时间戳、来源IP、调用模型、Token消耗等),以满足SOC 2 Type II(关注服务组织在一段时间内安全控制的运行有效性)、ISO 27001(信息安全管理体系国际标准)等安全认证的审计要求。此外,部分行业如金融(需满足PCI DSS支付卡行业数据安全标准)、医疗(需满足HIPAA健康保险可携性和责任法案)对供应商的安全资质有明确准入门槛,使用第三方中转服务可能需要额外的供应商安全评估(Vendor Security Assessment)流程,包括安全问卷调查、渗透测试报告审查、数据处理协议(DPA)签署等环节。
开发者的务实选择
当下的AI开发生态中,模型能力本身的差距在缩小,稳定性和工程效率正在成为更关键的竞争维度。与其在多个官方控制台之间来回切换、为每个模型单独处理异常逻辑,不如用一个统一的接入层把这些基础设施问题一次性解决。
从更宏观的视角来看,API聚合平台的兴起反映了AI工程化进程中"基础设施层"与"应用层"分离的趋势。正如云计算时代开发者不再自建机房,而是将计算、存储、网络等基础设施交给AWS/Azure/GCP管理一样,AI开发中的模型接入、流量调度、故障容灾等"管道层"工作也在逐步被专业化的中间件服务接管。这让开发者能将更多精力聚焦在真正创造差异化价值的应用逻辑上——如何设计更好的Agent架构、如何构建更精准的RAG流水线、如何优化人机交互体验——而非反复处理API对接的工程琐事。
这里提到的Agent(智能体)和RAG(检索增强生成)是当前AI应用开发的两大核心范式,也是API调用量最密集的场景。Agent指具备自主规划、工具调用和多步推理能力的AI系统,典型框架如LangChain的AgentExecutor和Microsoft的AutoGen,它们通过循环调用LLM来分解任务、选择工具、执行操作并评估结果——一个复杂任务可能触发数十次LLM调用,每次调用都携带不断增长的上下文。RAG则是将外部知识库与LLM结合的技术架构,通过向量数据库(如Pinecone、Milvus、Weaviate)检索与用户查询语义相似的文档片段,将其注入提示词上下文,从而让模型基于最新、专业的知识生成回答,有效缓解模型"幻觉"(Hallucination)问题——即模型自信地生成看似合理但实际错误的内容。一个典型的RAG流水线包含文档分块(Chunking)、向量化(Embedding)、相似度检索(Similarity Search)、上下文组装和LLM生成等步骤,其中向量化和生成步骤都需要调用模型API。这两种架构的高频调用特性使得API的稳定性、成本控制和多模型灵活切换能力变得更加关键——例如在RAG流水线中,可能用性价比更高的模型做文档摘要,而用能力更强的模型做最终回答生成。
对于正在同时使用多个AI模型的开发团队来说,API聚合平台值得纳入技术选型的考量范围。关键是要验证其在你具体业务场景下的稳定性和性价比,而不是盲目跟风。
核心要点
- 多模型并用已成常态,接口管理和稳定性是核心痛点
- API聚合平台通过统一网关、协议适配、智能调度解决工程复杂度
- 内置的重试、容灾、限流缓冲机制降低了生产环境的运维负担
- Token级别的用量追踪和成本分析是团队规模化使用AI的刚需
- 选型时需权衡延迟增加、数据合规风险与工程效率提升之间的取舍
- Agent和RAG等高频调用架构使API聚合的价值进一步放大
相关推荐
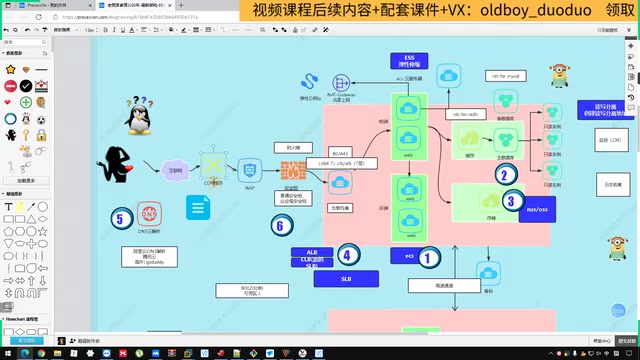
阿里云网站架构全解析:从DNS到弹性伸缩的完整链路
系统梳理阿里云网站架构核心组件,按用户请求流向详解DNS云解析、CDN、WAF防火墙、CLB/ALB负载均衡、ECS云服务器、Redis缓存、NAS/OSS存储及弹性伸缩等服务的作用与协作关系,帮助初学者建立完整的云架构认知体系。
Claude Code实战:60美元4小时完成复杂支付系统二开
通过真实商业案例详解Claude Code + Opus 4.7如何在4小时内完成复杂支付系统二开,涵盖CC Switch配置、Prompt工程技巧、模型选择策略及AI Coding工程化落地方法论。

Vibe Coding入门指南:零基础用AI写代码的完整攻略
Vibe Coding(氛围编程)让零基础用户通过自然语言指令实现软件开发。本文详解Vibe Coding的核心概念、适用场景、推荐工具及实践步骤,帮你快速上手AI编程。