Agent Memory: Giving AI Coding Agents Persistent Memory Across Sessions
Agent Memory: Giving AI Coding Agents …
Agent Memory provides AI coding agents with a shared local long-term memory layer across tools
Agent Memory is an open-source project (10.8k GitHub stars) that solves the pain point of AI coding agents requiring repeated project context explanation every new session. It builds a persistent local memory layer supporting tools like Claude Code, Codex, and Cursor to share the same memory via MCP protocol, plugins, or REST API, with semantic-level intelligent retrieval capabilities, representing the evolution of AI coding tools from stateless conversations to stateful continuous collaboration.
Tired of Re-explaining Your Project Every New Session? It's Time to Fix That
If you frequently use AI for coding, you've almost certainly experienced this scenario: you're still working on the same project, but just because you started a new session, you have to explain the directory structure, technical decisions, and historical bugs all over again. It gets even worse when you use multiple Agents—you finished authentication in Claude Code yesterday, and today you want to continue in Codex or Cursor, but the moment you switch sessions, all context is completely lost.
The technical root cause of this pain point is that current large language models (LLMs) are fundamentally stateless inference engines—each API call is independent, and the model itself retains no session history. The "conversation memory" developers see is actually implemented at the application layer by concatenating historical messages into each request's prompt—essentially trading tokens for memory. This creates two hard constraints: first, context windows have upper limits (even though GPT-4 or Claude support hundreds of thousands of tokens, ultra-long contexts significantly increase latency and cost); second, when switching between tools, each tool maintains its own session history, creating natural silos.
Copying historical context can work as a workaround, but it wastes tokens and easily stuffs irrelevant content into the prompt. Static rule files (like .cursorrules) help too, but they're more like project documentation than memory that actually grows on its own.
Agent Memory is an open-source project built specifically to solve this problem, and it has already earned 10.8k stars on GitHub. Its positioning is clear: a local memory layer that adds long-term memory to AI coding agents. It essentially builds a persistent "external memory" outside the LLM, architecturally bypassing the model's inherent stateless limitation.
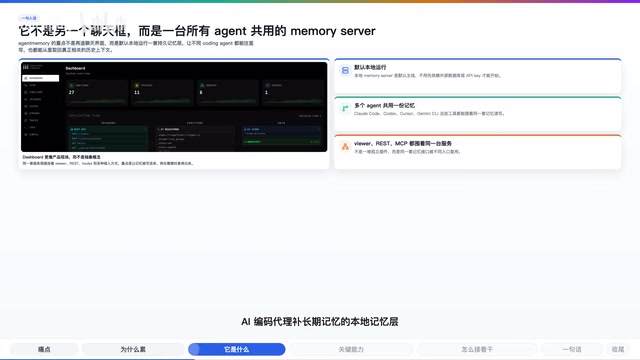
Core Positioning: Not a Chat Interface, But a Shared Memory Server
Looking at the project's design philosophy, Agent Memory's focus isn't on building yet another chat interface—it's about being a Memory Server shared by all Agents. Tools like Claude Code, Codex, Cursor, and Gemini CLI can all write data to the same memory system and retrieve truly relevant historical context from it.
In other words, it's not about saving a bunch of notes—it's about letting Agents spend less time re-understanding and more time picking up where they left off. The value of this approach is clear: memory is no longer bound to a specific tool's session but becomes a project-level shared asset.
Four Core Capabilities in Detail
Agent Memory's most noteworthy capabilities fall into four categories:
1. Local Memory Storage Service
You can persistently store historical observations, technical preferences, and architectural decisions from your project. This memory resides locally, independent of cloud services, ensuring both data privacy and a low barrier to entry. For teams with security and compliance requirements, local storage is a key advantage.
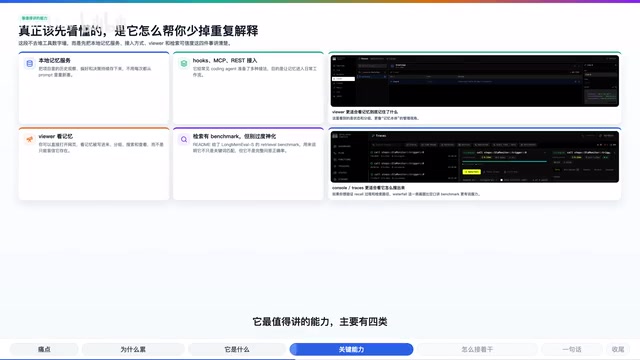
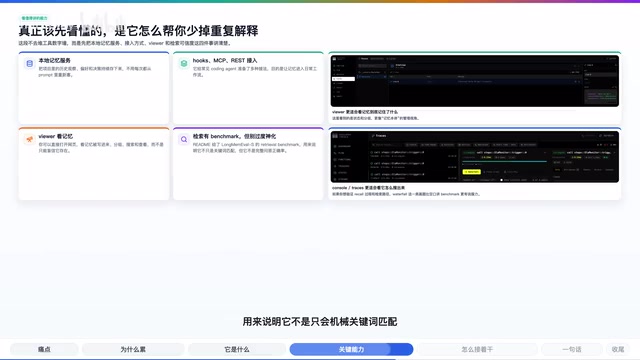
2. Automatic Integration with Multiple AI Coding Tools
Agent Memory provides various integration methods for mainstream coding tools, including plugins, Hooks, MCP protocol, and REST API.
MCP (Model Context Protocol) is a standardized protocol proposed and open-sourced by Anthropic in late 2024, designed to provide a unified interface specification for interactions between AI models and external tools or data sources. Before this, every AI coding tool had its own plugin or extension mechanism, all incompatible with each other. MCP's emergence is similar to the "USB standard" for AI tools—as long as MCP is supported, capabilities like memory services, code execution environments, and database queries can be called by any compatible Agent. Currently, mainstream tools including Claude Code and Cursor have announced or implemented MCP support, providing protocol-level assurance for the adoption of cross-tool infrastructure like Agent Memory.
This means that regardless of whether you use Claude Code, Codex, Cursor, or other Agents, you can connect to the same memory system with minimal effort, achieving true cross-tool memory sharing.
3. Real-time Viewer Visualization Panel
The project includes a web-based real-time Viewer where you can open your browser and see how memories are being written, searched, and replayed. This is not only convenient for debugging but also gives developers an intuitive understanding of how the memory system operates.
4. Semantic-Level Intelligent Retrieval
The README provides Long-term Memory Retrieval Benchmark data to demonstrate that it doesn't just perform mechanical keyword matching—it has semantic-level retrieval capabilities.
The core difference between Semantic Retrieval and traditional keyword matching is that it converts text into numerical vectors in high-dimensional space through Vector Embedding, making semantically similar content closer together in vector space. This technology relies on the RAG (Retrieval-Augmented Generation) architecture—first retrieving the most relevant historical fragments from the memory store, then injecting them into the current conversation context, allowing the Agent to obtain precise historical information without consuming large amounts of tokens. This means that even if your phrasing differs from when the memory was originally stored, the system can still find truly relevant historical decisions rather than only matching identical keywords.
However, as the original author states, what you should really understand first isn't the benchmark numbers, but how much repeated explanation it saves you.
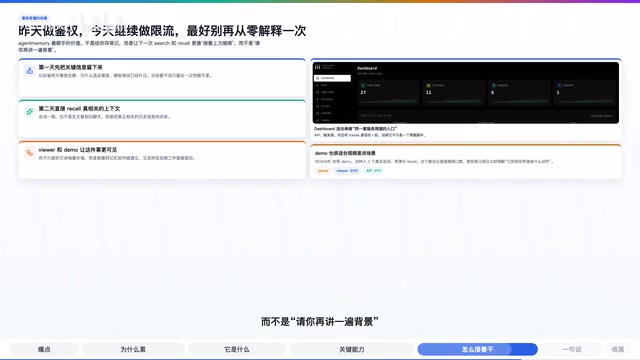
Practical Scenario: Working on the Same Backend Project for Two Consecutive Days
The easiest scenario to understand is this: you're using an Agent to push forward the same backend project over two consecutive days.
- Day 1: Have the Agent set up JWT authentication, complete the core auth logic, and add related tests.
- Day 2: Continue having the Agent implement rate limiting or performance optimization.
Normally, once a new session starts, the Agent has to re-understand where the authentication scheme lives, why you chose that particular library, and how far the tests got. With Agent Memory, this historical information stays in local memory, and the next search and recall feels more like continuing from where you left off, rather than "please explain the background again."
This scenario extends further: when multiple team members collaborate using different AI coding tools, the value of a shared memory layer becomes even more apparent. An architectural decision made by one person in Claude Code can be directly accessed by another person in Cursor, avoiding information silos.
Why This Direction Deserves Attention
From a broader perspective, Agent Memory represents an important evolutionary direction in AI coding tool development: moving from stateless single-shot conversations to stateful continuous collaboration.
Current mainstream AI coding tools are fundamentally "memoryless"—every session starts as a blank slate. While some tools have begun supporting project-level context files, these static configurations are far from replacing dynamically accumulated project memory. What Agent Memory aims to fill is precisely this gap between "static configuration" and "dynamic memory."
Several trends worth noting:
- Multi-Agent collaboration is becoming the norm: More and more developers use multiple AI tools simultaneously, and the demand for cross-tool memory sharing will only grow stronger.
- MCP protocol adoption: Standardized integration protocols make the connection between memory layers and different Agents increasingly smooth. Anthropic's open-sourcing of MCP and push for industry adoption is establishing a foundational protocol status similar to HTTP for the Web.
- Local-first privacy strategy: Storing memory locally rather than in the cloud meets enterprise security requirements while reducing data breach risks.
Summary
In one sentence: Agent Memory is a local layer that adds long-term memory to AI coding agents. The core problem it aims to solve isn't adding more tool entry points—it's stopping you from having to re-explain your project background to AI over and over again within the same project.
If you're already using multiple Coding Agents simultaneously, or frequently waste time re-explaining context due to session interruptions, this project is well worth trying. The 10.8k star count also demonstrates that this pain point truly resonates with a large number of developers.
Key Takeaways
- Agent Memory is a local memory layer that solves the pain point of AI coding agents needing project background re-explained every new session
- Supports multiple Agents including Claude Code, Codex, and Cursor sharing the same memory system, connected via plugins, MCP, REST API, and more
- Four core capabilities: local memory storage, multi-Agent automatic integration, real-time Viewer visualization, and semantic-level intelligent retrieval
- Represents an important evolution in AI coding tools from stateless single-shot conversations to stateful continuous collaboration
- The project has earned 10.8k GitHub stars, with its local-first storage strategy balancing both privacy security and ease of use
Related articles
 Product Reviews
Product ReviewsQoder vs Cursor Real-World Comparison: Which $20/Month AI IDE Is Better?
Hands-on comparison of Qoder vs Cursor AI IDEs: Agent autonomy, human interaction count, and architecture decisions. Qoder needed only 2 interactions vs Cursor's 8.
 Product Reviews
Product ReviewsCursor Cloud Agent Demo: Eliminating Bottlenecks Across the Entire Software Development Lifecycle
Deep analysis of Cursor's Cloud Agent demo showing how cloud VMs, automated test artifacts, and a full-chain control plane systematically eliminate human bottlenecks across the software development lifecycle.
 Product Reviews
Product ReviewsCursor 3.0 Deep Dive: Multi-Agent Parallelism, Design Mode, and Best-of-N Model Comparison
Cursor 3.0 evolves from an AI coding assistant into an Agent fleet command center. Explore multi-agent parallelism, Design Mode, and Best-of-N model comparison.