AI Agent Core Architecture Breakdown: From Concept to Enterprise-Grade Intelligent Agent Development
A complete breakdown of AI Agent architecture covering perception, reasoning, memory, and tool-calling systems.
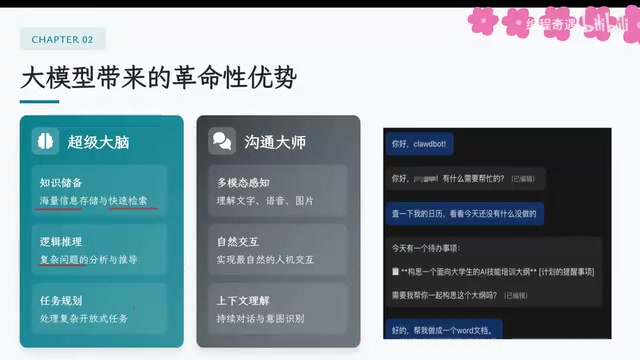
This article provides a comprehensive analysis of AI Agent architecture, covering the three core modules — perception (multimodal input), brain (Chain of Thought reasoning and planning), and action (tool calling via MCP protocol). It also explains memory systems including context window management and RAG-based long-term memory, and offers a skill roadmap for enterprise agent development.
What Is an AI Agent? Why It's More Than Just a "Proxy"
AI Agents have become one of the hottest concepts in artificial intelligence. From OpenAI's Operator to Anthropic's Claude Computer Use, major companies are betting heavily on this direction. Yet many people still have only a surface-level understanding of AI Agents — isn't it just a "proxy" that does things on your behalf?
In reality, the term "Agent" here emphasizes independence and autonomy. Traditional AI conversations are merely passive responses, but an intelligent agent can receive a single instruction, autonomously plan the task workflow, invoke tools, and accomplish goals — all without requiring step-by-step human intervention. More importantly, when it discovers gaps in its own knowledge, it can proactively search the internet or call external tools to supplement its capabilities.
Notably, the concept of AI Agents didn't originate in the era of large language models. As early as the 1990s, AI researchers Stuart Russell and Peter Norvig defined an Agent in their classic textbook Artificial Intelligence: A Modern Approach as "anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators." At that time, Agent research primarily focused on Multi-Agent Systems and reinforcement learning domains, such as robot navigation and game theory scenarios. The emergence of large language models elevated Agents from constrained rule-based systems to intelligent entities with general reasoning capabilities — and that's what sparked the current industry boom.
The Capability Leap of Large Models: Infrastructure for Intelligent Agents
From Text Generation to Deep Reasoning
The first prerequisite for building an intelligent agent is that the underlying large model must be sufficiently intelligent. Early AI was primarily limited to text creation and code writing, frequently making errors when faced with complex mathematical problems. Today's large models have developed Chain of Thought capabilities — they can automatically decompose complex tasks into simple steps and reason through them incrementally.
The Chain of Thought concept was formally introduced by Jason Wei and colleagues from the Google Brain team in a 2022 paper. They discovered that simply adding guidance like "Let's think step by step" to prompts could dramatically improve accuracy on mathematical reasoning and logical judgment tasks. The underlying reason lies in the nature of large models as autoregressive generation models — each output step depends on the preceding context. When intermediate reasoning steps are explicitly unfolded, the model essentially gains a "scratch pad," allowing it to leverage intermediate results to progressively approach the correct answer rather than jumping directly to a final conclusion.
This capability improvement means large models are no longer merely "parroting" — they genuinely possess foundational abilities for logical reasoning and task planning.
Multimodal Perception: Breaking the Text Barrier
The limitation of traditional AI conversations was that they could only send and receive text. The emergence of multimodal models completely changed this — users can input information through text, voice, images, video, and other modalities, while AI can also generate images, voice, and even video as output.
The core challenge of multimodal models is aligning different types of information (text, images, audio) within a shared representation space. Take GPT-4V as an example: it uses a visual encoder (such as the ViT architecture) to convert images into a series of visual tokens, which are then jointly processed with text tokens through a shared Transformer architecture. During training, massive amounts of image-text paired data are used, enabling the model to learn mappings between visual concepts and language descriptions. This also explains why multimodal models sometimes "misread" images — the visual encoder's resolution and training data coverage directly determine recognition accuracy.
This natural interaction experience is like chatting with an all-capable assistant in a messaging app: when you encounter a problem, simply take a screenshot and send it. The AI understands the image and provides an answer directly, without the need to laboriously describe complex scenes in text.
The Three Core Architectural Modules of an Intelligent Agent
Perception Module: Multimodal Input
As an intelligent agent capable of independently completing tasks, the first requirement is perceiving the external environment. This is precisely where multimodal capabilities shine — acquiring information through visual, auditory, and other channels, enabling AI to "see" the user's screen and "hear" voice commands.
Brain Module: Thinking, Decision-Making, and Planning
After perceiving external information, the agent needs to think and make decisions. This module contains several key components:
- Reflection: Self-critiquing and correcting its own outputs
- Chain of Thought: Decomposing tasks into sequentially executable subtasks
- Planning: Formulating an overall strategy to achieve the goal
This is like clicking the "deep thinking" button on a large model — it first analyzes what the task is, then plans what to do in step one, step two, and so on, ultimately forming a complete execution plan.
Action Module: Tool Calling Is Key
If a large model can only theorize within a chat window, it obviously cannot truly accomplish tasks. The action module gives AI actual execution capabilities through Tool Use:
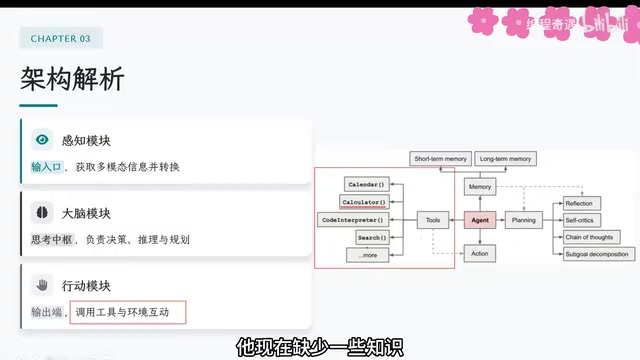
- Calculator: Invokes a calculator tool for complex computations
- Search: Performs web searches when knowledge is insufficient
- Code Interpreter: Writes and verifies code correctness
- API Calls: Interfaces with third-party services like payments and food delivery
Standardization of tool calling is becoming an industry focal point. Anthropic's MCP (Model Context Protocol) attempts to define a universal specification for AI tool calling interfaces, similar to HTTP in the web domain. Before MCP, each LLM provider had different Function Calling formats — OpenAI uses JSON Schema to define tool parameters, while others might adopt entirely different description approaches. MCP's goal is to allow tool developers to write a tool definition once and have it callable by any model supporting the protocol, thereby building an open AI tool ecosystem. This is crucial for Agent adoption, as the richness of available tools directly determines an Agent's practical capability boundaries.
Here's a practical example: when a user says "Order me a coffee," the agent first considers the user's preferences and habits, selects an appropriate coffee type, then calls the payment interface to complete the order — the entire process executed autonomously.
Memory System: Making AI Truly "Know" You
Short-Term Memory: Context Window Management
Many people assume that when chatting with AI, there's a dedicated AI continuously serving them. In reality, the AI starts "from scratch" every time — its ability to remember previous conversations relies entirely on Context Window management.
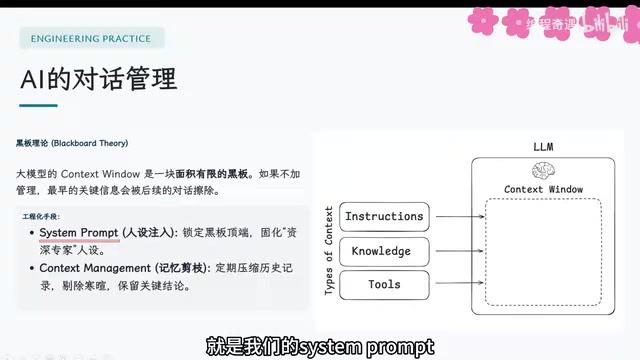
The context window is like a whiteboard with limited space, containing all conversation history and system instructions. The context window length is constrained by the computational complexity of the self-attention mechanism in the Transformer architecture — standard self-attention computation scales quadratically with sequence length. GPT-3's context window was only 4,096 tokens (approximately 3,000 Chinese characters), while today Claude 3.5 supports 200K tokens, and Gemini 1.5 Pro reaches 1 million tokens. These breakthroughs rely on technologies like Sparse Attention, Sliding Window Attention, and RoPE positional encoding extrapolation. However, a longer window doesn't mean the model utilizes all information uniformly — research shows that models utilize information in the middle of the window significantly less than at the beginning and end, a phenomenon known as "Lost in the Middle."
When conversation turns become too numerous and the window is about to overflow, memory compression techniques are needed: all conversations are handed to another AI for summarization, extracting key information (such as the user's name, preferences, etc.), deleting irrelevant small talk, and thereby freeing up space for new conversations.
The main engineering approaches include:
- System Prompt: Locked at the top of the window, never deleted, defining the AI's role and core tasks
- Memory Compression: Automatically summarizing when conversations become too long, retaining key information
Long-Term Memory: RAG and Knowledge Bases
Short-term memory addresses coherence within a single session, while long-term memory requires RAG (Retrieval-Augmented Generation) technology to implement.
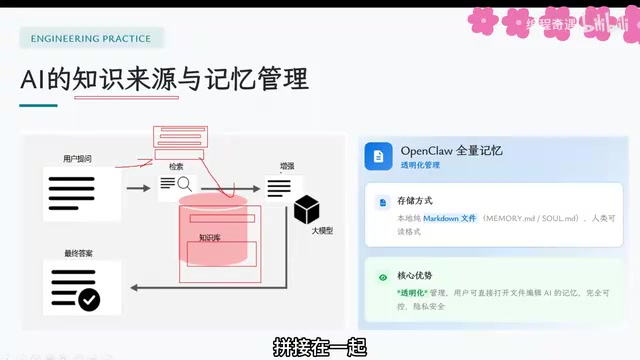
RAG (Retrieval-Augmented Generation) was proposed by Patrick Lewis and colleagues at Facebook AI Research (now Meta AI) in 2020. Its working principle is as follows:
- Store user history, enterprise private knowledge, and other data in a vector knowledge base
- When a user asks a question, convert the query into a vector and retrieve relevant segments from the knowledge base
- Concatenate the retrieved relevant materials with the user's question and feed them together to the large model for answering
In practice, a RAG system's effectiveness depends on several key components: First is the text splitting strategy, which typically segments by semantic paragraphs rather than fixed lengths — common chunk sizes are 500-1,000 tokens with 10-20% overlap retained. Second is the choice of embedding model — mainstream options like OpenAI's text-embedding-3 and the open-source BGE series can map text to 768 or 1,536-dimensional vector spaces. Finally, there's the retrieval strategy — Hybrid Search combines vector semantic retrieval with traditional keyword retrieval (such as BM25), achieving a balance between semantic understanding and exact matching.
This way, the large model can always provide precise answers based on accurate background knowledge, solving the problems of "hallucination" and outdated knowledge.
Another implementation approach is similar to Claude's memory mechanism — storing user memories as Markdown files that users can directly view and edit, making it both transparent and controllable.
Four Core Characteristics of an Intelligent Agent
In summary, a qualified AI Agent must possess the following characteristics:
- Independence and Autonomy: No need for step-by-step human guidance; autonomously executes after receiving a goal
- Goal Orientation: All actions serve the completion of the final task
- Environmental Perception: Acquires external information through multimodal inputs including text, images, voice, screen content, etc.
- Action Execution Capability: Performs real-world operations through tool calling
Learning Recommendations and Skill Roadmap
For practitioners looking to get started with AI Agent development, the following skills are essential:
- Understanding LLM Fundamentals: Grasping foundational concepts like Transformer architecture, context windows, and token mechanisms
- RAG Technology: Mastering engineering practices including vector databases, text splitting, and retrieval strategies
- Tool Development: Ability to write tool functions in code for AI to invoke
- Prompt Engineering: System prompt design and optimization
- Workflow Orchestration: Building complete Agent workflows using platforms like Dify
AI Agents aren't a distant future concept — they're a technological paradigm actively reshaping how we work today. Understanding their architectural principles is a required course for every technology professional.
Related articles
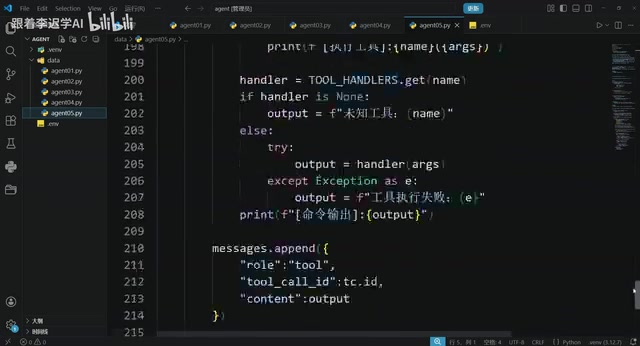
Hands-On Tutorial: Build an AI Agent from Scratch with 200 Lines of Python
Build an AI Agent from scratch with 200 lines of Python, covering prompts, memory, tool calling, RAG, and Skills — a practical guide for developers.
Anthropic Reverses Controversial Policy of Secretly Throttling AI Researchers Using Claude
Anthropic reverses its controversial policy of secretly throttling Claude Fable/Mythos responses to frontier LLM development requests after community backlash, raising critical questions about AI transparency.
Practical Guide to Configuring 6 Major AI Coding CLI Tools on Windows
Complete guide to configuring Claude Code, GitHub Copilot CLI, OpenAI Codex, Trae, and OpenCode on Windows, covering environment variables, API setup, and model configuration.