AI API Aggregation Gateways: A Complete Analysis of Pros and Cons for Unified Multi-Model Access

API aggregation gateways offer a pragmatic engineering solution to multi-model integration fragmentation.
As the AI LLM ecosystem fragments, developers face pain points including complex configuration, insufficient stability, and scattered costs when using multiple models in parallel. API aggregation gateways address these through unified interface specifications, intelligent routing with disaster recovery, and consolidated billing and monitoring. However, careful evaluation of data security, network latency, service continuity, and compliance risks is essential when choosing a solution.
The Integration Dilemma in the Multi-Model Era
As AI large language models proliferate, developers face an increasingly practical problem: projects need to call APIs from multiple AI models simultaneously, but each vendor has different interface specifications, authentication methods, and billing logic. From OpenAI to Anthropic's Claude to Google's Gemini, every new model integration means an entirely new configuration workflow.
The current AI LLM market has formed a multi-polar landscape. OpenAI's GPT series is renowned for its general-purpose capabilities, Anthropic's Claude series has unique advantages in long-context processing and safety alignment, and Google's Gemini deeply integrates multimodal capabilities with its search ecosystem. There are also players like Meta's open-source Llama series, Mistral, and Cohere. Each vendor has a different API design philosophy: OpenAI uses the Chat Completions format, Anthropic uses the Messages API with a unique system prompt handling approach, and Google follows its own Vertex AI framework. This ecosystem fragmentation is an inevitable byproduct of rapid technological evolution, but it places a significant integration burden on downstream developers.
Recently, discussions on platforms like Bilibili have highlighted pain points encountered when using tools like Claude Code in real-world development: response lag, output quality fluctuations, and unstable connections. These issues aren't unique to any single model — they're common challenges when using multiple models in parallel.

Core Pain Points of Parallel Multi-Model Usage
Severe Configuration Fragmentation
When a project needs to use multiple AI models, developers must maintain multiple sets of API keys, multiple Base URLs, different request formats, and separate error handling logic. Switching models requires modifying code configuration each time, which is extremely inefficient in fast-iterating projects. For team collaboration, managing configurations across different members using different models is a nightmare.
Specifically, OpenAI uses Bearer Token authentication, while Anthropic requires setting x-api-key and anthropic-version fields in request headers, and Google's Gemini API requires OAuth 2.0 or an API Key combined with a project ID. Error code systems also differ — OpenAI returns standard HTTP status codes with JSON error objects, Anthropic has its own error type enumeration, and Google follows gRPC status code conventions. This means developers need to write independent error handling and retry logic for each model.
Insufficient Stability and Disaster Recovery
When a single API route goes down, the entire feature module depending on that model becomes paralyzed. In production environments, this risk is unacceptable. Developers are forced to implement their own failover logic, retry mechanisms, and degradation strategies — infrastructure-level work that consumes significant effort that should be spent on business development.
From an engineering practice perspective, a robust disaster recovery system needs to include health checks (periodic probing of upstream service availability), circuit breakers (preventing cascading failures), backoff retries (exponential backoff to avoid avalanche effects), and degradation strategies (switching to fallback models or returning cached results when the primary model is unavailable). Building this system in-house not only has high development costs but also requires ongoing operational investment to tune threshold parameters and monitoring alert rules.
Scattered Costs That Are Hard to Monitor
Token consumption across multiple models is scattered across different platforms, making unified monitoring and budget management difficult. Especially for small and medium-sized teams, the lack of clear cost visualization tools means unexpected overspending at the end of the month.
LLM API billing is typically based on token consumption, where input and output tokens have different unit prices (output is usually 2-4x the cost of input). Different models also tokenize differently: the GPT series uses tiktoken (based on BPE encoding), while Claude uses a proprietary tokenizer. The token count for Chinese characters can vary by 30%-50% across different tokenizers. This means the actual cost of the same Chinese prompt can differ significantly across models. Without a unified cost comparison perspective, it's difficult for developers to make the most cost-effective model choice when performance is similar.
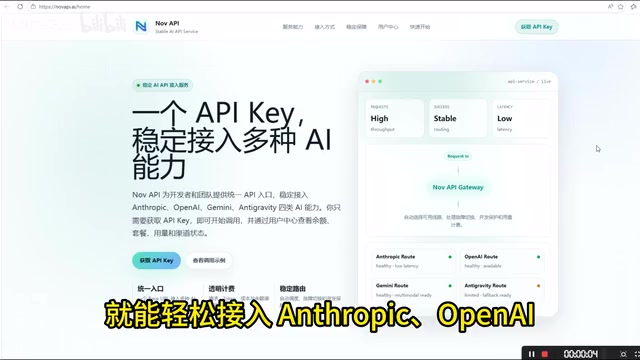
The API Aggregation Gateway Approach
A number of API aggregation services (such as NOVAPI.AI and others) have emerged in the market, with the core concept of solving the above problems through a unified gateway layer.
From a technical architecture perspective, API aggregation gateways draw on the mature API Gateway pattern from the microservices domain (design principles from open-source solutions like Kong and Envoy). Core components include: a request parsing layer (converting unified formats to vendor-specific formats), an intelligent routing engine (making decisions based on multiple dimensions like latency, cost, and availability), connection pool management (maintaining persistent connections with upstream services to reduce handshake overhead), and an observability layer (covering metrics collection, structured logging, and distributed tracing).
Unified Interface Specification to Reduce Switching Costs
Through a single Base URL and unified request format, developers can switch underlying models without modifying code structure. This abstraction layer design turns model selection into a configuration item rather than a code change.
This design pattern is known in software engineering as the "Adapter Pattern" or "Facade Pattern." The gateway layer exposes a unified OpenAI-compatible format externally (which has become the de facto industry standard), while internally using protocol converters to adapt requests to each vendor's native API. Developers only need to master one SDK and request specification to access dozens of different models, dramatically reducing learning costs and code maintenance burden.
Intelligent Routing and Automatic Disaster Recovery
Aggregation gateways typically have built-in intelligent route selection and automatic failover mechanisms. When a particular route experiences increased latency or errors, requests are automatically routed to backup channels, ensuring service continuity.
Intelligent routing typically employs weighted round-robin, lowest-latency-first, or dynamic weight algorithms based on health checks. Failover relies on the Circuit Breaker Pattern — when a route's error rate exceeds a preset threshold within a sliding time window, the circuit breaker automatically opens and diverts traffic to backup channels. After a cooling period, it enters a half-open state, allowing a small number of probe requests through to detect whether the route has recovered. This mechanism ensures that even if a single route has issues, end users barely notice any service interruption.
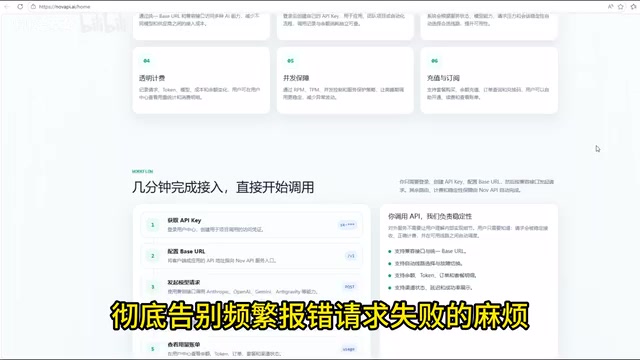
Unified Billing and Real-Time Monitoring
All model invocation data converges in a single dashboard, with token consumption, call success rates, network latency, and other metrics available in real time. This directly helps with project cost control and performance optimization.
The value of a unified billing platform lies in standardizing heterogeneous billing logic and providing cross-model cost comparison analysis. Developers can intuitively see the token consumption and cost differences for the same task across different models, enabling them to choose more cost-effective models when performance is comparable. Additionally, real-time monitoring helps detect abnormal usage patterns (such as a sudden spike in token consumption from a particular feature module), allowing timely investigation of whether it's a prompt design issue or a business logic bug.
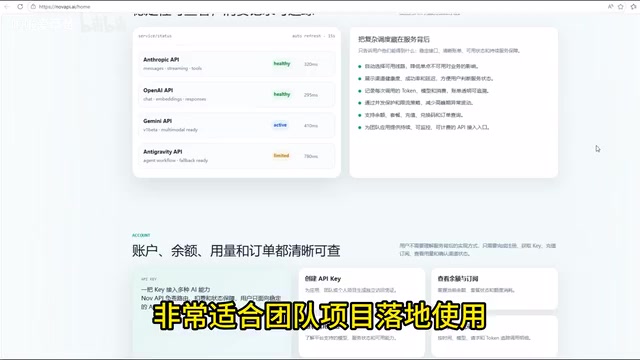
Key Considerations When Choosing an Aggregation Solution
Although API aggregation gateways look attractive, developers should remain cautious when making their choice, focusing on the following aspects:
Data Security: All requests pass through a third-party relay — how is sensitive data security guaranteed? Does the service provider have clear data processing agreements and privacy policies?
When requests pass through a third-party gateway, data security involves multiple layers: transport layer encryption (TLS 1.3 should be ensured), data residency policies (whether request content is persisted to disk, whether logs contain full prompt content), access control (API Key permission granularity and regular rotation mechanisms), and audit trail capabilities. Regarding compliance frameworks, check whether the provider has SOC 2 Type II certification, complies with GDPR data processing requirements, and offers a formal Data Processing Agreement (DPA). For scenarios involving PII (Personally Identifiable Information) or trade secrets, it's advisable to first evaluate whether the provider supports zero-log mode or private deployment options.
Network Latency Overhead: An additional gateway layer means an extra network hop. For scenarios with high real-time requirements (such as conversational interactions and streaming output), the latency impact needs careful evaluation.
From a network architecture perspective, the additional hop typically adds 10-50ms of latency (depending on the gateway node's geographic location and network quality). For streaming output (Server-Sent Events) scenarios, Time to First Token (TTFT) is a critical user experience metric. If the gateway layer adds significant TTFT, users will noticeably perceive a longer "thinking time." It's recommended to conduct actual latency benchmark tests during evaluation, comparing P50/P95/P99 latency data between direct connections and gateway-routed connections.
Service Continuity: How stable is the third-party aggregation service itself, and what is its long-term operational viability? If the service shuts down, how high are the migration costs?
Compliance Risks: Does calling APIs through unofficial channels comply with each model vendor's terms of service? This is especially important for commercial projects. Some model vendors' ToS explicitly prohibit accessing their APIs through unauthorized third-party proxies, and violating these terms could result in API Key bans or even legal risks. Developers should carefully read each vendor's terms of use and confirm whether the chosen aggregation service is an officially recognized partner or distributor.
Conclusion: Make Rational Choices Based on Actual Needs
Parallel multi-model usage has become the norm in AI development, and API aggregation gateways do have value as an engineering solution. However, developers should make rational choices based on their project's security level, performance requirements, and budget — rather than blindly following trends.
- Prototyping and non-sensitive scenarios: Aggregation solutions can significantly boost development efficiency and enable rapid validation of multi-model performance. At this stage, development speed and flexibility matter more than peak performance, and the convenience advantage of aggregation gateways is most pronounced.
- Production-grade core business: It's still recommended to retain the ability to connect directly to official APIs as a fallback, ensuring controllability of critical paths. A hybrid architecture of "primary routing through the aggregation gateway, backup routing directly to official APIs" can balance convenience and reliability.
In the long run, as industry standards gradually converge (OpenAI's API format has become the de facto standard, and more vendors are proactively adopting compatibility), the complexity of multi-model integration is expected to naturally decrease. But until standards are fully unified, aggregation gateways remain a pragmatic engineering choice.
There's no silver bullet in technology selection — the best solution is the one that fits your team.
Related articles
 Industry Insights
Industry InsightsAI Product Development in Practice: Model Selection, Building Moats, and Paths to Commercialization
Practical strategies for AI product development: why not to train models from scratch, when to use APIs vs. fine-tuning, building product moats, and the full path from evaluation systems to commercialization.
 Industry Insights
Industry InsightsNo Product Fits Your Needs? Building It Yourself Is the Best Starting Point for Indie Developers
Can't find a product that fits? Building from personal pain points is the best entry for indie developers. Niche needs + AI tools = rapid product creation.
 Industry Insights
Industry InsightsOpenAI Codex Tutorials Mass-Copied on Bilibili, Highlighting AI Content Farm Problem
At least 9 Bilibili accounts mass-published identical OpenAI Codex tutorial videos, exposing content farm operations in the AI tools space.