Claude 4.6 vs GPT-5.1 vs DeepSeek-R1: A Hands-On Comparison of Coding Capabilities

Claude 4.6 leads in coding benchmarks, GPT-5.1 balances cost and performance, DeepSeek-R1 wins on price.
This article compares three leading AI coding models — Claude Sonnet 4.6, GPT-5.1 Codex, and DeepSeek-R1 — across API pricing and SWE-Bench Verified performance. Claude Sonnet 4.6 tops the benchmark at 79.6%, GPT-5.1 Codex follows closely at 76.3%, while DeepSeek-R1 scores 49.2% but costs less than one-fifth the price. The guide helps developers choose the best model based on budget, use case, and deployment needs.
The Ultimate Showdown of Three Top Coding AI Models
The AI coding landscape has settled into a three-way race: Anthropic's Claude Sonnet 4.6, OpenAI's GPT-5.1 Codex, and China's reasoning powerhouse DeepSeek-R1. These three models represent the current pinnacle of AI-assisted programming, yet each has a distinctly different positioning and set of strengths.
This article provides a comprehensive breakdown of all three models across two core dimensions: API pricing and specifications, and real-world performance on the SWE-Bench Verified software engineering benchmark.

Specs & Pricing: How Big Is the Cost Gap?
Dramatic Differences in API Pricing
All three models support extra-long context windows, but their API pricing strategies vary enormously. Before diving into the numbers, it's worth understanding the core unit of measurement: a token. Tokens are the basic units that large language models use to process text — one token corresponds to roughly 3/4 of an English word, or 1–2 Chinese characters. In real-world coding scenarios, input token consumption far exceeds output because large amounts of code context must be passed to the model as input. For example, a mid-sized codebase might contain hundreds of thousands of lines of code, and a single comprehensive code review request could consume tens or even hundreds of thousands of tokens. This means differences in input pricing get amplified dramatically at scale in enterprise applications.
- DeepSeek-R1: Input price of just $0.55 per million tokens
- GPT-5.1 Codex: Input price of $1.25 per million tokens
- Claude Sonnet 4.6: Input price of $3 per million tokens
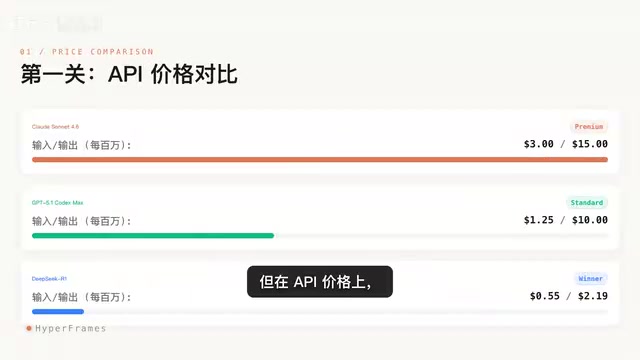
From a pricing perspective, DeepSeek-R1 saves over 80% compared to Claude Sonnet 4.6 and more than 56% compared to GPT-5.1 Codex. For enterprise applications requiring high-volume API calls, this price gap translates to order-of-magnitude cost differences.
Context Window: The Key Parameter That Defines a Model's "Field of Vision"
The context window refers to the maximum number of tokens a model can process in a single inference pass. For coding tasks, the context window size directly determines how much code the model can "see." Earlier models (like GPT-3.5) supported only a 4K-token context, meaning the model could handle roughly 200 lines of code and was virtually helpless when dealing with cross-file dependencies. All three current models support extra-long contexts (typically in the 128K–200K token range), enabling them to understand the complete code structure of an entire module or even a small project simultaneously. This has led to a quantum leap in performance for tasks like code completion, bug localization, and refactoring suggestions.
Cost-Effectiveness Analysis
For startups and individual developers, DeepSeek-R1's extreme cost-effectiveness is undeniably attractive. But price isn't the only factor — what truly determines productivity is how the model performs on real-world coding tasks.
In enterprise deployment scenarios, the cost calculation for an AI coding assistant goes far beyond API call fees. Other considerations include: Latency and throughput — response speed under high concurrency directly impacts developer experience; Data privacy — some enterprises require code to stay within their internal network, where DeepSeek-R1's open-source nature allows private deployment, while Claude and GPT primarily rely on cloud APIs; Model consistency — frequent model updates can cause output behavior changes that affect CI/CD pipeline stability. Therefore, the "best choice" often depends on a combination of factors including the company's specific tech stack, security compliance requirements, and team size.
SWE-Bench Verified: Real-World Capability Testing
What Is SWE-Bench?
SWE-Bench Verified is the industry's most widely recognized authoritative benchmark for measuring an AI model's ability to solve real GitHub software engineering problems. Introduced by a Princeton University research team in 2023, its core approach extracts real Issues and corresponding Pull Requests from 12 major Python open-source projects on GitHub (including Django, Flask, scikit-learn, sympy, and others). Each test case requires the model, given a problem description, to autonomously locate the files and lines of code that need modification and generate a patch that passes the project's existing test suite. The "Verified" version is a human-reviewed, high-quality subset that excludes cases with vague descriptions or insufficient tests, comprising 500 verified task instances. This evaluation approach based on real software engineering scenarios is far more reflective of a model's practical usability in development than traditional code completion benchmarks (like HumanEval, which only tests the correctness of standalone functions).
Resolution Rate Rankings
The results are striking:
| Model | SWE-Bench Verified Resolution Rate |
|---|---|
| Claude Sonnet 4.6 | 79.6% |
| GPT-5.1 Codex | 76.3% |
| DeepSeek-R1 | 49.2% |
Claude Sonnet 4.6 claims the top spot with a 79.6% resolution rate, showcasing Anthropic's deep expertise in code generation and engineering comprehension. GPT-5.1 Codex follows closely at 76.3%, with a gap of just 3.3 percentage points — an incredibly tight competition.
While DeepSeek-R1's 49.2% shows a notable gap from the top two, considering its price is less than one-fifth of the others, this performance is still commendable.
What's Behind the Gap: The Fundamental Difference Between Reasoning Models and Code-Specialized Models
The engineering capability lead of Claude Sonnet 4.6 and GPT-5.1 Codex likely stems from deep optimization on large-scale code repositories during training, as well as specialized reinforcement for software engineering workflows (such as code review, test-driven development, etc.).
DeepSeek-R1, as a general-purpose reasoning model, has its core strength in logical reasoning rather than specialized code engineering capabilities. Specifically, DeepSeek-R1 is a "reasoning-enhanced" model whose core design philosophy uses Chain-of-Thought mechanisms for multi-step logical reasoning, excelling at tasks like mathematical proofs and logical analysis. These models generate extensive intermediate thinking steps during inference, which improves reasoning accuracy but also increases token consumption. In contrast, Claude Sonnet 4.6 and GPT-5.1 Codex focus more on understanding software engineering paradigms — including design pattern recognition, API calling conventions, test case generation, and cross-file dependency analysis. This architectural difference explains why DeepSeek-R1 underperforms the other two on SWE-Bench (which demands precise code engineering skills), while potentially showing unique advantages on programming tasks involving algorithm design and logical derivation.
It's worth noting that Test-Driven Development (TDD) principles have been deeply integrated into the training and evaluation pipelines of AI coding models. SWE-Bench's evaluation criteria are essentially an embodiment of TDD philosophy — a model's generated code patch is only considered successful if it passes the preset test suite. The Claude and GPT model families were trained on massive amounts of repository data containing test code, enabling them to understand the engineering concept of "what constraints a code change should satisfy." This is also why, in practice, providing test cases as context to these models often significantly improves code generation accuracy.
Overall Ranking and Selection Guide

Final Rankings
- Claude Sonnet 4.6 — Best-in-class engineering development capability, ideal for professional teams pursuing code quality and complex project development
- GPT-5.1 Codex — Well-balanced overall performance, near-Claude capability at a better price point
- DeepSeek-R1 — Ultimate cost-effectiveness combined with strong reasoning ability, ideal for budget-constrained scenarios with high-volume needs
How to Choose for Different Scenarios?
- Ample budget, pursuing top code quality: Choose Claude Sonnet 4.6
- Balancing performance and cost: Choose GPT-5.1 Codex
- Cost-sensitive, high-volume usage: Choose DeepSeek-R1
- Complex logical reasoning + coding: DeepSeek-R1's chain-of-thought capability may offer unique advantages
- Data privacy and private deployment: DeepSeek-R1's open-source nature makes it the only option supporting fully localized deployment, which is particularly important for industries with strict data compliance requirements such as finance and healthcare
Conclusion
The AI coding space has entered a phase of intense competition. Claude Sonnet 4.6 currently leads in pure engineering capability, but GPT-5.1 Codex is hot on its heels, while DeepSeek-R1 delivers impressive coding ability at less than one-fifth the price, bringing a differentiated option to the market. For developers, there is no absolute "best" — only the choice that best fits your specific needs and budget.
As model iteration speeds continue to accelerate, this landscape could shift at any moment. We recommend that developers stay on top of updates from each provider and conduct small-scale A/B tests in real projects, using actual development efficiency data to guide their final technology selection decisions.
Related articles
AI Agent Core Architecture Breakdown: From Concept to Enterprise-Grade Intelligent Agent Development
Deep dive into AI Agent architecture: perception, brain, and action modules. Covers RAG memory systems, tool calling mechanisms, Chain of Thought reasoning, and enterprise agent development roadmap.
Hands-On Tutorial: Build an AI Agent from Scratch with 200 Lines of Python
Build an AI Agent from scratch with 200 lines of Python, covering prompts, memory, tool calling, RAG, and Skills — a practical guide for developers.
Anthropic Reverses Controversial Policy of Secretly Throttling AI Researchers Using Claude
Anthropic reverses its controversial policy of secretly throttling Claude Fable/Mythos responses to frontier LLM development requests after community backlash, raising critical questions about AI transparency.